 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOVI-AgentSim: an Agent-based Model for Evaluating Methods of Digital Contact Tracing
Oct 30, 2020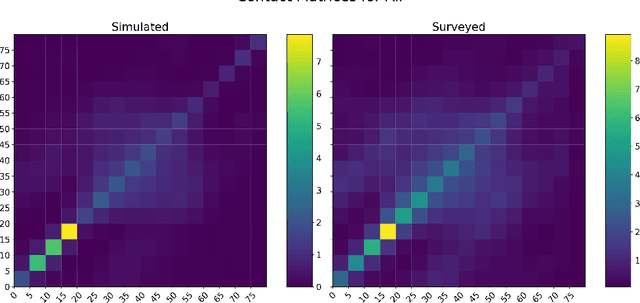
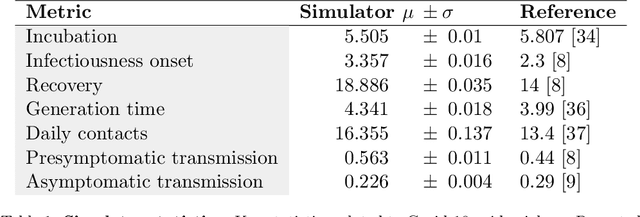
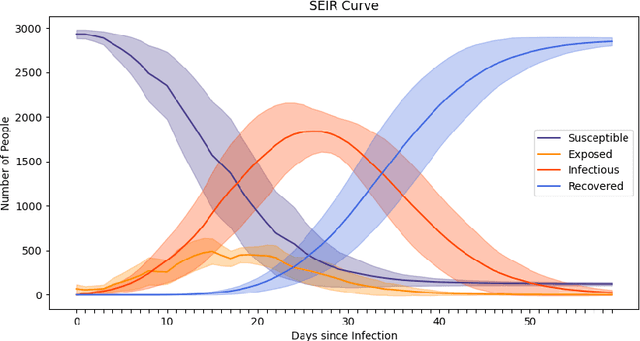
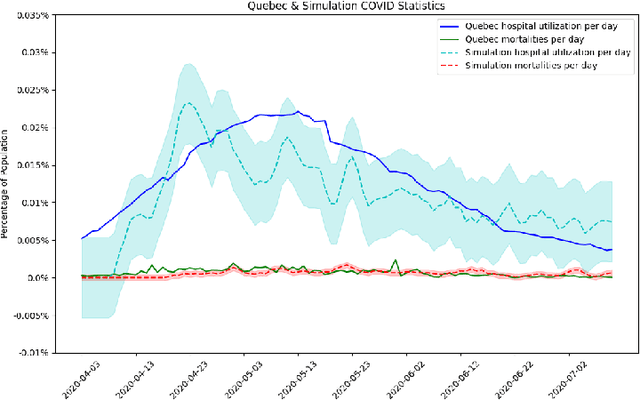
The rapid global spread of COVID-19 has led to an unprecedented demand for effective methods to mitigate the spread of the disease, and various digital contact tracing (DCT) methods have emerged as a component of the solution. In order to make informed public health choices, there is a need for tools which allow evaluation and comparison of DCT methods. We introduce an agent-based compartmental simulator we call COVI-AgentSim, integrating detailed consideration of virology, disease progression, social contact networks, and mobility patterns, based on parameters derived from empirical research. We verify by comparing to real data that COVI-AgentSim is able to reproduce realistic COVID-19 spread dynamics, and perform a sensitivity analysis to verify that the relative performance of contact tracing methods are consistent across a range of settings. We use COVI-AgentSim to perform cost-benefit analyses comparing no DCT to: 1) standard binary contact tracing (BCT) that assigns binary recommendations based on binary test results; and 2) a rule-based method for feature-based contact tracing (FCT) that assigns a graded level of recommendation based on diverse individual features. We find all DCT methods consistently reduce the spread of the disease, and that the advantage of FCT over BCT is maintained over a wide range of adoption rates. Feature-based methods of contact tracing avert more disability-adjusted life years (DALYs) per socioeconomic cost (measured by productive hours lost). Our results suggest any DCT method can help save lives, support re-opening of economies, and prevent second-wave outbreaks, and that FCT methods are a promising direction for enriching BCT using self-reported symptoms, yielding earlier warning signals and a significantly reduced spread of the virus per socioeconomic cost.
