 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBound by the Bounty: Collaboratively Shaping Evaluation Processes for Queer AI Harms
Jul 25, 2023

Bias evaluation benchmarks and dataset and model documentation have emerged as central processes for assessing the biases and harms of artificial intelligence (AI) systems. However, these auditing processes have been criticized for their failure to integrate the knowledge of marginalized communities and consider the power dynamics between auditors and the communities. Consequently, modes of bias evaluation have been proposed that engage impacted communities in identifying and assessing the harms of AI systems (e.g., bias bounties). Even so, asking what marginalized communities want from such auditing processes has been neglected. In this paper, we ask queer communities for their positions on, and desires from, auditing processes. To this end, we organized a participatory workshop to critique and redesign bias bounties from queer perspectives. We found that when given space, the scope of feedback from workshop participants goes far beyond what bias bounties afford, with participants questioning the ownership, incentives, and efficacy of bounties. We conclude by advocating for community ownership of bounties and complementing bounties with participatory processes (e.g., co-creation).
* To appear at AIES 2023
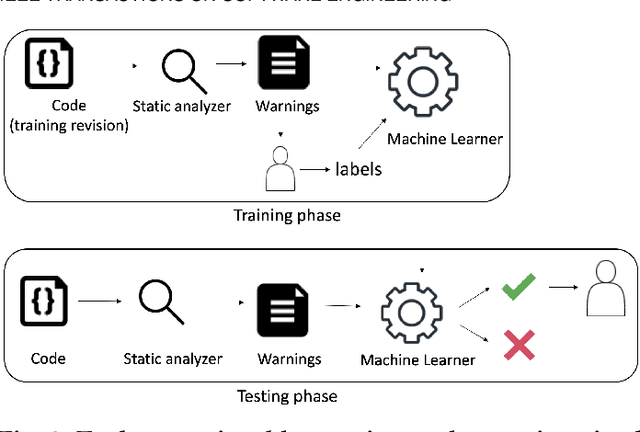
Less, but Stronger: On the Value of Strong Heuristics in Semi-supervised Learning for Software Analytics
Feb 03, 2023



In many domains, there are many examples and far fewer labels for those examples; e.g. we may have access to millions of lines of source code, but access to only a handful of warnings about that code. In those domains, semi-supervised learners (SSL) can extrapolate labels from a small number of examples to the rest of the data. Standard SSL algorithms use ``weak'' knowledge (i.e. those not based on specific SE knowledge) such as (e.g.) co-train two learners and use good labels from one to train the other. Another approach of SSL in software analytics is potentially use ``strong'' knowledge that use SE knowledge. For example, an often-used heuristic in SE is that unusually large artifacts contain undesired properties (e.g. more bugs). This paper argues that such ``strong'' algorithms perform better than those standard, weaker, SSL algorithms. We show this by learning models from labels generated using weak SSL or our ``stronger'' FRUGAL algorithm. In four domains (distinguishing security-related bug reports; mitigating bias in decision-making; predicting issue close time; and (reducing false alarms in static code warnings), FRUGAL required only 2.5% of the data to be labeled yet out-performed standard semi-supervised learners that relied on (e.g.) some domain-independent graph theory concepts. Hence, for future work, we strongly recommend the use of strong heuristics for semi-supervised learning for SE applications. To better support other researchers, our scripts and data are on-line at https://github.com/HuyTu7/FRUGAL.
How to Find Actionable Static Analysis Warnings
May 21, 2022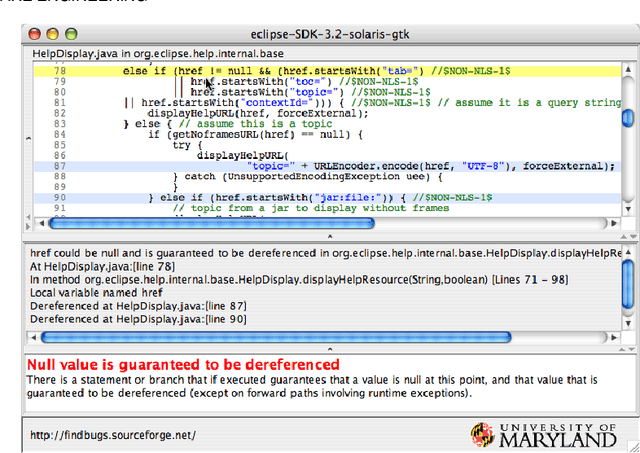

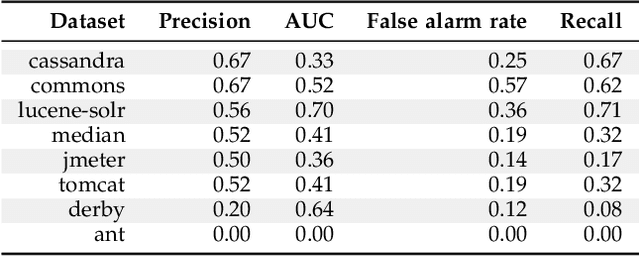
Automatically generated static code warnings suffer from a large number of false alarms. Hence, developers only take action on a small percent of those warnings. To better predict which static code warnings should not be ignored, we suggest that analysts need to look deeper into their algorithms to find choices that better improve the particulars of their specific problem. Specifically, we show here that effective predictors of such warnings can be created by methods that locally adjust the decision boundary (between actionable warnings and others). These methods yield a new high water-mark for recognizing actionable static code warnings. For eight open-source Java projects (CASSANDRA, JMETER, COMMONS, LUCENE-SOLR, ANT, TOMCAT, DERBY) we achieve perfect test results on 4/8 datasets and, overall, a median AUC (area under the true negatives, true positives curve) of 92\%.
