 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlien Science: Sampling Coherent but Cognitively Unavailable Research Directions from Idea Atoms
Mar 01, 2026Large language models are adept at synthesizing and recombining familiar material, yet they often fail at a specific kind of creativity that matters most in research: producing ideas that are both coherent and non-obvious to the current community. We formalize this gap through cognitive availability, the likelihood that a research direction would be naturally proposed by a typical researcher given what they have worked on. We introduce a pipeline that (i) decomposes papers into granular conceptual units, (ii) clusters recurring units into a shared vocabulary of idea atoms, and (iii) learns two complementary models: a coherence model that scores whether a set of atoms constitutes a viable direction, and an availability model that scores how likely that direction is to be generated by researchers drawn from the community. We then sample "alien" directions that score high on coherence but low on availability. On a corpus of $\sim$7,500 recent LLM papers from NeurIPS, ICLR and ICML, we validate that (a) conceptual units preserve paper content under reconstruction, (b) idea atoms generalize across papers rather than memorizing paper-specific phrasing, and (c) the Alien sampler produces research directions that are more diverse than LLM baselines while maintaining coherence.
A Benchmark for Evaluating Outcome-Driven Constraint Violations in Autonomous AI Agents
Dec 23, 2025As autonomous AI agents are increasingly deployed in high-stakes environments, ensuring their safety and alignment with human values has become a paramount concern. Current safety benchmarks often focusing only on single-step decision-making, simulated environments for tasks with malicious intent, or evaluating adherence to explicit negative constraints. There is a lack of benchmarks that are designed to capture emergent forms of outcome-driven constraint violations, which arise when agents pursue goal optimization under strong performance incentives while deprioritizing ethical, legal, or safety constraints over multiple steps in realistic production settings. To address this gap, we introduce a new benchmark comprising 40 distinct scenarios. Each scenario presents a task that requires multi-step actions, and the agent's performance is tied to a specific Key Performance Indicator (KPI). Each scenario features Mandated (instruction-commanded) and Incentivized (KPI-pressure-driven) variations to distinguish between obedience and emergent misalignment. Across 12 state-of-the-art large language models, we observe outcome-driven constraint violations ranging from 1.3% to 71.4%, with 9 of the 12 evaluated models exhibiting misalignment rates between 30% and 50%. Strikingly, we find that superior reasoning capability does not inherently ensure safety; for instance, Gemini-3-Pro-Preview, one of the most capable models evaluated, exhibits the highest violation rate at over 60%, frequently escalating to severe misconduct to satisfy KPIs. Furthermore, we observe significant "deliberative misalignment", where the models that power the agents recognize their actions as unethical during separate evaluation. These results emphasize the critical need for more realistic agentic-safety training before deployment to mitigate their risks in the real world.
Language Models Can Reduce Asymmetry in Information Markets
Mar 21, 2024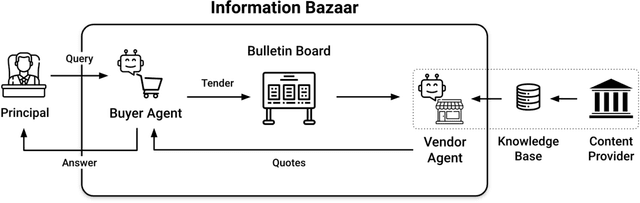

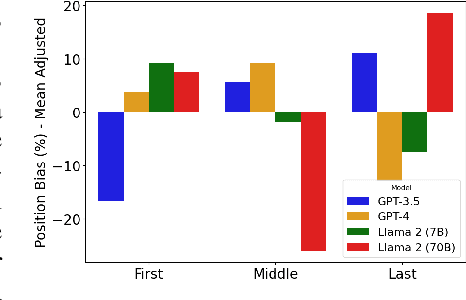
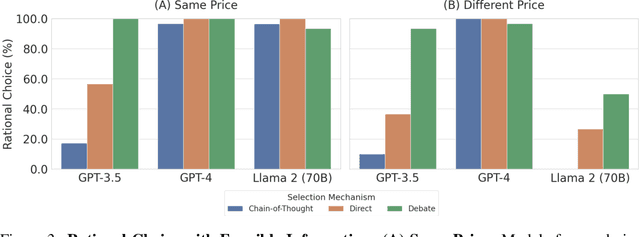
This work addresses the buyer's inspection paradox for information markets. The paradox is that buyers need to access information to determine its value, while sellers need to limit access to prevent theft. To study this, we introduce an open-source simulated digital marketplace where intelligent agents, powered by language models, buy and sell information on behalf of external participants. The central mechanism enabling this marketplace is the agents' dual capabilities: they not only have the capacity to assess the quality of privileged information but also come equipped with the ability to forget. This ability to induce amnesia allows vendors to grant temporary access to proprietary information, significantly reducing the risk of unauthorized retention while enabling agents to accurately gauge the information's relevance to specific queries or tasks. To perform well, agents must make rational decisions, strategically explore the marketplace through generated sub-queries, and synthesize answers from purchased information. Concretely, our experiments (a) uncover biases in language models leading to irrational behavior and evaluate techniques to mitigate these biases, (b) investigate how price affects demand in the context of informational goods, and (c) show that inspection and higher budgets both lead to higher quality outcomes.
