 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePragmatic Reasoning improves LLM Code Generation
Feb 28, 2025Large Language Models (LLMs) have demonstrated impressive potential in translating natural language (NL) instructions into program code. However, user instructions often contain inherent ambiguities, making it challenging for LLMs to generate code that accurately reflects the user's true intent. To address this challenge, researchers have proposed to produce multiple candidates of the program code and then rerank them to identify the best solution. In this paper, we propose CodeRSA, a novel code candidate reranking mechanism built upon the Rational Speech Act (RSA) framework, designed to guide LLMs toward more comprehensive pragmatic reasoning about user intent. We evaluate CodeRSA using one of the latest LLMs on a popular code generation dataset. Our experiment results show that CodeRSA consistently outperforms common baselines, surpasses the state-of-the-art approach in most cases, and demonstrates robust overall performance. These findings underscore the effectiveness of integrating pragmatic reasoning into code candidate reranking, offering a promising direction for enhancing code generation quality in LLMs.
Leveraging Large Language Models for Software Model Completion: Results from Industrial and Public Datasets
Jun 25, 2024Modeling structure and behavior of software systems plays a crucial role in the industrial practice of software engineering. As with other software engineering artifacts, software models are subject to evolution. Supporting modelers in evolving software models with recommendations for model completions is still an open problem, though. In this paper, we explore the potential of large language models for this task. In particular, we propose an approach, retrieval-augmented generation, leveraging large language models, model histories, and retrieval-augmented generation for model completion. Through experiments on three datasets, including an industrial application, one public open-source community dataset, and one controlled collection of simulated model repositories, we evaluate the potential of large language models for model completion with retrieval-augmented generation. We found that large language models are indeed a promising technology for supporting software model evolution (62.30% semantically correct completions on real-world industrial data and up to 86.19% type-correct completions). The general inference capabilities of large language models are particularly useful when dealing with concepts for which there are few, noisy, or no examples at all.
Towards Automatic Support of Software Model Evolution with Large Language~Models
Dec 19, 2023Modeling structure and behavior of software systems plays a crucial role, in various areas of software engineering. As with other software engineering artifacts, software models are subject to evolution. Supporting modelers in evolving models by model completion facilities and providing high-level edit operations such as frequently occurring editing patterns is still an open problem. Recently, large language models (i.e., generative neural networks) have garnered significant attention in various research areas, including software engineering. In this paper, we explore the potential of large language models in supporting the evolution of software models in software engineering. We propose an approach that utilizes large language models for model completion and discovering editing patterns in model histories of software systems. Through controlled experiments using simulated model repositories, we conduct an evaluation of the potential of large language models for these two tasks. We have found that large language models are indeed a promising technology for supporting software model evolution, and that it is worth investigating further in the area of software model evolution.
Feature Interactions on Steroids: On the Composition of ML Models
May 13, 2021


The lack of specifications is a key difference between traditional software engineering and machine learning. We discuss how it drastically impacts how we think about divide-and-conquer approaches to system design, and how it impacts reuse, testing and debugging activities. Traditionally, specifications provide a cornerstone for compositional reasoning and for the divide-and-conquer strategy of how we build large and complex systems from components, but those are hard to come by for machine-learned components. While the lack of specification seems like a fundamental new problem at first sight, in fact software engineers routinely deal with iffy specifications in practice: we face weak specifications, wrong specifications, and unanticipated interactions among components and their specifications. Machine learning may push us further, but the problems are not fundamentally new. Rethinking machine-learning model composition from the perspective of the feature interaction problem, we may even teach us a thing or two on how to move forward, including the importance of integration testing, of requirements engineering, and of design.