DebtFree: Minimizing Labeling Cost in Self-Admitted Technical Debt Identification using Semi-Supervised Learning
Jan 25, 2022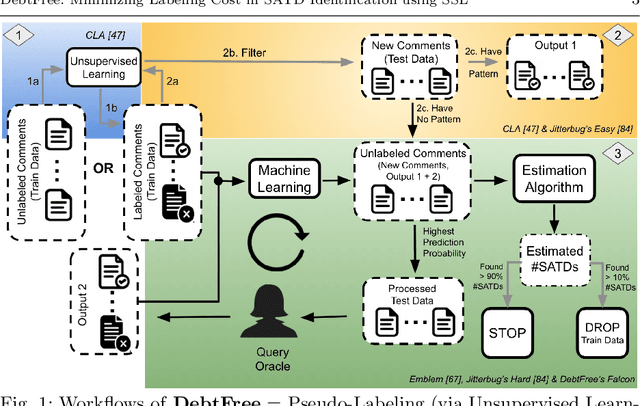

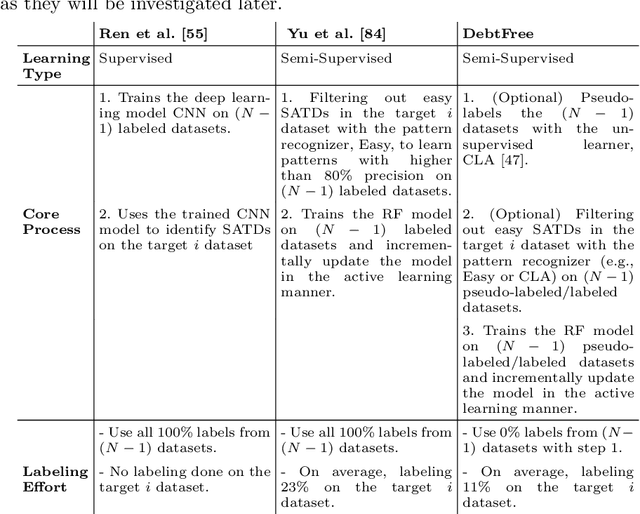
Keeping track of and managing Self-Admitted Technical Debts (SATDs) is important for maintaining a healthy software project. Current active-learning SATD recognition tool involves manual inspection of 24% of the test comments on average to reach 90% of the recall. Among all the test comments, about 5% are SATDs. The human experts are then required to read almost a quintuple of the SATD comments which indicates the inefficiency of the tool. Plus, human experts are still prone to error: 95% of the false-positive labels from previous work were actually true positives. To solve the above problems, we propose DebtFree, a two-mode framework based on unsupervised learning for identifying SATDs. In mode1, when the existing training data is unlabeled, DebtFree starts with an unsupervised learner to automatically pseudo-label the programming comments in the training data. In contrast, in mode2 where labels are available with the corresponding training data, DebtFree starts with a pre-processor that identifies the highly prone SATDs from the test dataset. Then, our machine learning model is employed to assist human experts in manually identifying the remaining SATDs. Our experiments on 10 software projects show that both models yield a statistically significant improvement in effectiveness over the state-of-the-art automated and semi-automated models. Specifically, DebtFree can reduce the labeling effort by 99% in mode1 (unlabeled training data), and up to 63% in mode2 (labeled training data) while improving the current active learner's F1 relatively to almost 100%.
Can We Achieve Fairness Using Semi-Supervised Learning?