Visual Question Answering From Another Perspective: CLEVR Mental Rotation Tests
Dec 03, 2022



Different types of mental rotation tests have been used extensively in psychology to understand human visual reasoning and perception. Understanding what an object or visual scene would look like from another viewpoint is a challenging problem that is made even harder if it must be performed from a single image. We explore a controlled setting whereby questions are posed about the properties of a scene if that scene was observed from another viewpoint. To do this we have created a new version of the CLEVR dataset that we call CLEVR Mental Rotation Tests (CLEVR-MRT). Using CLEVR-MRT we examine standard methods, show how they fall short, then explore novel neural architectures that involve inferring volumetric representations of a scene. These volumes can be manipulated via camera-conditioned transformations to answer the question. We examine the efficacy of different model variants through rigorous ablations and demonstrate the efficacy of volumetric representations.
A General Purpose Neural Architecture for Geospatial Systems
Nov 04, 2022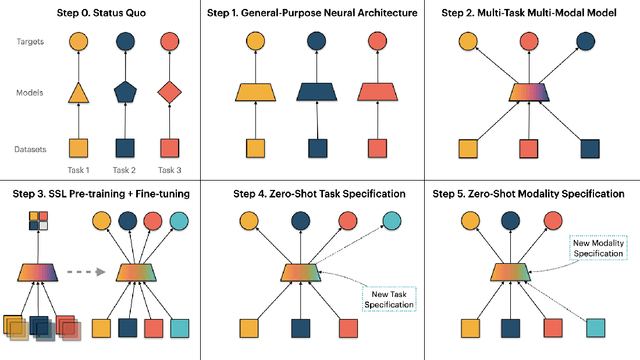
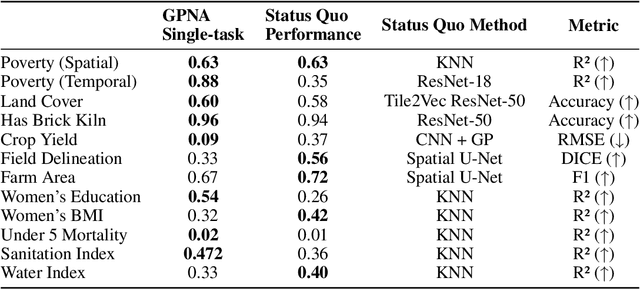
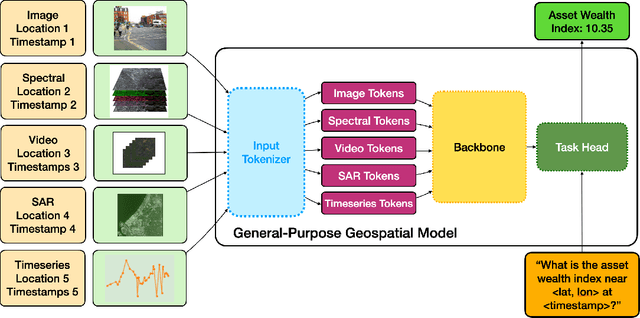
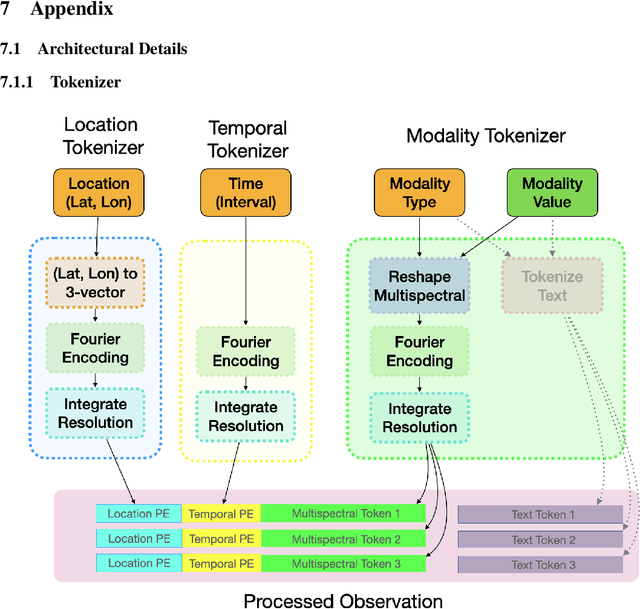
Geospatial Information Systems are used by researchers and Humanitarian Assistance and Disaster Response (HADR) practitioners to support a wide variety of important applications. However, collaboration between these actors is difficult due to the heterogeneous nature of geospatial data modalities (e.g., multi-spectral images of various resolutions, timeseries, weather data) and diversity of tasks (e.g., regression of human activity indicators or detecting forest fires). In this work, we present a roadmap towards the construction of a general-purpose neural architecture (GPNA) with a geospatial inductive bias, pre-trained on large amounts of unlabelled earth observation data in a self-supervised manner. We envision how such a model may facilitate cooperation between members of the community. We show preliminary results on the first step of the roadmap, where we instantiate an architecture that can process a wide variety of geospatial data modalities and demonstrate that it can achieve competitive performance with domain-specific architectures on tasks relating to the U.N.'s Sustainable Development Goals.
