 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Benign Inputs Lead to Severe Harms: Eliciting Unsafe Unintended Behaviors of Computer-Use Agents
Feb 09, 2026Although computer-use agents (CUAs) hold significant potential to automate increasingly complex OS workflows, they can demonstrate unsafe unintended behaviors that deviate from expected outcomes even under benign input contexts. However, exploration of this risk remains largely anecdotal, lacking concrete characterization and automated methods to proactively surface long-tail unintended behaviors under realistic CUA scenarios. To fill this gap, we introduce the first conceptual and methodological framework for unintended CUA behaviors, by defining their key characteristics, automatically eliciting them, and analyzing how they arise from benign inputs. We propose AutoElicit: an agentic framework that iteratively perturbs benign instructions using CUA execution feedback, and elicits severe harms while keeping perturbations realistic and benign. Using AutoElicit, we surface hundreds of harmful unintended behaviors from state-of-the-art CUAs such as Claude 4.5 Haiku and Opus. We further evaluate the transferability of human-verified successful perturbations, identifying persistent susceptibility to unintended behaviors across various other frontier CUAs. This work establishes a foundation for systematically analyzing unintended behaviors in realistic computer-use settings.
Active Attacks: Red-teaming LLMs via Adaptive Environments
Sep 26, 2025



We address the challenge of generating diverse attack prompts for large language models (LLMs) that elicit harmful behaviors (e.g., insults, sexual content) and are used for safety fine-tuning. Rather than relying on manual prompt engineering, attacker LLMs can be trained with reinforcement learning (RL) to automatically generate such prompts using only a toxicity classifier as a reward. However, capturing a wide range of harmful behaviors is a significant challenge that requires explicit diversity objectives. Existing diversity-seeking RL methods often collapse to limited modes: once high-reward prompts are found, exploration of new regions is discouraged. Inspired by the active learning paradigm that encourages adaptive exploration, we introduce \textit{Active Attacks}, a novel RL-based red-teaming algorithm that adapts its attacks as the victim evolves. By periodically safety fine-tuning the victim LLM with collected attack prompts, rewards in exploited regions diminish, which forces the attacker to seek unexplored vulnerabilities. This process naturally induces an easy-to-hard exploration curriculum, where the attacker progresses beyond easy modes toward increasingly difficult ones. As a result, Active Attacks uncovers a wide range of local attack modes step by step, and their combination achieves wide coverage of the multi-mode distribution. Active Attacks, a simple plug-and-play module that seamlessly integrates into existing RL objectives, unexpectedly outperformed prior RL-based methods -- including GFlowNets, PPO, and REINFORCE -- by improving cross-attack success rates against GFlowNets, the previous state-of-the-art, from 0.07% to 31.28% (a relative gain greater than $400\ \times$) with only a 6% increase in computation. Our code is publicly available \href{https://github.com/dbsxodud-11/active_attacks}{here}.
Superintelligent Agents Pose Catastrophic Risks: Can Scientist AI Offer a Safer Path?
Feb 21, 2025The leading AI companies are increasingly focused on building generalist AI agents -- systems that can autonomously plan, act, and pursue goals across almost all tasks that humans can perform. Despite how useful these systems might be, unchecked AI agency poses significant risks to public safety and security, ranging from misuse by malicious actors to a potentially irreversible loss of human control. We discuss how these risks arise from current AI training methods. Indeed, various scenarios and experiments have demonstrated the possibility of AI agents engaging in deception or pursuing goals that were not specified by human operators and that conflict with human interests, such as self-preservation. Following the precautionary principle, we see a strong need for safer, yet still useful, alternatives to the current agency-driven trajectory. Accordingly, we propose as a core building block for further advances the development of a non-agentic AI system that is trustworthy and safe by design, which we call Scientist AI. This system is designed to explain the world from observations, as opposed to taking actions in it to imitate or please humans. It comprises a world model that generates theories to explain data and a question-answering inference machine. Both components operate with an explicit notion of uncertainty to mitigate the risks of overconfident predictions. In light of these considerations, a Scientist AI could be used to assist human researchers in accelerating scientific progress, including in AI safety. In particular, our system can be employed as a guardrail against AI agents that might be created despite the risks involved. Ultimately, focusing on non-agentic AI may enable the benefits of AI innovation while avoiding the risks associated with the current trajectory. We hope these arguments will motivate researchers, developers, and policymakers to favor this safer path.
