 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnique Identification of 50,000+ Virtual Reality Users from Head & Hand Motion Data
Feb 17, 2023



With the recent explosive growth of interest and investment in virtual reality (VR) and the so-called "metaverse," public attention has rightly shifted toward the unique security and privacy threats that these platforms may pose. While it has long been known that people reveal information about themselves via their motion, the extent to which this makes an individual globally identifiable within virtual reality has not yet been widely understood. In this study, we show that a large number of real VR users (N=55,541) can be uniquely and reliably identified across multiple sessions using just their head and hand motion relative to virtual objects. After training a classification model on 5 minutes of data per person, a user can be uniquely identified amongst the entire pool of 50,000+ with 94.33% accuracy from 100 seconds of motion, and with 73.20% accuracy from just 10 seconds of motion. This work is the first to truly demonstrate the extent to which biomechanics may serve as a unique identifier in VR, on par with widely used biometrics such as facial or fingerprint recognition.
Learning to Learn to Predict Performance Regressions in Production at Meta
Aug 08, 2022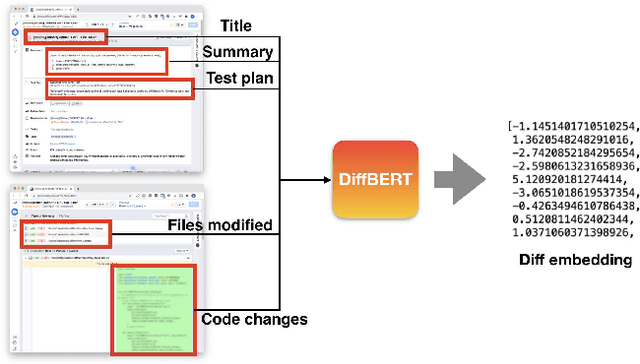
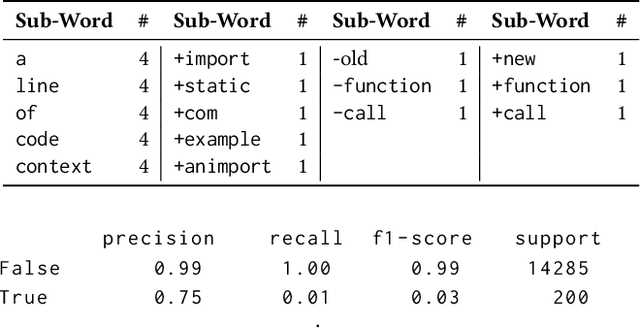
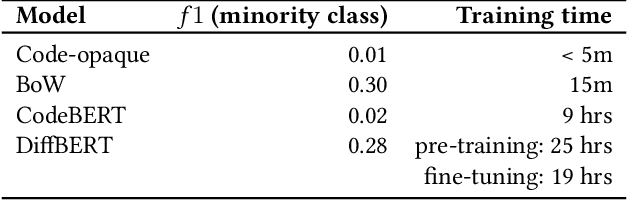
Catching and attributing code change-induced performance regressions in production is hard; predicting them beforehand, even harder. A primer on automatically learning to predict performance regressions in software, this article gives an account of the experiences we gained when researching and deploying an ML-based regression prediction pipeline at Meta. In this paper, we report on a comparative study with four ML models of increasing complexity, from (1) code-opaque, over (2) Bag of Words, (3) off-the-shelve Transformer-based, to (4) a bespoke Transformer-based model, coined SuperPerforator. Our investigation shows the inherent difficulty of the performance prediction problem, which is characterized by a large imbalance of benign onto regressing changes. Our results also call into question the general applicability of Transformer-based architectures for performance prediction: an off-the-shelve CodeBERT-based approach had surprisingly poor performance; our highly customized SuperPerforator architecture initially achieved prediction performance that was just on par with simpler Bag of Words models, and only outperformed them for down-stream use cases. This ability of SuperPerforator to transfer to an application with few learning examples afforded an opportunity to deploy it in practice at Meta: it can act as a pre-filter to sort out changes that are unlikely to introduce a regression, truncating the space of changes to search a regression in by up to 43%, a 45x improvement over a random baseline. To gain further insight into SuperPerforator, we explored it via a series of experiments computing counterfactual explanations. These highlight which parts of a code change the model deems important, thereby validating the learned black-box model.
Is One Hyperparameter Optimizer Enough?
Oct 02, 2018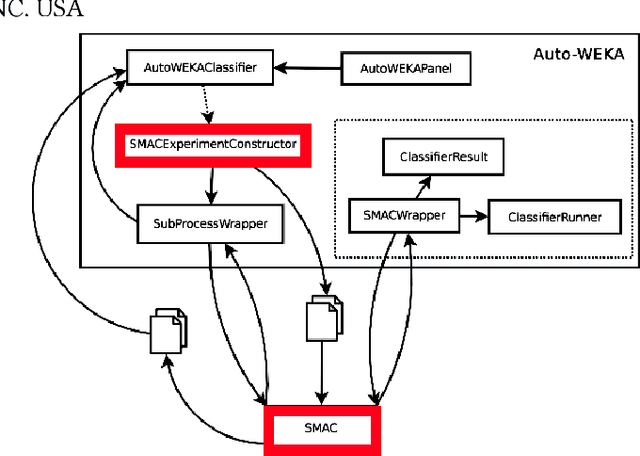
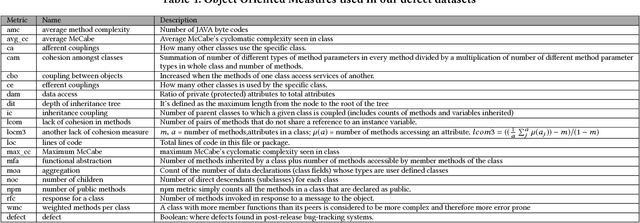
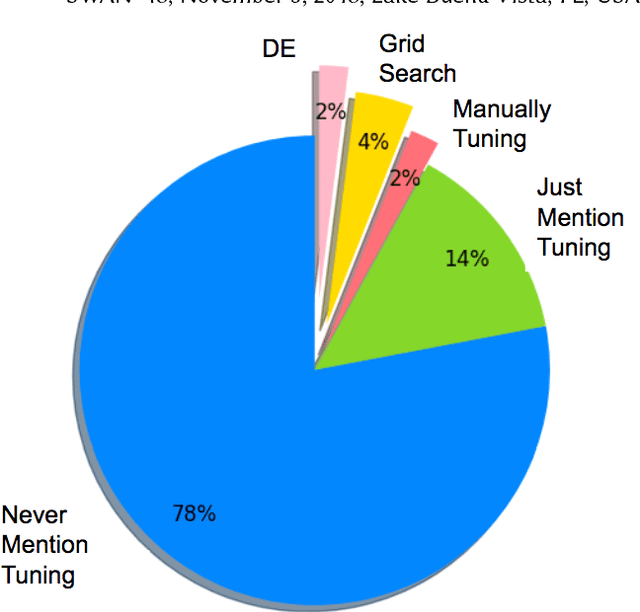
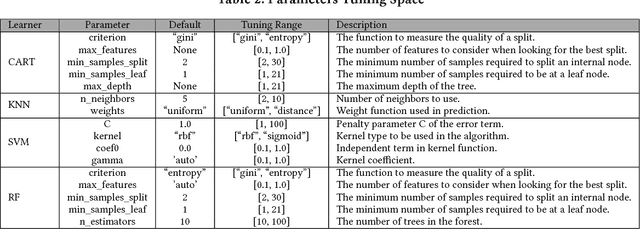
Hyperparameter tuning is the black art of automatically finding a good combination of control parameters for a data miner. While widely applied in empirical Software Engineering, there has not been much discussion on which hyperparameter tuner is best for software analytics. To address this gap in the literature, this paper applied a range of hyperparameter optimizers (grid search, random search, differential evolution, and Bayesian optimization) to defect prediction problem. Surprisingly, no hyperparameter optimizer was observed to be `best' and, for one of the two evaluation measures studied here (F-measure), hyperparameter optimization, in 50\% cases, was no better than using default configurations. We conclude that hyperparameter optimization is more nuanced than previously believed. While such optimization can certainly lead to large improvements in the performance of classifiers used in software analytics, it remains to be seen which specific optimizers should be applied to a new dataset.
Beyond Evolutionary Algorithms for Search-based Software Engineering
Sep 17, 2017