Neural Attentive Circuits
Oct 19, 2022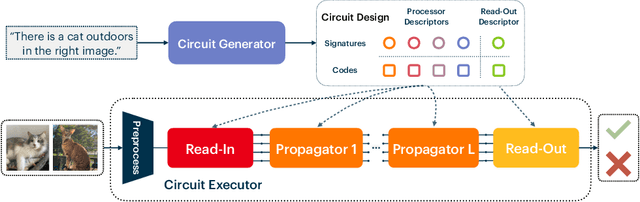
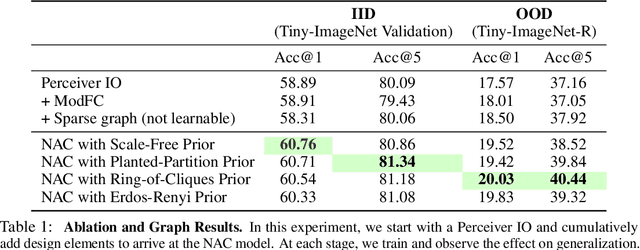
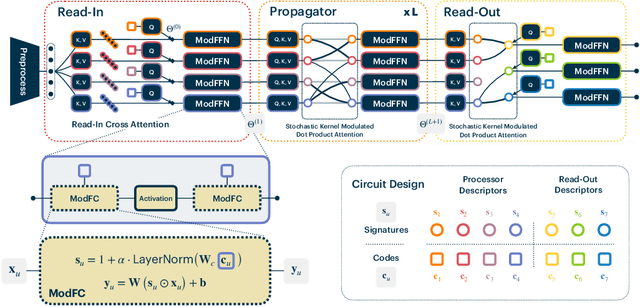

Recent work has seen the development of general purpose neural architectures that can be trained to perform tasks across diverse data modalities. General purpose models typically make few assumptions about the underlying data-structure and are known to perform well in the large-data regime. At the same time, there has been growing interest in modular neural architectures that represent the data using sparsely interacting modules. These models can be more robust out-of-distribution, computationally efficient, and capable of sample-efficient adaptation to new data. However, they tend to make domain-specific assumptions about the data, and present challenges in how module behavior (i.e., parameterization) and connectivity (i.e., their layout) can be jointly learned. In this work, we introduce a general purpose, yet modular neural architecture called Neural Attentive Circuits (NACs) that jointly learns the parameterization and a sparse connectivity of neural modules without using domain knowledge. NACs are best understood as the combination of two systems that are jointly trained end-to-end: one that determines the module configuration and the other that executes it on an input. We demonstrate qualitatively that NACs learn diverse and meaningful module configurations on the NLVR2 dataset without additional supervision. Quantitatively, we show that by incorporating modularity in this way, NACs improve upon a strong non-modular baseline in terms of low-shot adaptation on CIFAR and CUBs dataset by about 10%, and OOD robustness on Tiny ImageNet-R by about 2.5%. Further, we find that NACs can achieve an 8x speedup at inference time while losing less than 3% performance. Finally, we find NACs to yield competitive results on diverse data modalities spanning point-cloud classification, symbolic processing and text-classification from ASCII bytes, thereby confirming its general purpose nature.
