 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Embeddings Inform Learning and Forgetting with Vision-Language Encoders
Jul 22, 2024Despite the proliferation of large vision-language foundation models, estimation of the learning and forgetting outcomes following fine-tuning of these models remains largely unexplored. Inspired by work highlighting the significance of the modality gap in contrastive dual-encoders, we propose the Inter-Intra Modal Measure (IIMM). Combining terms quantifying the similarity between image embeddings and the similarity between incorrect image and label embedding pairs, the IIMM functions as a strong predictor of performance changes with fine-tuning. Our extensive empirical analysis across four state-of-the-art vision-language models (CLIP, SigLIP, CoCa, EVA-02-CLIP) and five fine-tuning techniques (full fine-tuning, BitFit, attention-weight tuning, LoRA, CLIP-Adapter) demonstrates a strong, statistically significant linear relationship: fine-tuning on tasks with higher IIMM scores produces greater in-domain performance gains but also induces more severe out-of-domain performance degradation, with some parameter-efficient fine-tuning (PEFT) methods showing extreme forgetting. We compare our measure against transfer scores from state-of-the-art model selection methods and show that the IIMM is significantly more predictive of accuracy gains. With only a single forward pass of the target data, practitioners can leverage this key insight to heuristically evaluate the degree to which a model can be expected to improve following fine-tuning. Given additional knowledge about the model's performance on a few diverse tasks, this heuristic further evolves into a strong predictor of expected performance changes when training for new tasks.
Quantified Task Misalignment to Inform PEFT: An Exploration of Domain Generalization and Catastrophic Forgetting in CLIP
Feb 14, 2024Foundations models are presented as generalists that often perform well over a myriad of tasks. Fine-tuning these models, even on limited data, provides an additional boost in task-specific performance but often at the cost of their wider generalization, an effect termed catastrophic forgetting. In this paper, we analyze the relation between task difficulty in the CLIP model and the performance of several simple parameter-efficient fine-tuning methods through the lens of domain generalization and catastrophic forgetting. We provide evidence that the silhouette score of the zero-shot image and text embeddings is a better measure of task difficulty than the average cosine similarity of correct image/label embeddings, and discuss observable relationships between task difficulty, fine-tuning method, domain generalization, and catastrophic forgetting. Additionally, the averaged results across tasks and performance measures demonstrate that a simplified method that trains only a subset of attention weights, which we call A-CLIP, yields a balance between domain generalization and catastrophic forgetting.
Achieving Representative Data via Convex Hull Feasibility Sampling Algorithms
Apr 13, 2022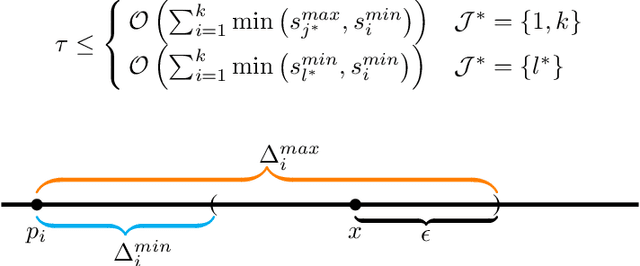


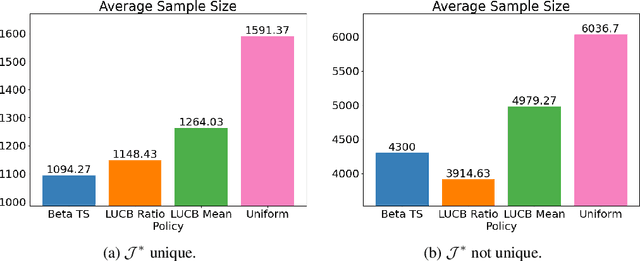
Sampling biases in training data are a major source of algorithmic biases in machine learning systems. Although there are many methods that attempt to mitigate such algorithmic biases during training, the most direct and obvious way is simply collecting more representative training data. In this paper, we consider the task of assembling a training dataset in which minority groups are adequately represented from a given set of data sources. In essence, this is an adaptive sampling problem to determine if a given point lies in the convex hull of the means from a set of unknown distributions. We present adaptive sampling methods to determine, with high confidence, whether it is possible to assemble a representative dataset from the given data sources. We also demonstrate the efficacy of our policies in simulations in the Bernoulli and a multinomial setting.
