 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIMS.au: A Dataset for the Analysis of Modern Slavery Countermeasures in Corporate Statements
Feb 10, 2025



Despite over a decade of legislative efforts to address modern slavery in the supply chains of large corporations, the effectiveness of government oversight remains hampered by the challenge of scrutinizing thousands of statements annually. While Large Language Models (LLMs) can be considered a well established solution for the automatic analysis and summarization of documents, recognizing concrete modern slavery countermeasures taken by companies and differentiating those from vague claims remains a challenging task. To help evaluate and fine-tune LLMs for the assessment of corporate statements, we introduce a dataset composed of 5,731 modern slavery statements taken from the Australian Modern Slavery Register and annotated at the sentence level. This paper details the construction steps for the dataset that include the careful design of annotation specifications, the selection and preprocessing of statements, and the creation of high-quality annotation subsets for effective model evaluations. To demonstrate our dataset's utility, we propose a machine learning methodology for the detection of sentences relevant to mandatory reporting requirements set by the Australian Modern Slavery Act. We then follow this methodology to benchmark modern language models under zero-shot and supervised learning settings.
Federated Learning for Non-factorizable Models using Deep Generative Prior Approximations
May 25, 2024



Federated learning (FL) allows for collaborative model training across decentralized clients while preserving privacy by avoiding data sharing. However, current FL methods assume conditional independence between client models, limiting the use of priors that capture dependence, such as Gaussian processes (GPs). We introduce the Structured Independence via deep Generative Model Approximation (SIGMA) prior which enables FL for non-factorizable models across clients, expanding the applicability of FL to fields such as spatial statistics, epidemiology, environmental science, and other domains where modeling dependencies is crucial. The SIGMA prior is a pre-trained deep generative model that approximates the desired prior and induces a specified conditional independence structure in the latent variables, creating an approximate model suitable for FL settings. We demonstrate the SIGMA prior's effectiveness on synthetic data and showcase its utility in a real-world example of FL for spatial data, using a conditional autoregressive prior to model spatial dependence across Australia. Our work enables new FL applications in domains where modeling dependent data is essential for accurate predictions and decision-making.
Scalable Vertical Federated Learning via Data Augmentation and Amortized Inference
May 07, 2024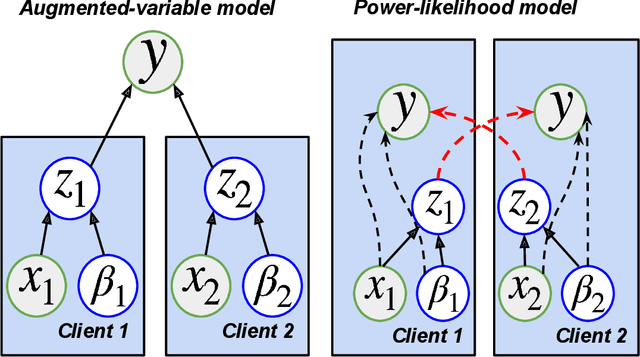


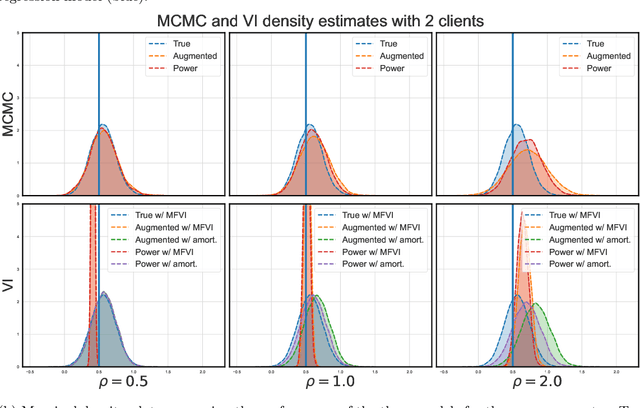
Vertical federated learning (VFL) has emerged as a paradigm for collaborative model estimation across multiple clients, each holding a distinct set of covariates. This paper introduces the first comprehensive framework for fitting Bayesian models in the VFL setting. We propose a novel approach that leverages data augmentation techniques to transform VFL problems into a form compatible with existing Bayesian federated learning algorithms. We present an innovative model formulation for specific VFL scenarios where the joint likelihood factorizes into a product of client-specific likelihoods. To mitigate the dimensionality challenge posed by data augmentation, which scales with the number of observations and clients, we develop a factorized amortized variational approximation that achieves scalability independent of the number of observations. We showcase the efficacy of our framework through extensive numerical experiments on logistic regression, multilevel regression, and a novel hierarchical Bayesian split neural net model. Our work paves the way for privacy-preserving, decentralized Bayesian inference in vertically partitioned data scenarios, opening up new avenues for research and applications in various domains.