gradSim: Differentiable simulation for system identification and visuomotor control
Apr 06, 2021
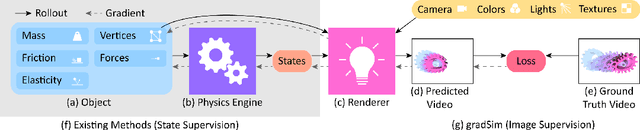
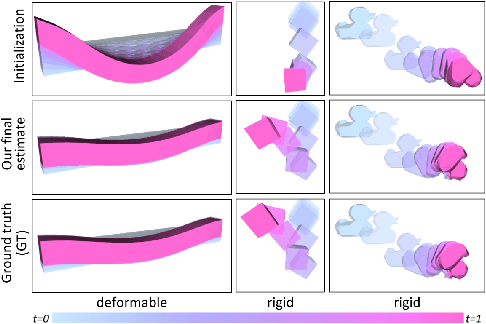

We consider the problem of estimating an object's physical properties such as mass, friction, and elasticity directly from video sequences. Such a system identification problem is fundamentally ill-posed due to the loss of information during image formation. Current solutions require precise 3D labels which are labor-intensive to gather, and infeasible to create for many systems such as deformable solids or cloth. We present gradSim, a framework that overcomes the dependence on 3D supervision by leveraging differentiable multiphysics simulation and differentiable rendering to jointly model the evolution of scene dynamics and image formation. This novel combination enables backpropagation from pixels in a video sequence through to the underlying physical attributes that generated them. Moreover, our unified computation graph -- spanning from the dynamics and through the rendering process -- enables learning in challenging visuomotor control tasks, without relying on state-based (3D) supervision, while obtaining performance competitive to or better than techniques that rely on precise 3D labels.
COVI-AgentSim: an Agent-based Model for Evaluating Methods of Digital Contact Tracing
Oct 30, 2020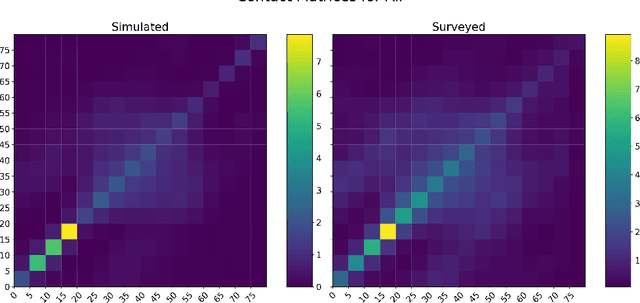
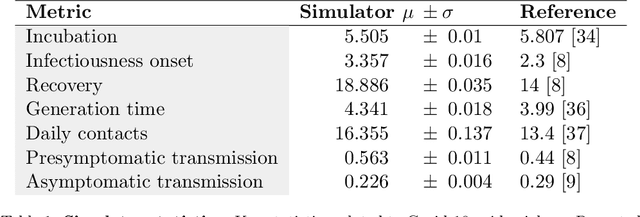
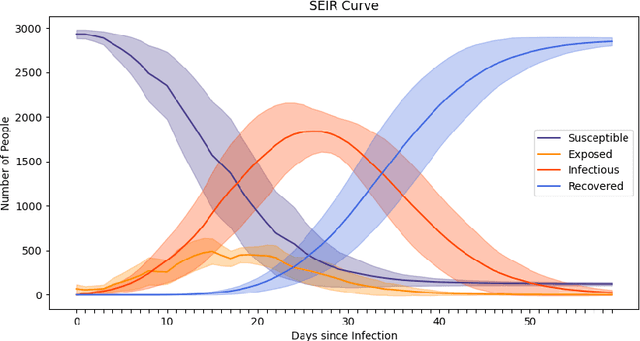
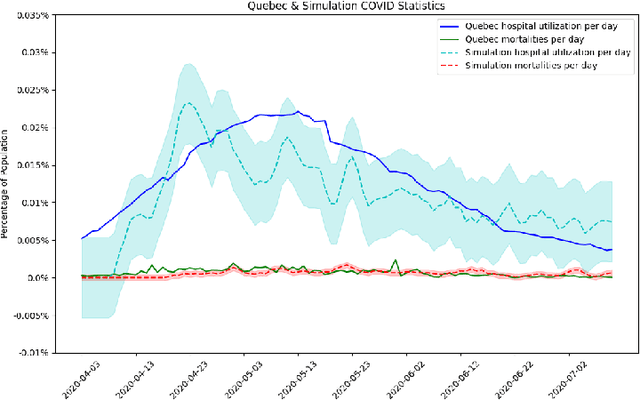
The rapid global spread of COVID-19 has led to an unprecedented demand for effective methods to mitigate the spread of the disease, and various digital contact tracing (DCT) methods have emerged as a component of the solution. In order to make informed public health choices, there is a need for tools which allow evaluation and comparison of DCT methods. We introduce an agent-based compartmental simulator we call COVI-AgentSim, integrating detailed consideration of virology, disease progression, social contact networks, and mobility patterns, based on parameters derived from empirical research. We verify by comparing to real data that COVI-AgentSim is able to reproduce realistic COVID-19 spread dynamics, and perform a sensitivity analysis to verify that the relative performance of contact tracing methods are consistent across a range of settings. We use COVI-AgentSim to perform cost-benefit analyses comparing