What You See May Not Be What You Get: UCB Bandit Algorithms Robust to ε-Contamination
Oct 12, 2019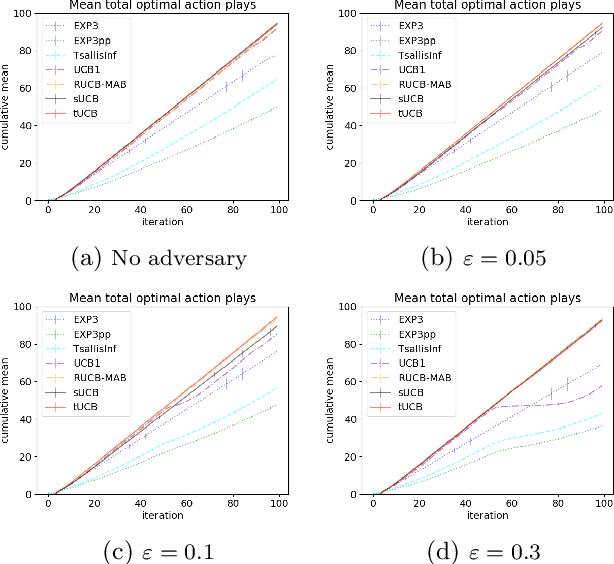
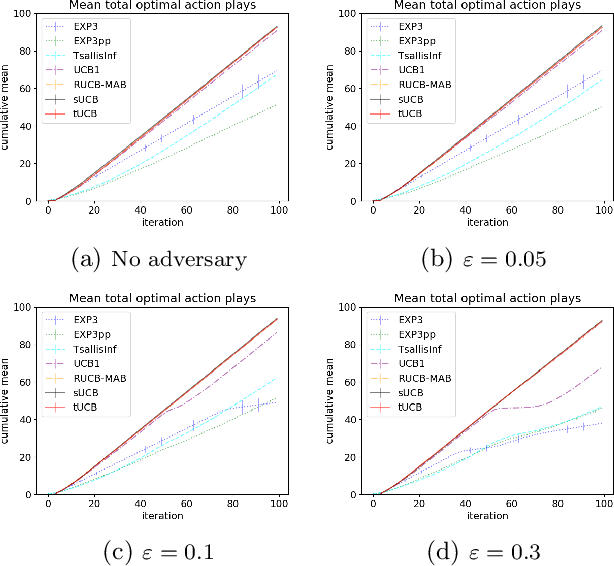
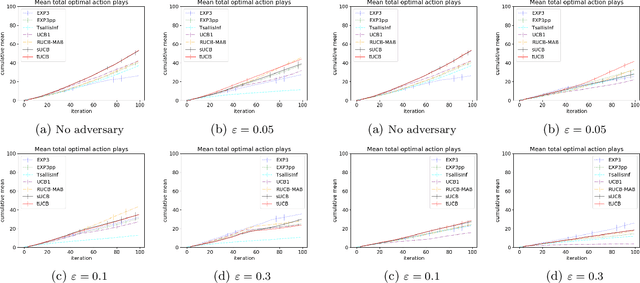
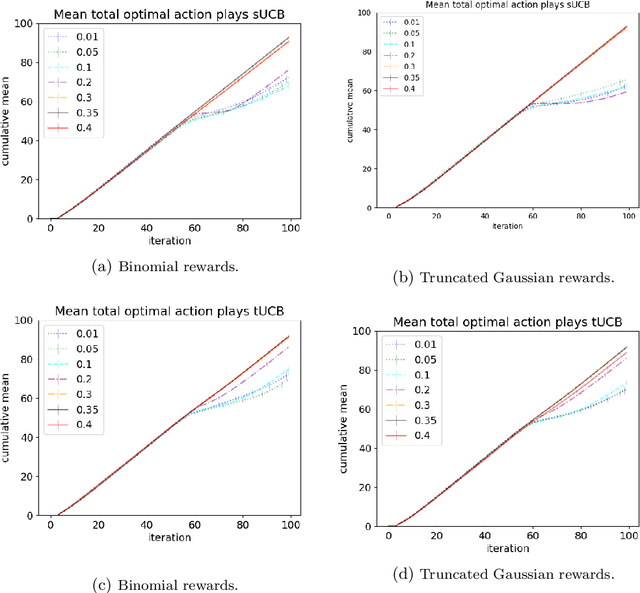
Motivated by applications of bandit algorithms in education, we consider a stochastic multi-armed bandit problem with $\varepsilon$-contaminated rewards. We allow an adversary to arbitrarily give unbounded contaminated rewards with full knowledge of the past and future. We impose only the constraint that at any time $t$ the proportion of contaminated rewards for any action is less than or equal to $\varepsilon$. We derive concentration inequalities for two robust mean estimators for sub-Gaussian distributions in the $\varepsilon$-contamination context. We define the $\varepsilon$-contaminated stochastic bandit problem and use our robust mean estimators to give two variants of a robust Upper Confidence Bound (UCB) algorithm, crUCB. Using regret derived from only the underlying stochastic rewards, both variants of crUCB achieve $\mathcal{O} (\sqrt{KT\log T})$ regret when $\varepsilon$ is small enough. Our simulations are designed to reflect reasonable settings a teacher would experience when implementing a bandit algorithm and thus use a limited