Transfer Learning for Performance Modeling of Configurable Systems: An Exploratory Analysis
Sep 07, 2017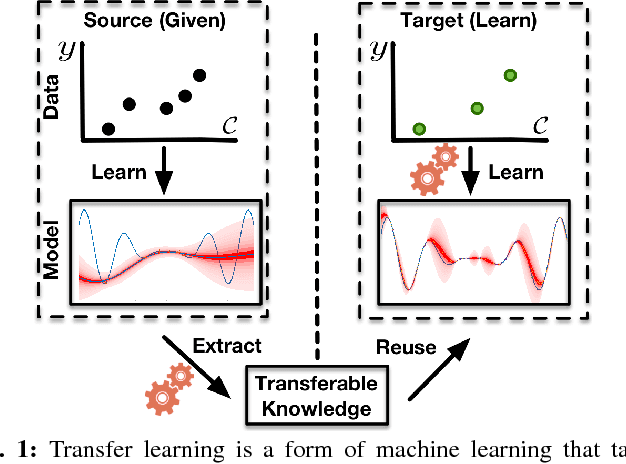
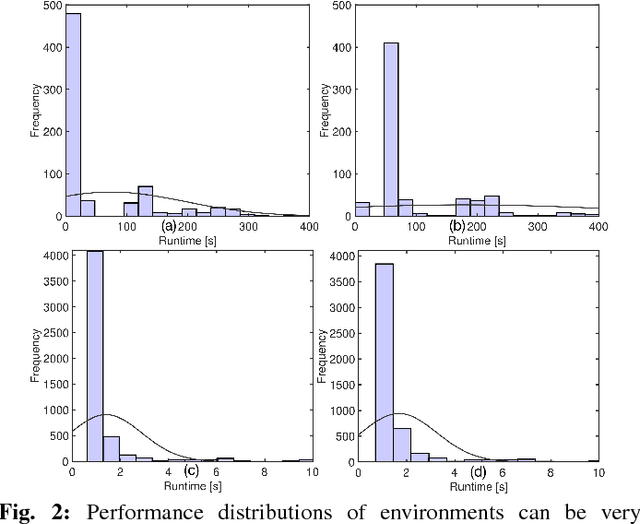

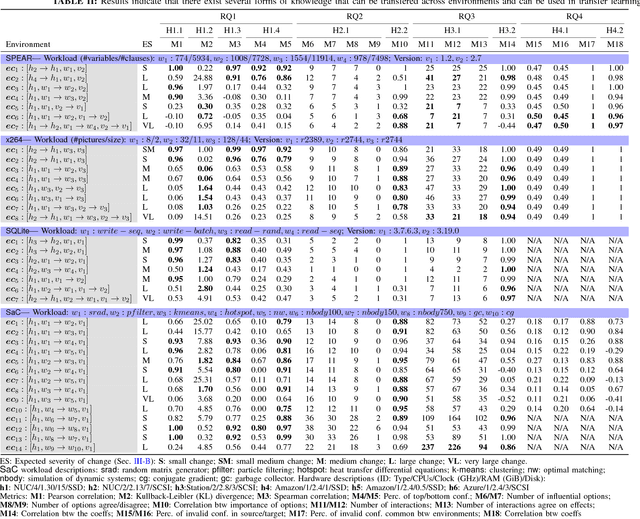
Modern software systems provide many configuration options which significantly influence their non-functional properties. To understand and predict the effect of configuration options, several sampling and learning strategies have been proposed, albeit often with significant cost to cover the highly dimensional configuration space. Recently, transfer learning has been applied to reduce the effort of constructing performance models by transferring knowledge about performance behavior across environments. While this line of research is promising to learn more accurate models at a lower cost, it is unclear why and when transfer learning works for performance modeling. To shed light on when it is beneficial to apply transfer learning, we conducted an empirical study on four popular software systems, varying software configurations and environmental conditions, such as hardware, workload, and software versions, to identify the key knowledge pieces that can be exploited for transfer learning. Our results show that in small environmental changes (e.g., homogeneous workload change), by applying a linear transformation to the performance model, we can understand the performance behavior of the target environment, while for severe environmental changes (e.g., drastic workload change) we can transfer only knowledge that makes sampling more efficient, e.g., by reducing the dimensionality of the configuration space.