AIMS.au: A Dataset for the Analysis of Modern Slavery Countermeasures in Corporate Statements
Feb 10, 2025



Despite over a decade of legislative efforts to address modern slavery in the supply chains of large corporations, the effectiveness of government oversight remains hampered by the challenge of scrutinizing thousands of statements annually. While Large Language Models (LLMs) can be considered a well established solution for the automatic analysis and summarization of documents, recognizing concrete modern slavery countermeasures taken by companies and differentiating those from vague claims remains a challenging task. To help evaluate and fine-tune LLMs for the assessment of corporate statements, we introduce a dataset composed of 5,731 modern slavery statements taken from the Australian Modern Slavery Register and annotated at the sentence level. This paper details the construction steps for the dataset that include the careful design of annotation specifications, the selection and preprocessing of statements, and the creation of high-quality annotation subsets for effective model evaluations. To demonstrate our dataset's utility, we propose a machine learning methodology for the detection of sentences relevant to mandatory reporting requirements set by the Australian Modern Slavery Act. We then follow this methodology to benchmark modern language models under zero-shot and supervised learning settings.
On the Limits of Multi-modal Meta-Learning with Auxiliary Task Modulation Using Conditional Batch Normalization
May 29, 2024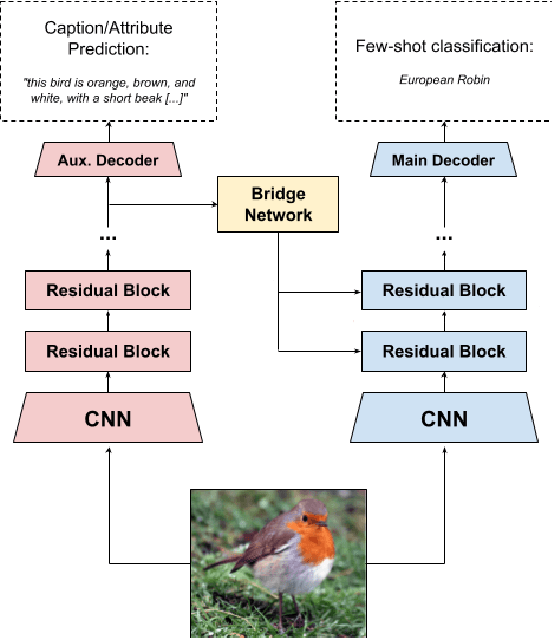


Few-shot learning aims to learn representations that can tackle novel tasks given a small number of examples. Recent studies show that cross-modal learning can improve representations for few-shot classification. More specifically, language is a rich modality that can be used to guide visual learning. In this work, we experiment with a multi-modal architecture for few-shot learning that consists of three components: a classifier, an auxiliary network, and a bridge network. While the classifier performs the main classification task, the auxiliary network learns to predict language representations from the same input, and the bridge network transforms high-level features of the auxiliary network into modulation parameters for layers of the few-shot classifier using conditional batch normalization. The bridge should encourage a form of lightweight semantic alignment between language and vision which could be useful for the classifier. However, after evaluating the proposed approach on two popular few-shot classification benchmarks we find that a) the improvements do not reproduce across benchmarks, and b) when they do, the improvements are due to the additional compute and parameters introduced by the bridge network. We contribute insights and recommendations for future work in multi-modal meta-learning, especially when using language representations.
