 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Performance of Software Configurations: There is no Silver Bullet
Nov 28, 2019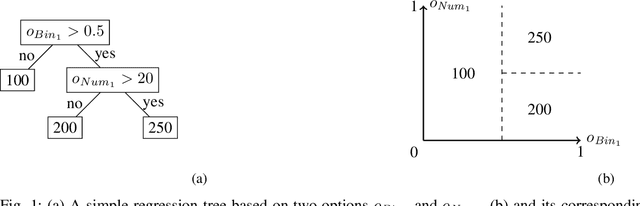
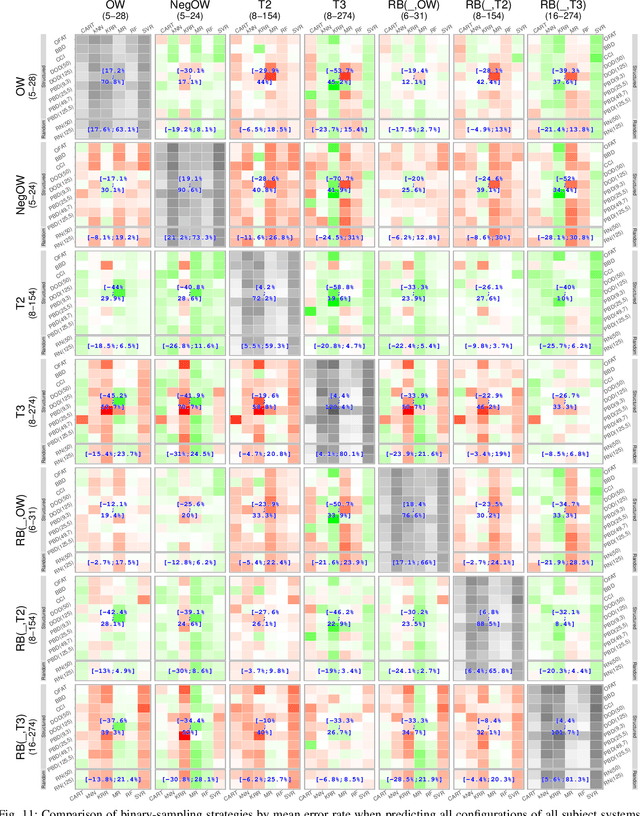
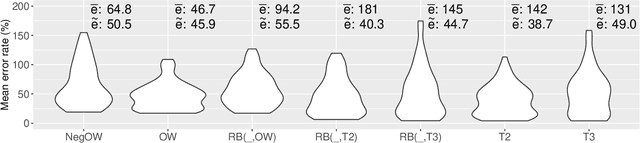
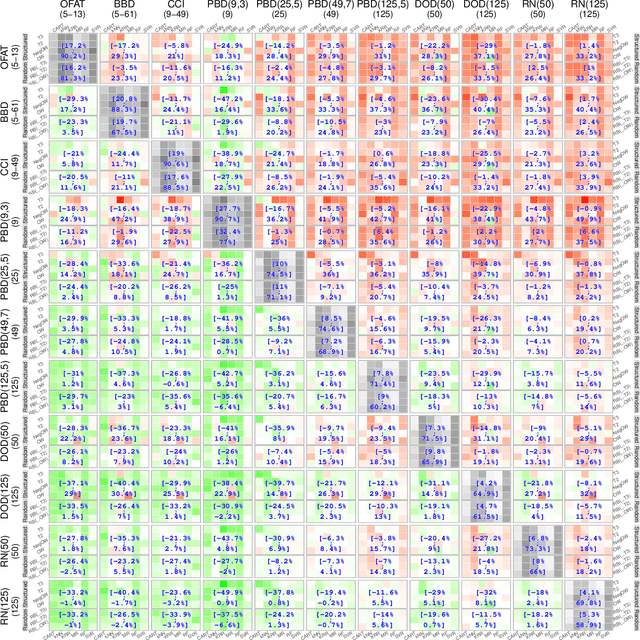
Many software systems offer configuration options to tailor their functionality and non-functional properties (e.g., performance). Often, users are interested in the (performance-)optimal configuration, but struggle to find it, due to missing information on influences of individual configuration options and their interactions. In the past, various supervised machine-learning techniques have been used to predict the performance of all configurations and to identify the optimal one. In the literature, there is a large number of machine-learning techniques and sampling strategies to select from. It is unclear, though, to what extent they affect prediction accuracy. We have conducted a comparative study regarding the mean prediction accuracy when predicting the performance of all configurations considering 6 machine-learning techniques, 18 sampling strategies, and 6 subject software systems. We found that both the learning technique and the sampling strategy have a strong influence on prediction accuracy. We further observed that some learning techniques (e.g., random forests) outperform other learning techniques (e.g., k-nearest neighbor) in most cases. Moreover, as the prediction accuracy strongly depends on the subject system, there is no combination of a learning technique and sampling strategy that is optimal in all cases, considering the tradeoff between accuracy and measurement overhead, which is in line with the famous no-free-lunch theorem.