Optimal partitioning of directed acyclic graphs with dependent costs between clusters
Aug 08, 2023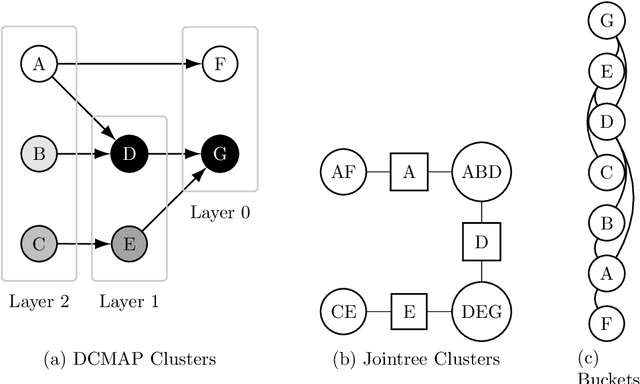
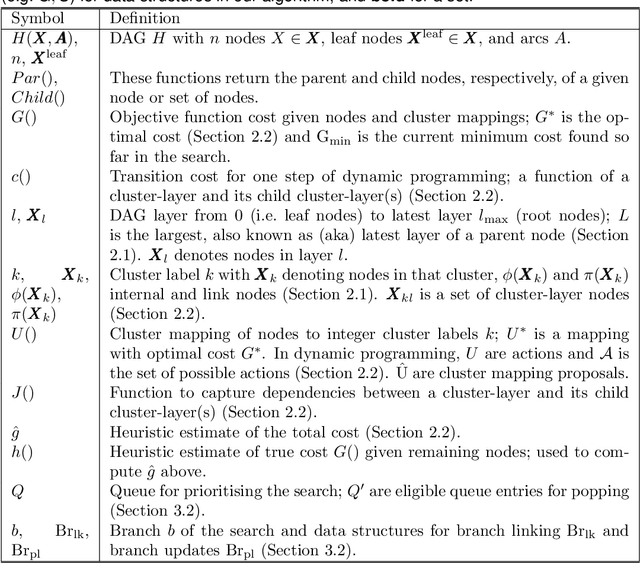

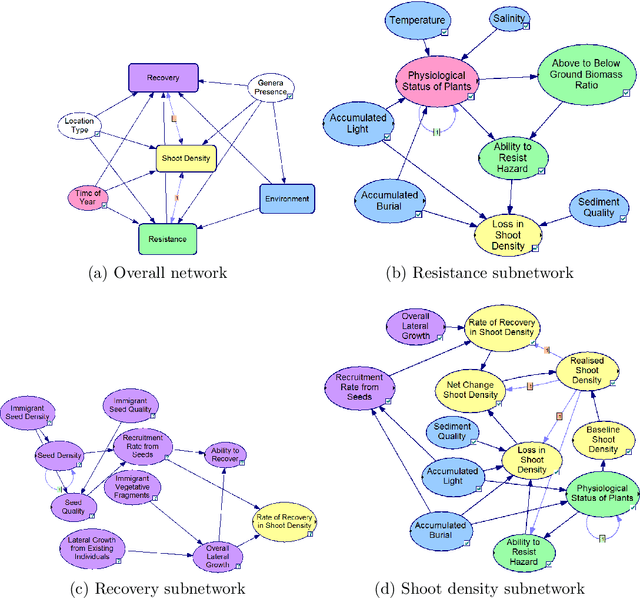
Many statistical inference contexts, including Bayesian Networks (BNs), Markov processes and Hidden Markov Models (HMMS) could be supported by partitioning (i.e.~mapping) the underlying Directed Acyclic Graph (DAG) into clusters. However, optimal partitioning is challenging, especially in statistical inference as the cost to be optimised is dependent on both nodes within a cluster, and the mapping of clusters connected via parent and/or child nodes, which we call dependent clusters. We propose a novel algorithm called DCMAP for optimal cluster mapping with dependent clusters. Given an arbitrarily defined, positive cost function based on the DAG and cluster mappings, we show that DCMAP converges to find all optimal clusters, and returns near-optimal solutions along the way. Empirically, we find that the algorithm is time-efficient for a DBN model of a seagrass complex system using a computation cost function. For a 25 and 50-node DBN, the search space size was $9.91\times 10^9$ and $1.51\times10^{21}$ possible cluster mappings, respectively, but near-optimal solutions with 88\% and 72\% similarity to the optimal solution were found at iterations 170 and 865, respectively. The first optimal solution was found at iteration 934 $(\text{95\% CI } 926,971)$, and 2256 $(2150,2271)$ with a cost that was 4\% and 0.2\% of the naive heuristic cost, respectively.