Transformers in Reinforcement Learning: A Survey
Jul 12, 2023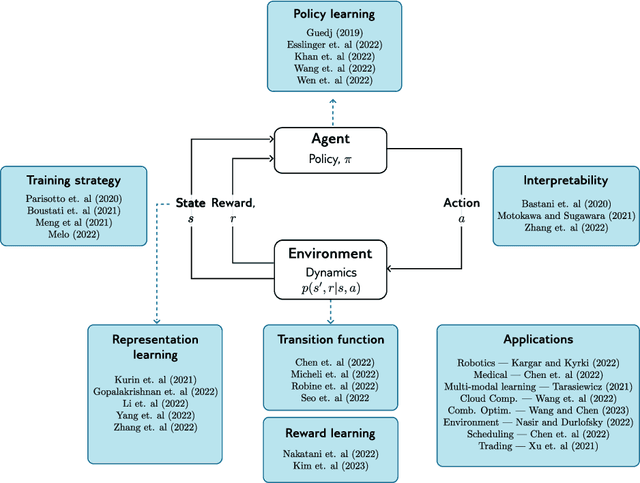
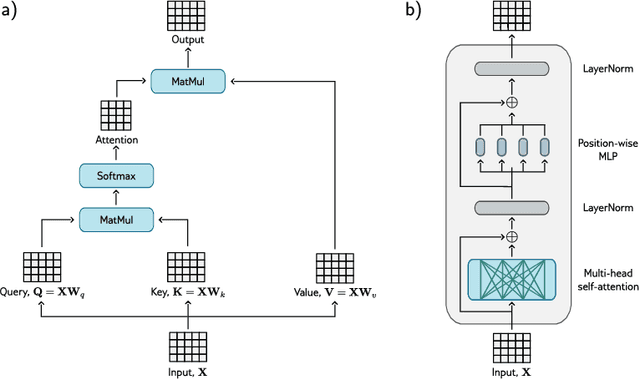

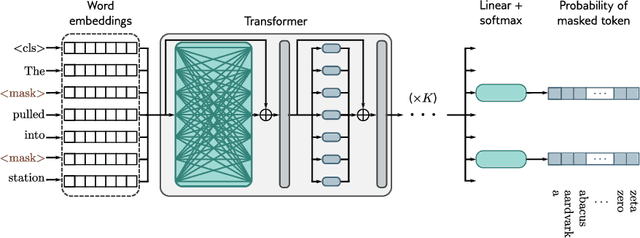
Transformers have significantly impacted domains like natural language processing, computer vision, and robotics, where they improve performance compared to other neural networks. This survey explores how transformers are used in reinforcement learning (RL), where they are seen as a promising solution for addressing challenges such as unstable training, credit assignment, lack of interpretability, and partial observability. We begin by providing a brief domain overview of RL, followed by a discussion on the challenges of classical RL algorithms. Next, we delve into the properties of the transformer and its variants and discuss the characteristics that make them well-suited to address the challenges inherent in RL. We examine the application of transformers to various aspects of RL, including representation learning, transition and reward function modeling, and policy optimization. We also discuss recent research that aims to enhance the interpretability and efficiency of transformers in RL, using visualization techniques and efficient training strategies. Often, the transformer architecture must be tailored to the specific needs of a given application. We present a broad overview of how transformers have been adapted for several applications, including robotics, medicine, language modeling, cloud computing, and combinatorial optimization. We conclude by discussing the limitations of using transformers in RL and assess their potential for catalyzing future breakthroughs in this field.
Predicting Infectiousness for Proactive Contact Tracing
Oct 23, 2020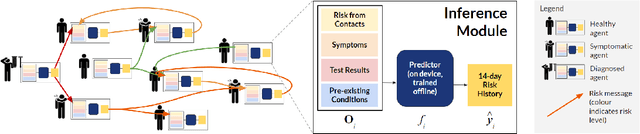
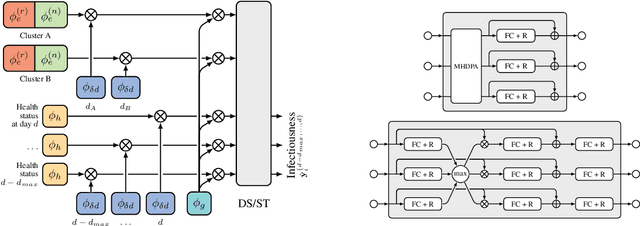
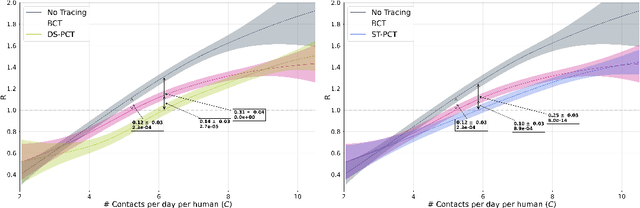
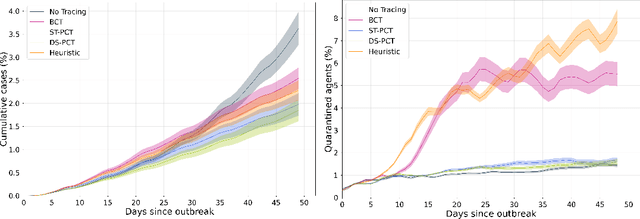