Nov 25, 2021
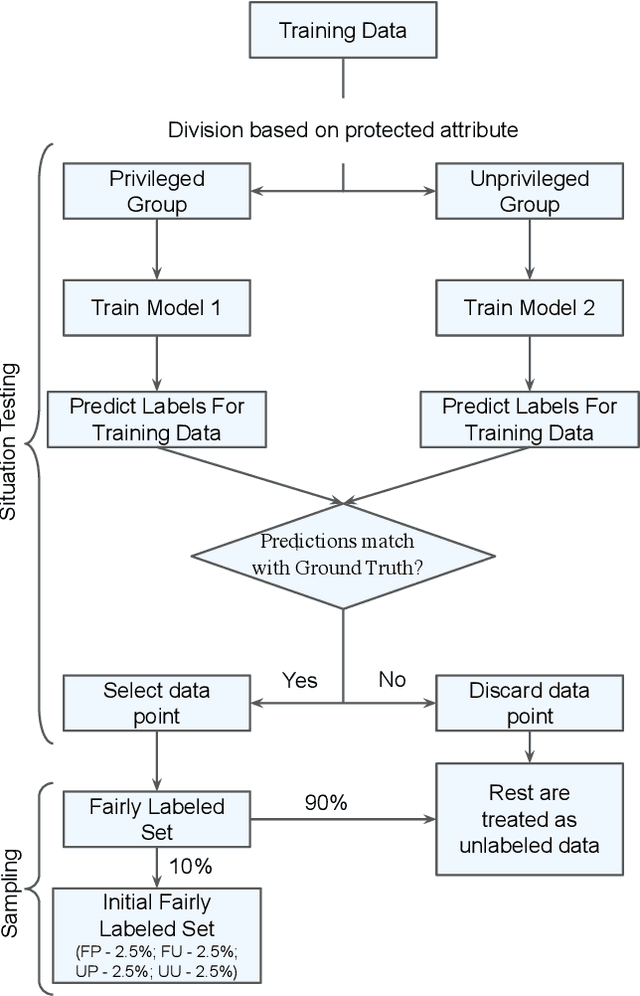

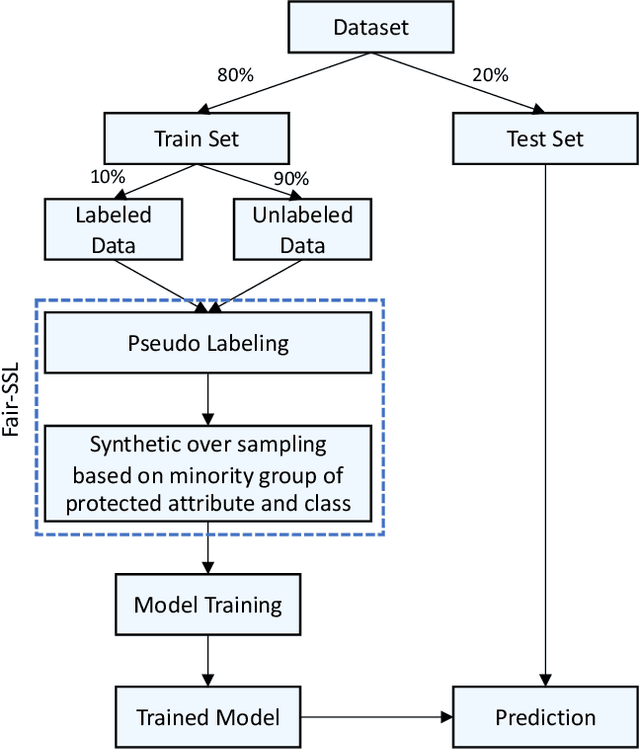
Ethical bias in machine learning models has become a matter of concern in the software engineering community. Most of the prior software engineering works concentrated on finding ethical bias in models rather than fixing it. After finding bias, the next step is mitigation. Prior researchers mainly tried to use supervised approaches to achieve fairness. However, in the real world, getting data with trustworthy ground truth is challenging and also ground truth can contain human bias. Semi-supervised learning is a machine learning technique where, incrementally, labeled data is used to generate pseudo-labels for the rest of the data (and then all that data is used for model training). In this work, we apply four popular semi-supervised techniques as pseudo-labelers to create fair classification models. Our framework, Fair-SSL, takes a very small amount (10%) of labeled data as input and generates pseudo-labels for the unlabeled data. We then synthetically generate new data points to balance the training data based on class and protected attribute as proposed by Chakraborty et al. in FSE 2021. Finally, the classification model is trained on the balanced pseudo-labeled data and validated on test data. After experimenting on ten datasets and three learners, we find that Fair-SSL achieves similar performance as three state-of-the-art bias mitigation algorithms. That said, the clear advantage of Fair-SSL is that it requires only 10% of the labeled training data. To the best of our knowledge, this is the first SE work where semi-supervised techniques are used to fight against ethical bias in SE ML models.
