 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Methodology for Evaluating RAG Systems: A Case Study On Configuration Dependency Validation
Oct 11, 2024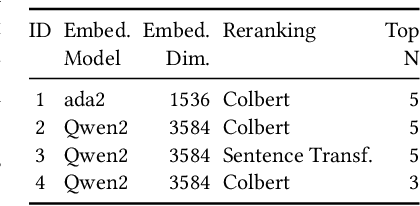

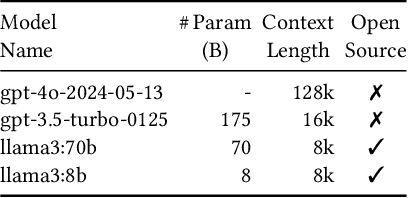

Retrieval-augmented generation (RAG) is an umbrella of different components, design decisions, and domain-specific adaptations to enhance the capabilities of large language models and counter their limitations regarding hallucination and outdated and missing knowledge. Since it is unclear which design decisions lead to a satisfactory performance, developing RAG systems is often experimental and needs to follow a systematic and sound methodology to gain sound and reliable results. However, there is currently no generally accepted methodology for RAG evaluation despite a growing interest in this technology. In this paper, we propose a first blueprint of a methodology for a sound and reliable evaluation of RAG systems and demonstrate its applicability on a real-world software engineering research task: the validation of configuration dependencies across software technologies. In summary, we make two novel contributions: (i) A novel, reusable methodological design for evaluating RAG systems, including a demonstration that represents a guideline, and (ii) a RAG system, which has been developed following this methodology, that achieves the highest accuracy in the field of dependency validation. For the blueprint's demonstration, the key insights are the crucial role of choosing appropriate baselines and metrics, the necessity for systematic RAG refinements derived from qualitative failure analysis, as well as the reporting practices of key design decision to foster replication and evaluation.
Predicting Performance of Software Configurations: There is no Silver Bullet
Nov 28, 2019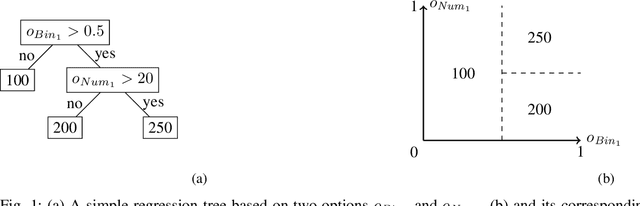
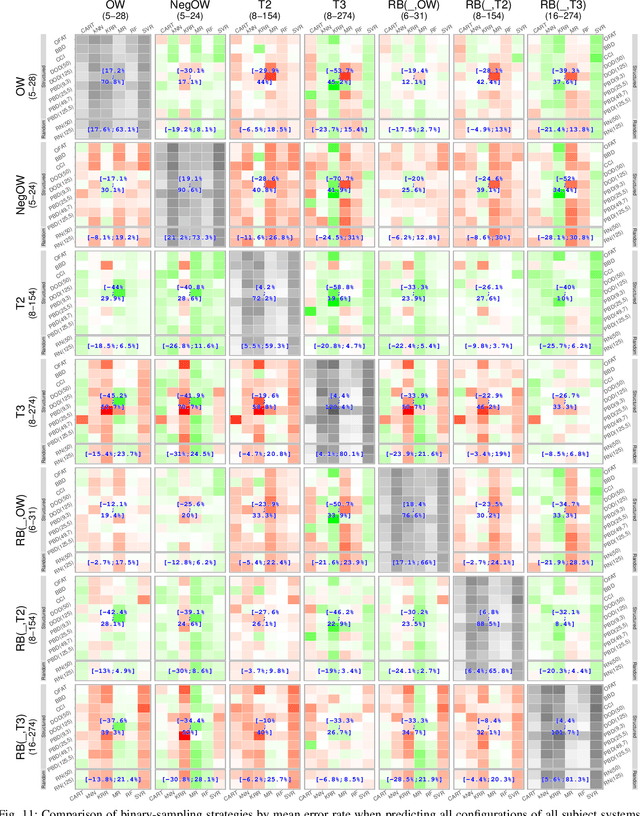
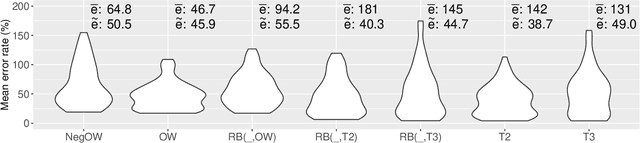
Many software systems offer configuration options to tailor their functionality and non-functional properties (e.g., performance). Often, users are interested in the (performance-)optimal configuration, but struggle to find it, due to missing information on influences of individual configuration options and their interactions. In the past, various supervised machine-learning techniques have been used to predict the performance of all configurations and to identify the optimal one. In the literature, there is a large number of machine-learning techniques and sampling strategies to select from. It is unclear, though, to what extent they affect prediction accuracy. We have conducted a comparative study regarding the mean prediction accuracy when predicting the performance of all configurations considering 6 machine-learning techniques, 18 sampling strategies, and 6 subject software systems. We found that both the learning technique and the sampling strategy have a strong influence on prediction accuracy. We further observed that some learning techniques (e.g., random forests) outperform other learning techniques (e.g., k-nearest neighbor) in most cases. Moreover, as the prediction accuracy strongly depends on the subject system, there is no combination of a learning technique and sampling strategy that is optimal in all cases, considering the tradeoff between accuracy and measurement overhead, which is in line with the famous no-free-lunch theorem.
Transfer Learning for Performance Modeling of Configurable Systems: An Exploratory Analysis
Sep 07, 2017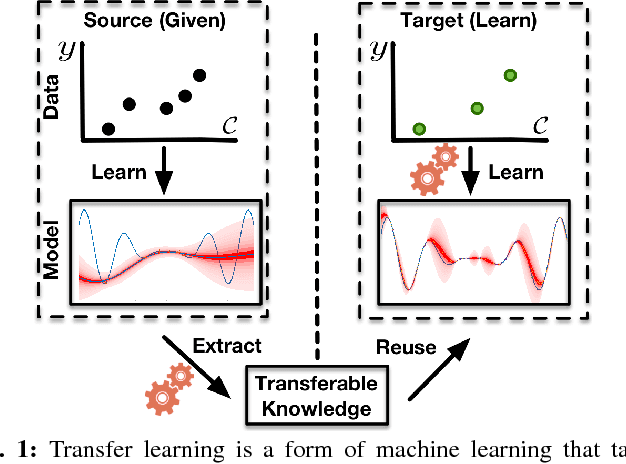