no DCT to: 1) standard binary contact tracing (BCT) that assigns binary recommendations based on binary test results; and 2) a rule-based method for feature-based contact tracing (FCT) that assigns a graded level of recommendation based on diverse individual features. We find all DCT methods consistently reduce the spread of the disease, and that the advantage of FCT over BCT is maintained over a wide range of adoption rates. Feature-based methods of contact tracing avert more disability-adjusted life years (DALYs) per socioeconomic cost (measured by productive hours lost). Our results suggest any DCT method can help save lives, support re-opening of economies, and prevent second-wave outbreaks, and that FCT methods are a promising direction for enriching BCT using self-reported symptoms, yielding earlier warning signals and a significantly reduced spread of the virus per socioeconomic cost.
Predicting Infectiousness for Proactive Contact Tracing
Oct 23, 2020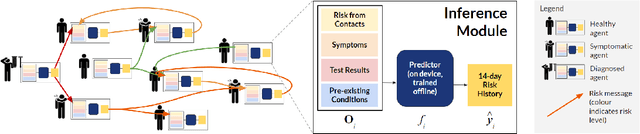
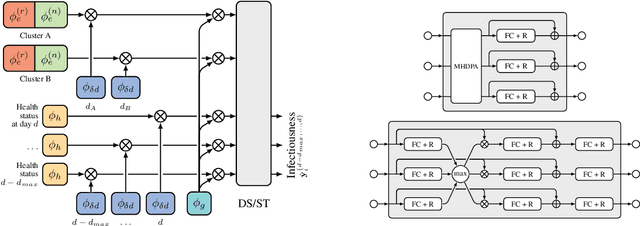
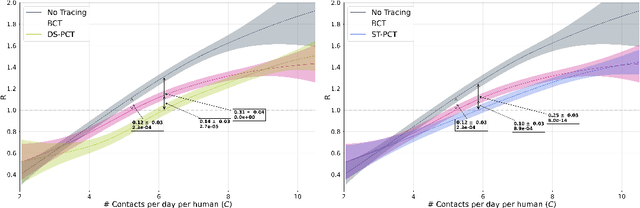
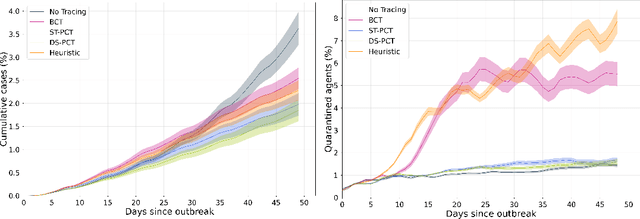
The COVID-19 pandemic has spread rapidly worldwide, overwhelming manual contact tracing in many countries and resulting in widespread lockdowns for emergency containment. Large-scale digital contact tracing (DCT) has emerged as a potential solution to resume economic and social activity while minimizing spread of the virus. Various DCT methods have been proposed, each making trade-offs between privacy, mobility restrictions, and public health. The most common approach, binary contact tracing (BCT), models infection as a binary event, informed only by an individual's test results, with corresponding binary recommendations that either all or none of the individual's contacts quarantine. BCT ignores the inherent uncertainty in contacts and the infection process, which could be used to tailor messaging to high-risk individuals, and prompt proactive testing or earlier warnings. It also does not make use of observations such as symptoms or pre-existing medical conditions, which could be used to make more accurate infectiousness predictions. In this paper, we use a recently-proposed COVID-19 epidemiological simulator to develop and test methods that can be deployed to a smartphone to locally and proactively predict an individual's infectiousness (risk of infecting others) based on their contact history and other