Predicting Performance of Software Configurations: There is no Silver Bullet
Nov 28, 2019
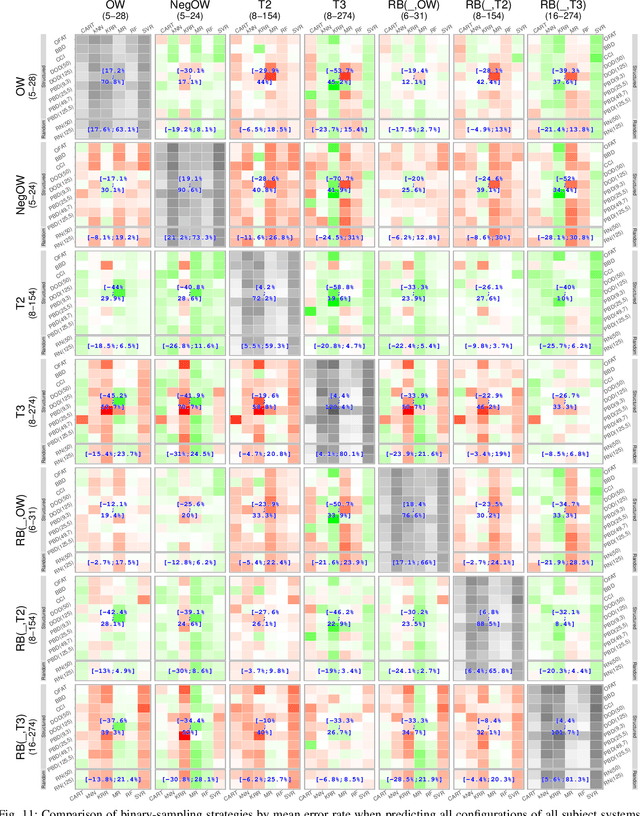
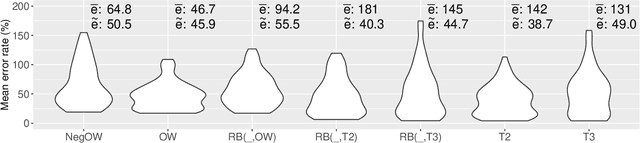
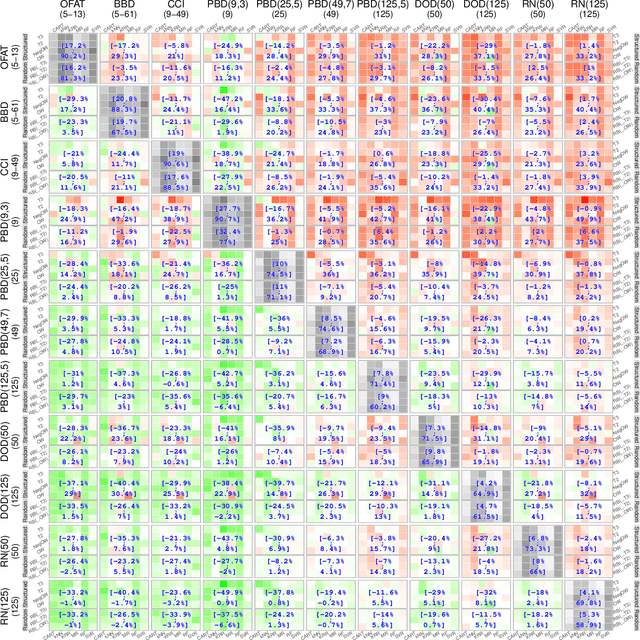
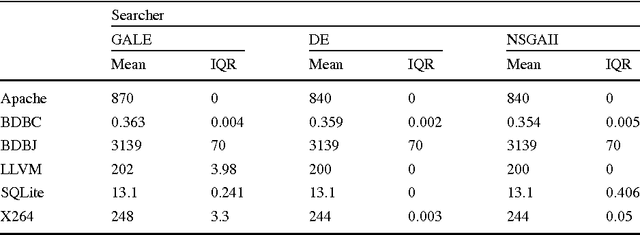
Many software systems offer configuration options to tailor their functionality and non-functional properties (e.g., performance). Often, users are interested in the (performance-)optimal configuration, but struggle to find it, due to missing information on influences of individual configuration options and their interactions. In the past, various supervised machine-learning techniques have been used to predict the performance of all configurations and to identify the optimal one. In the literature, there is a large number of machine-learning techniques and sampling strategies to select from. It is unclear, though, to what extent they affect prediction accuracy. We have conducted a comparative study regarding the mean prediction accuracy when predicting the performance of all configurations considering 6 machine-learning techniques, 18 sampling strategies, and 6 subject software systems. We found that both the learning technique and the sampling strategy have a strong influence on prediction accuracy. We further observed that some learning techniques (e.g., random forests) outperform other learning techniques (e.g., k-nearest neighbor) in most cases. Moreover, as the prediction accuracy strongly depends on the subject system, there is no combination of a learning technique and sampling strategy that is optimal in all cases, considering the tradeoff between accuracy and measurement overhead, which is in line with the famous no-free-lunch theorem.
Faster Discovery of Faster System Configurations with Spectral Learning
Aug 03, 2017


Despite the huge spread and economical importance of configurable software systems, there is unsatisfactory support in utilizing the full potential of these systems with respect to finding performance-optimal configurations. Prior work on predicting the performance of software configurations suffered from either (a) requiring far too many sample configurations or (b) large variances in their predictions. Both these problems can be avoided using the WHAT spectral learner. WHAT's innovation is the use of the spectrum (eigenvalues) of the distance matrix between the configurations of a configurable software system, to perform dimensionality reduction. Within that reduced configuration space, many closely associated configurations can be studied by executing only a few sample configurations. For the subject systems studied here, a few dozen samples yield accurate and stable predictors - less than 10% prediction error, with a standard deviation of less than 2%. When compared to the state of the art, WHAT (a) requires 2 to 10 times fewer samples to achieve similar prediction accuracies, and (b) its predictions are more stable (i.e., have lower standard deviation). Furthermore, we demonstrate that predictive models generated by WHAT can be used by optimizers to discover system configurations that closely approach the optimal performance.