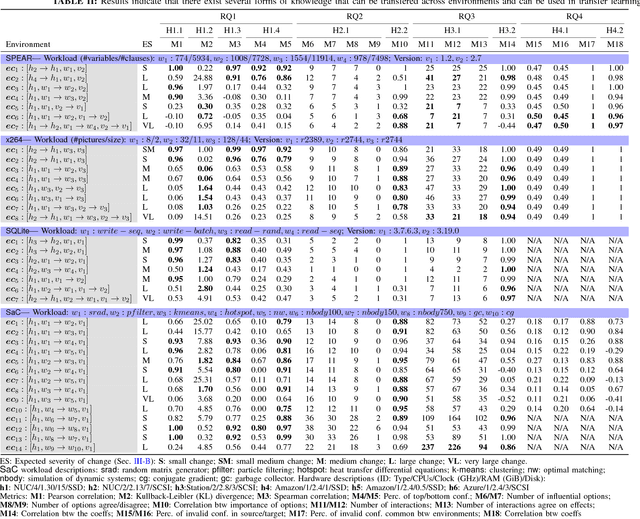
Modern software systems provide many configuration options which significantly influence their non-functional properties. To understand and predict the effect of configuration options, several sampling and learning strategies have been proposed, albeit often with significant cost to cover the highly dimensional configuration space. Recently, transfer learning has been applied to reduce the effort of constructing performance models by transferring knowledge about performance behavior across environments. While this line of research is promising to learn more accurate models at a lower cost, it is unclear why and when transfer learning works for performance modeling. To shed light on when it is beneficial to apply transfer learning, we conducted an empirical study on four popular software systems, varying software configurations and environmental conditions, such as hardware, workload, and software versions, to identify the key knowledge pieces that can be exploited for transfer learning. Our results show that in small environmental changes (e.g., homogeneous workload change), by applying a linear transformation to the performance model, we can understand the performance behavior of the target environment, while for severe environmental changes (e.g., drastic workload change) we can transfer only knowledge that makes sampling more efficient, e.g., by reducing the dimensionality of the configuration space.
Faster Discovery of Faster System Configurations with Spectral Learning
Aug 03, 2017

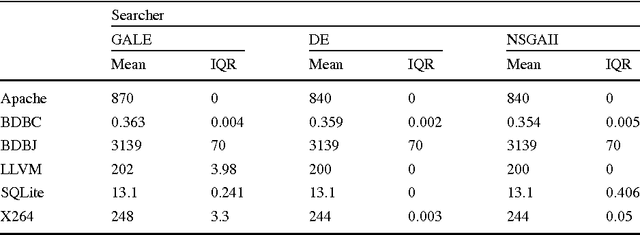

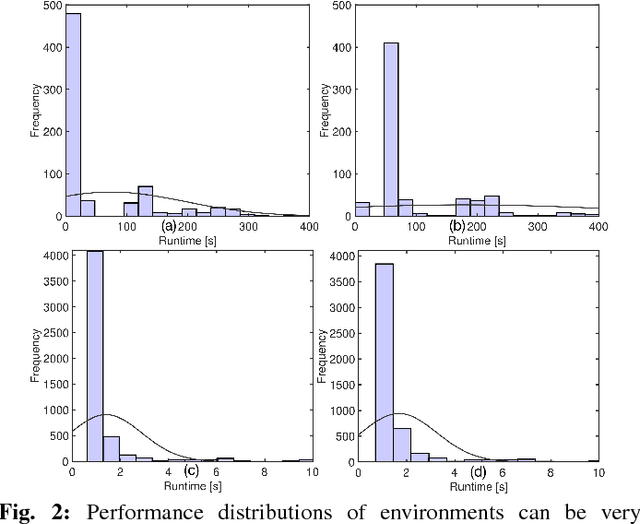
Despite the huge spread and economical importance of configurable software systems, there is unsatisfactory support in utilizing the full potential of these systems with respect to finding performance-optimal configurations. Prior work on predicting the performance of software configurations suffered from either (a) requiring far too many sample configurations or (b) large variances in their predictions. Both these problems can be avoided using the WHAT spectral learner. WHAT's innovation is the use of the spectrum (eigenvalues) of the distance matrix between the configurations of a configurable software system, to perform dimensionality reduction. Within that reduced configuration space, many closely associated configurations can be studied by executing only a few sample configurations. For the subject systems studied here, a few dozen samples yield accurate and stable predictors - less than 10% prediction error, with a standard deviation of less than 2%. When compared to the state of the art, WHAT (a) requires 2 to 10 times fewer samples to achieve similar prediction accuracies, and (b) its predictions are more stable (i.e., have lower standard deviation). Furthermore, we demonstrate that predictive models generated by WHAT can be used by optimizers to discover system configurations that closely approach the optimal performance.