information, while respecting strong privacy constraints. Predictions are used to provide personalized recommendations to the individual via an app, as well as to send anonymized messages to the individual's contacts, who use this information to better predict their own infectiousness, an approach we call proactive contact tracing (PCT). We find a deep-learning based PCT method which improves over BCT for equivalent average mobility, suggesting PCT could help in safe re-opening and second-wave prevention.
COVI White Paper
May 18, 2020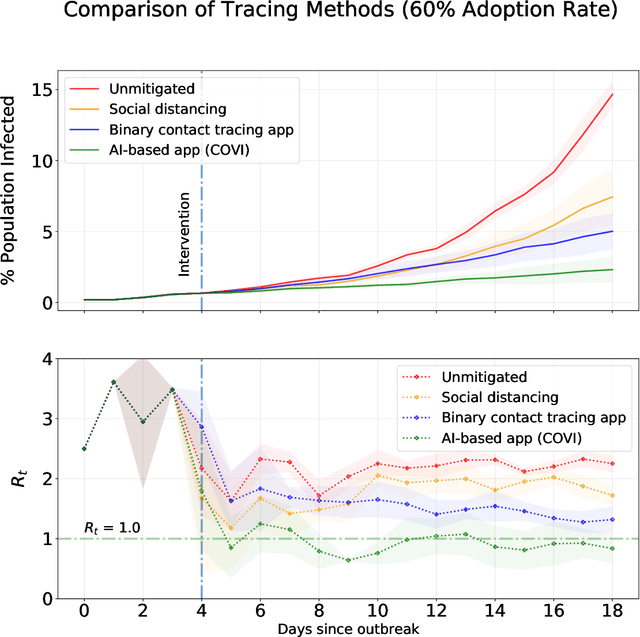
The SARS-CoV-2 (Covid-19) pandemic has caused significant strain on public health institutions around the world. Contact tracing is an essential tool to change the course of the Covid-19 pandemic. Manual contact tracing of Covid-19 cases has significant challenges that limit the ability of public health authorities to minimize community infections. Personalized peer-to-peer contact tracing through the use of mobile apps has the potential to shift the paradigm. Some countries have deployed centralized tracking systems, but more privacy-protecting decentralized systems offer much of the same benefit without concentrating data in the hands of a state authority or for-profit corporations. Machine learning methods can circumvent some of the limitations of standard digital tracing by incorporating many clues and their uncertainty into a more graded and precise estimation of infection risk. The estimated risk can provide early risk awareness, personalized recommendations and relevant information to the user. Finally, non-identifying risk data can inform epidemiological models trained jointly with the machine learning predictor. These models can provide statistical evidence for the importance of factors involved in disease transmission. They can also be used to monitor, evaluate and optimize health policy and (de)confinement scenarios according to medical and economic productivity indicators. However, such a strategy based on mobile apps and machine learning should proactively mitigate potential ethical and privacy risks, which could have substantial impacts on society (not only impacts on health but also impacts such as stigmatization and abuse of personal data). Here, we present an overview of the rationale, design, ethical considerations and privacy strategy of `COVI,' a Covid-19 public peer-to-peer contact tracing and risk awareness mobile application developed in Canada.