FRUGAL: Unlocking SSL for Software Analytics
Aug 22, 2021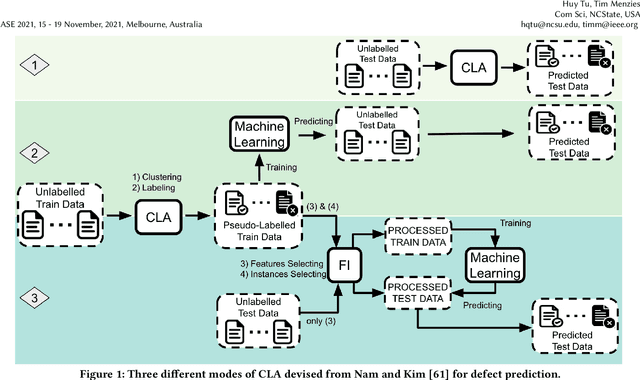
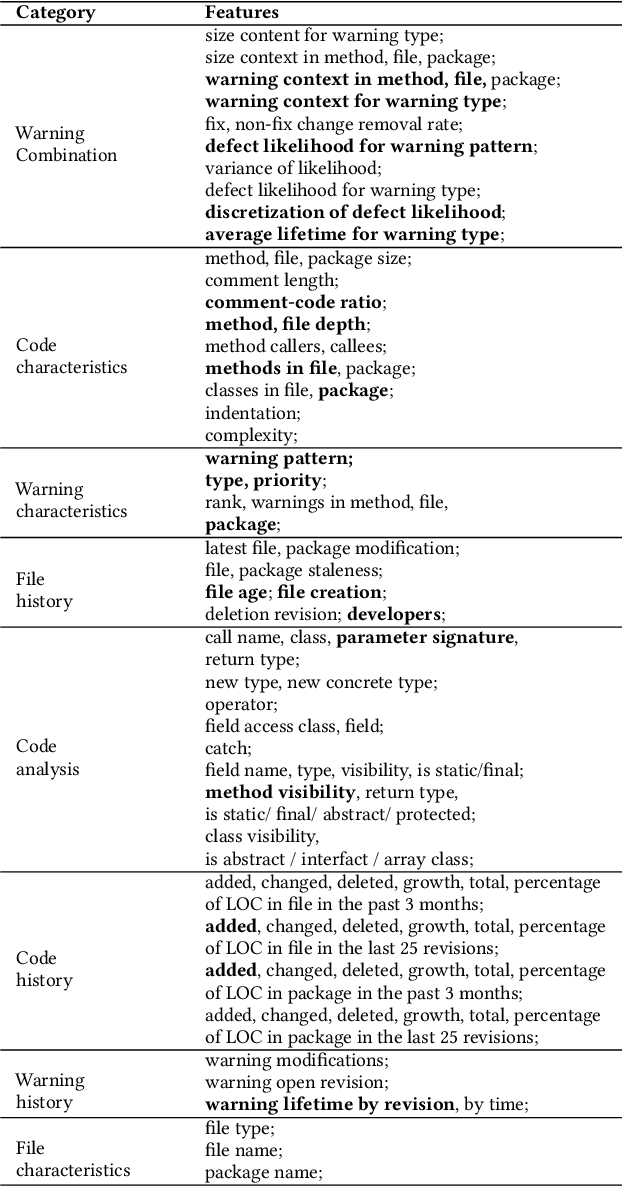


Standard software analytics often involves having a large amount of data with labels in order to commission models with acceptable performance. However, prior work has shown that such requirements can be expensive, taking several weeks to label thousands of commits, and not always available when traversing new research problems and domains. Unsupervised Learning is a promising direction to learn hidden patterns within unlabelled data, which has only been extensively studied in defect prediction. Nevertheless, unsupervised learning can be ineffective by itself and has not been explored in other domains (e.g., static analysis and issue close time). Motivated by this literature gap and technical limitations, we present FRUGAL, a tuned semi-supervised method that builds on a simple optimization scheme that does not require sophisticated (e.g., deep learners) and expensive (e.g., 100% manually labelled data) methods. FRUGAL optimizes the unsupervised learner's configurations (via a simple grid search) while validating our design decision of labelling just 2.5% of the data before prediction. As shown by the experiments of this paper FRUGAL outperforms the state-of-the-art adoptable static code warning recognizer and issue closed time predictor, while reducing the cost of labelling by a factor of 40 (from 100% to 2.5%). Hence we assert that FRUGAL can save considerable effort in data labelling especially in validating prior work or researching new problems. Based on this work, we suggest that proponents of complex and expensive methods should always baseline such methods against simpler and cheaper alternatives. For instance, a semi-supervised learner like FRUGAL can serve as a baseline to the state-of-the-art software analytics.