The COVID-19 pandemic has spread rapidly worldwide, overwhelming manual contact tracing in many countries and resulting in widespread lockdowns for emergency containment. Large-scale digital contact tracing (DCT) has emerged as a potential solution to resume economic and social activity while minimizing spread of the virus. Various DCT methods have been proposed, each making trade-offs between privacy, mobility restrictions, and public health. The most common approach, binary contact tracing (BCT), models infection as a binary event, informed only by an individual's test results, with corresponding binary recommendations that either all or none of the individual's contacts quarantine. BCT ignores the inherent uncertainty in contacts and the infection process, which could be used to tailor messaging to high-risk individuals, and prompt proactive testing or earlier warnings. It also does not make use of observations such as symptoms or pre-existing medical conditions, which could be used to make more accurate infectiousness predictions. In this paper, we use a recently-proposed COVID-19 epidemiological simulator to develop and test methods that can be deployed to a smartphone to locally and proactively predict an individual's infectiousness (risk of infecting others) based on their contact history and other information, while respecting strong privacy constraints. Predictions are used to provide personalized recommendations to the individual via an app, as well as to send anonymized messages to the individual's contacts, who use this information to better predict their own infectiousness, an approach we call proactive contact tracing (PCT). We find a deep-learning based PCT method which improves over BCT for equivalent average mobility, suggesting PCT could help in safe re-opening and second-wave prevention.
Online Mutual Foreground Segmentation for Multispectral Stereo Videos
Sep 08, 2018
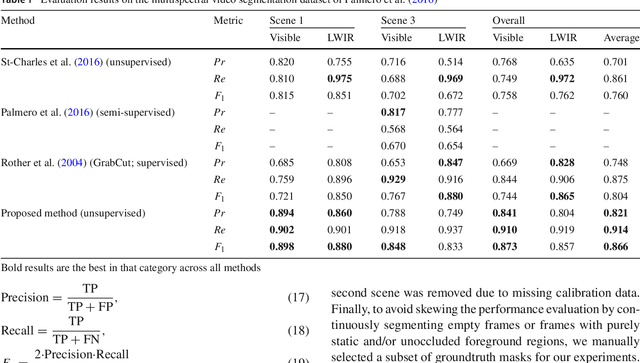
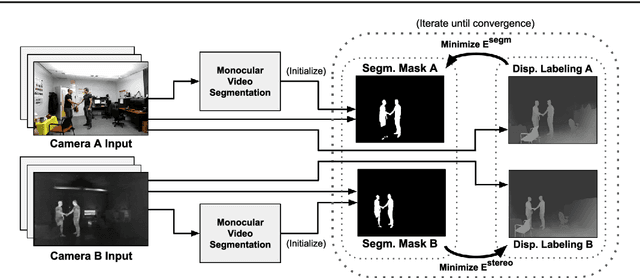
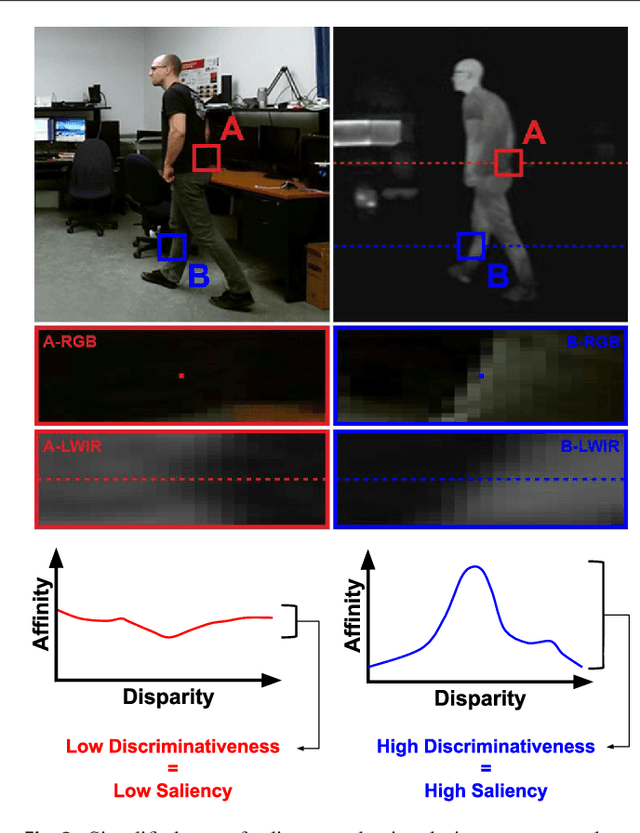
The segmentation of video sequences into foreground and background regions is a low-level process commonly used in video content analysis and smart surveillance applications. Using a multispectral camera setup can improve this process by providing more diverse data to help identify objects despite adverse imaging conditions. The registration of several data sources is however not trivial