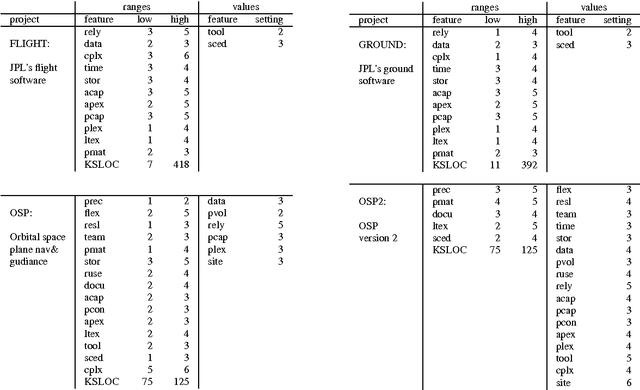
Context: Evolutionary algorithms typically require a large number of evaluations (of solutions) to converge - which can be very slow and expensive to evaluate.Objective: To solve search-based software engineering (SE) problems, using fewer evaluations than evolutionary methods.Method: Instead of mutating a small population, we build a very large initial population which is then culled using a recursive bi-clustering chop approach. We evaluate this approach on multiple SE models, unconstrained as well as constrained, and compare its performance with standard evolutionary algorithms. Results: Using just a few evaluations (under 100), we can obtain comparable results to state-of-the-art evolutionary algorithms.Conclusion: Just because something works, and is widespread use, does not necessarily mean that there is no value in seeking methods to improve that method. Before undertaking search-based SE optimization tasks using traditional EAs, it is recommended to try other techniques, like those explored here, to obtain the same results with fewer evaluations.
Faster Discovery of Faster System Configurations with Spectral Learning
Aug 03, 2017