Is One Hyperparameter Optimizer Enough?
Oct 02, 2018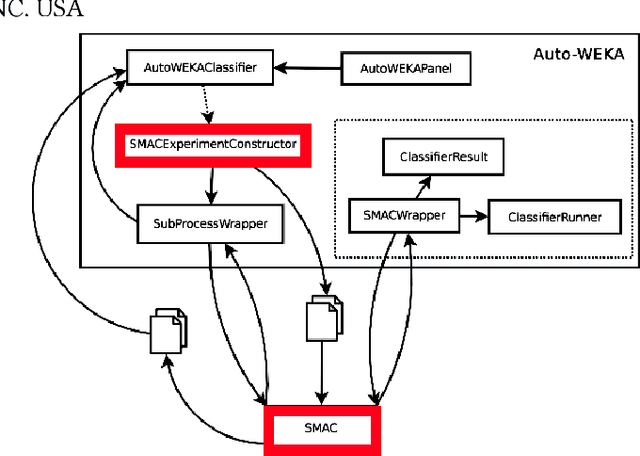
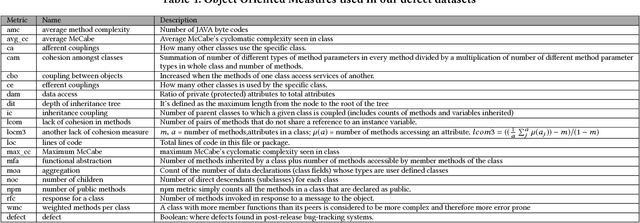
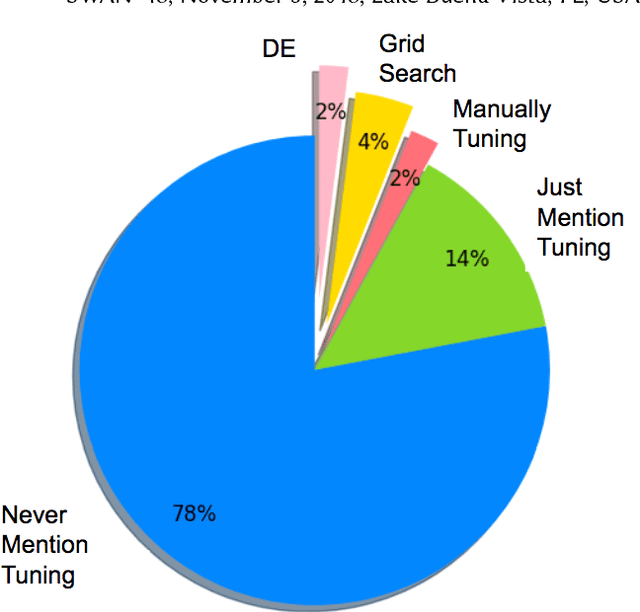
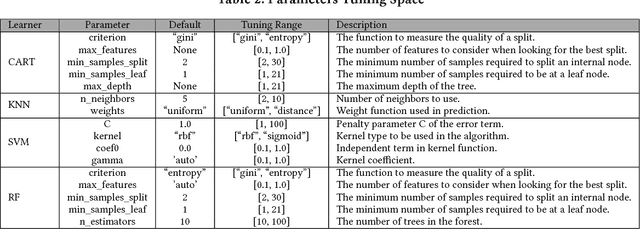
Hyperparameter tuning is the black art of automatically finding a good combination of control parameters for a data miner. While widely applied in empirical Software Engineering, there has not been much discussion on which hyperparameter tuner is best for software analytics. To address this gap in the literature, this paper applied a range of hyperparameter optimizers (grid search, random search, differential evolution, and Bayesian optimization) to defect prediction problem. Surprisingly, no hyperparameter optimizer was observed to be `best' and, for one of the two evaluation measures studied here (F-measure), hyperparameter optimization, in 50\% cases, was no better than using default configurations. We conclude that hyperparameter optimization is more nuanced than previously believed. While such optimization can certainly lead to large improvements in the performance of classifiers used in software analytics, it remains to be seen which specific optimizers should be applied to a new dataset.