if the appearance of objects produced by each sensor differs substantially. This problem is further complicated when parallax effects cannot be ignored when using close-range stereo pairs. In this work, we present a new method to simultaneously tackle multispectral segmentation and stereo registration. Using an iterative procedure, we estimate the labeling result for one problem using the provisional result of the other. Our approach is based on the alternating minimization of two energy functions that are linked through the use of dynamic priors. We rely on the integration of shape and appearance cues to find proper multispectral correspondences, and to properly segment objects in low contrast regions. We also formulate our model as a frame processing pipeline using higher order terms to improve the temporal coherence of our results. Our method is evaluated under different configurations on multiple multispectral datasets, and our implementation is available online.
Reproducible Evaluation of Pan-Tilt-Zoom Tracking
May 18, 2015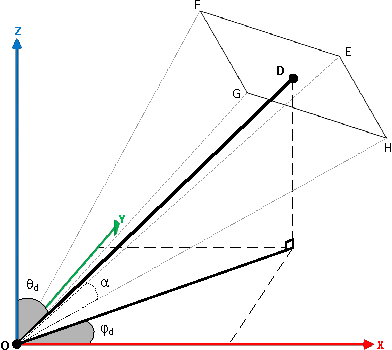
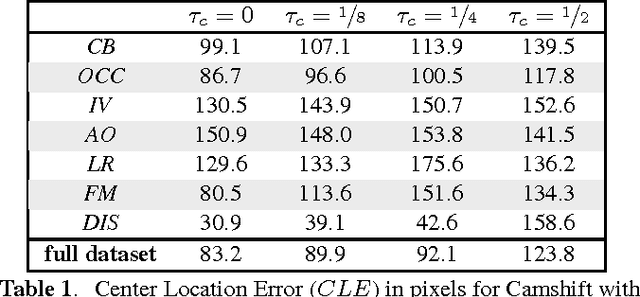
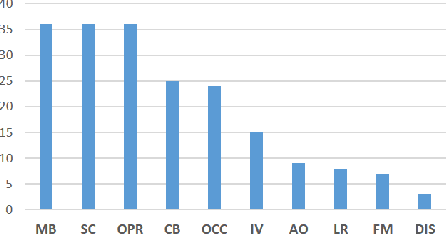

Tracking with a Pan-Tilt-Zoom (PTZ) camera has been a research topic in computer vision for many years. However, it is very difficult to assess the progress that has been made on this topic because there is no standard evaluation methodology. The difficulty in evaluating PTZ tracking algorithms arises from their dynamic nature. In contrast to other forms of tracking, PTZ tracking involves both locating the target in the image and controlling the motors of the camera to aim it so that the target stays in its field of view. This type of tracking can only be performed online. In this paper, we propose a new evaluation framework based on a virtual PTZ camera. With this framework, tracking scenarios do not change for each experiment and we are able to replicate online PTZ camera control and behavior including camera positioning delays, tracker processing delays, and numerical zoom. We tested our evaluation framework with the Camshift tracker to show its viability and to establish baseline results.