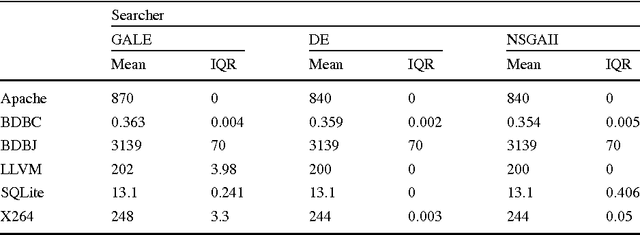

Despite the huge spread and economical importance of configurable software systems, there is unsatisfactory support in utilizing the full potential of these systems with respect to finding performance-optimal configurations. Prior work on predicting the performance of software configurations suffered from either (a) requiring far too many sample configurations or (b) large variances in their predictions. Both these problems can be avoided using the WHAT spectral learner. WHAT's innovation is the use of the spectrum (eigenvalues) of the distance matrix between the configurations of a configurable software system, to perform dimensionality reduction. Within that reduced configuration space, many closely associated configurations can be studied by executing only a few sample configurations. For the subject systems studied here, a few dozen samples yield accurate and stable predictors - less than 10% prediction error, with a standard deviation of less than 2%. When compared to the state of the art, WHAT (a) requires 2 to 10 times fewer samples to achieve similar prediction accuracies, and (b) its predictions are more stable (i.e., have lower standard deviation). Furthermore, we demonstrate that predictive models generated by WHAT can be used by optimizers to discover system configurations that closely approach the optimal performance.
Why is Differential Evolution Better than Grid Search for Tuning Defect Predictors?
Mar 10, 2017



Context: One of the black arts of data mining is learning the magic parameters which control the learners. In software analytics, at least for defect prediction, several methods, like grid search and differential evolution (DE), have been proposed to learn these parameters, which has been proved to be able to improve the performance scores of learners. Objective: We want to evaluate which method can find better parameters in terms of performance score and runtime cost. Methods: This paper compares grid search to differential evolution, which is an evolutionary algorithm that makes extensive use of stochastic jumps around the search space. Results: We find that the seemingly complete approach of grid search does no better, and sometimes worse, than the stochastic search. When repeated 20 times to check for conclusion validity, DE was over 210 times faster than grid search to tune Random Forests on 17 testing data sets with F-Measure Conclusions: These results are puzzling: why does a quick partial search be just as effective as a much slower, and much more, extensive search? To answer that question, we turned to the theoretical optimization literature. Bergstra and Bengio conjecture that grid search is not more effective than more randomized searchers if the underlying search space is inherently low dimensional. This is significant since recent results show that defect prediction exhibits very low intrinsic dimensionality-- an observation that explains why a fast method like DE may work as well as a seemingly more thorough grid search. This suggests, as a future research direction, that it might be possible to peek at data sets before doing any optimization in order to match the optimization algorithm to the problem at hand.