horizon. We show that in certain adversarial regimes crUCB not only outperforms algorithms designed for stochastic (UCB1) and adversarial bandits (EXP3) but also those that have "best of both worlds" guarantees (EXP3++ and TsallisInf) even when our constraint on $\varepsilon$ is broken.
Fair Pipelines
Jul 03, 2017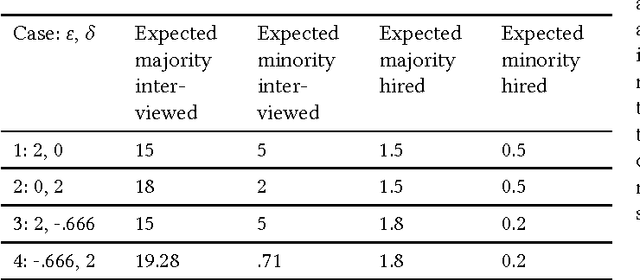
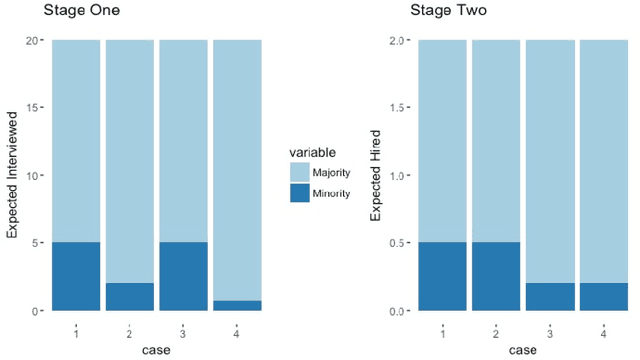
This work facilitates ensuring fairness of machine learning in the real world by decoupling fairness considerations in compound decisions. In particular, this work studies how fairness propagates through a compound decision-making processes, which we call a pipeline. Prior work in algorithmic fairness only focuses on fairness with respect to one decision. However, many decision-making processes require more than one decision. For instance, hiring is at least a two stage model: deciding who to interview from the applicant pool and then deciding who to hire from the interview pool. Perhaps surprisingly, we show that the composition of fair components may not guarantee a fair pipeline under a $(1+\varepsilon)$-equal opportunity definition of fair. However, we identify circumstances that do provide that guarantee. We also propose numerous directions for future work on more general compound machine learning decisions.