Deep Generative Models, Synthetic Tabular Data, and Differential Privacy: An Overview and Synthesis
Jul 28, 2023This article provides a comprehensive synthesis of the recent developments in synthetic data generation via deep generative models, focusing on tabular datasets. We specifically outline the importance of synthetic data generation in the context of privacy-sensitive data. Additionally, we highlight the advantages of using deep generative models over other methods and provide a detailed explanation of the underlying concepts, including unsupervised learning, neural networks, and generative models. The paper covers the challenges and considerations involved in using deep generative models for tabular datasets, such as data normalization, privacy concerns, and model evaluation. This review provides a valuable resource for researchers and practitioners interested in synthetic data generation and its applications.
Assessing the Spatial Structure of the Association between Attendance at Preschool and Childrens Developmental Vulnerabilities in Queensland Australia
May 25, 2023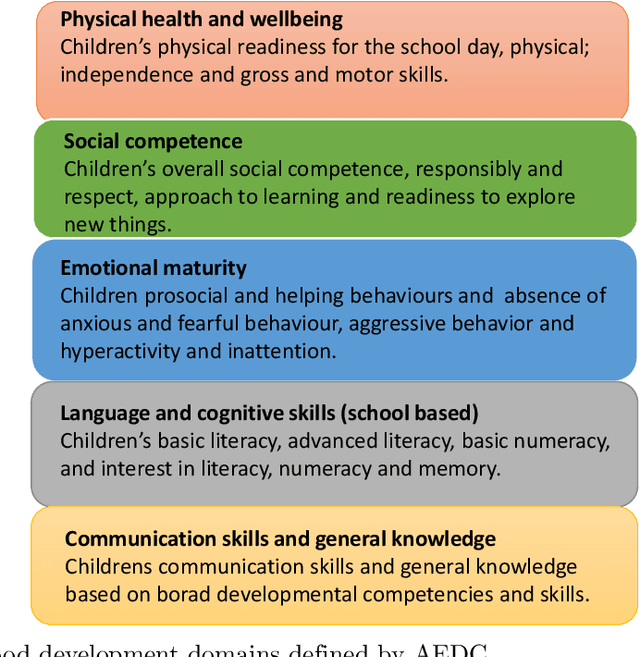
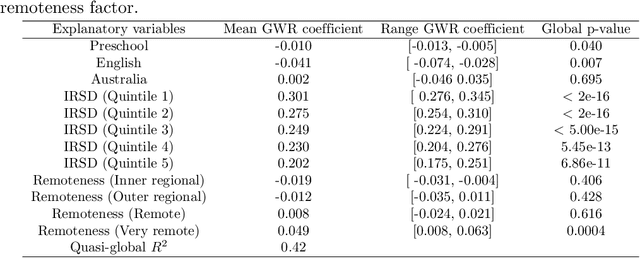
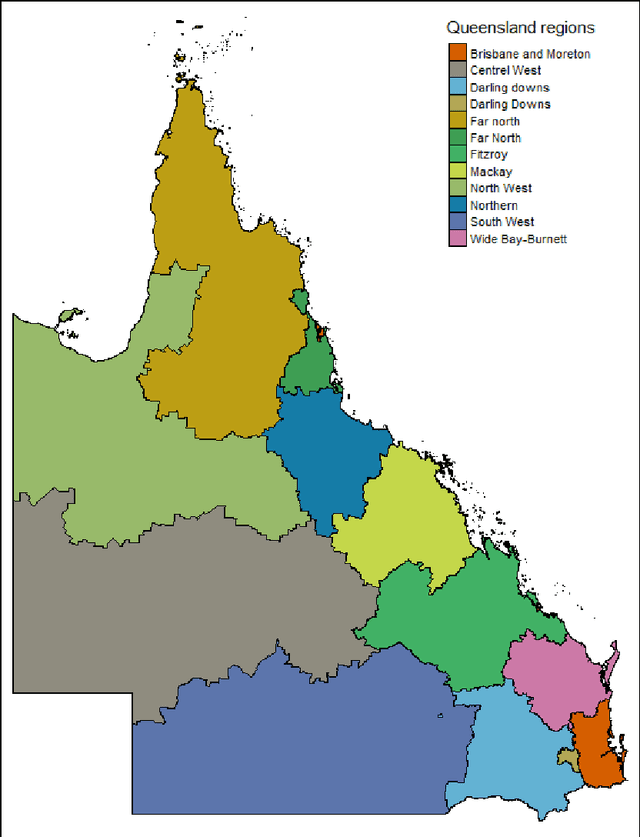
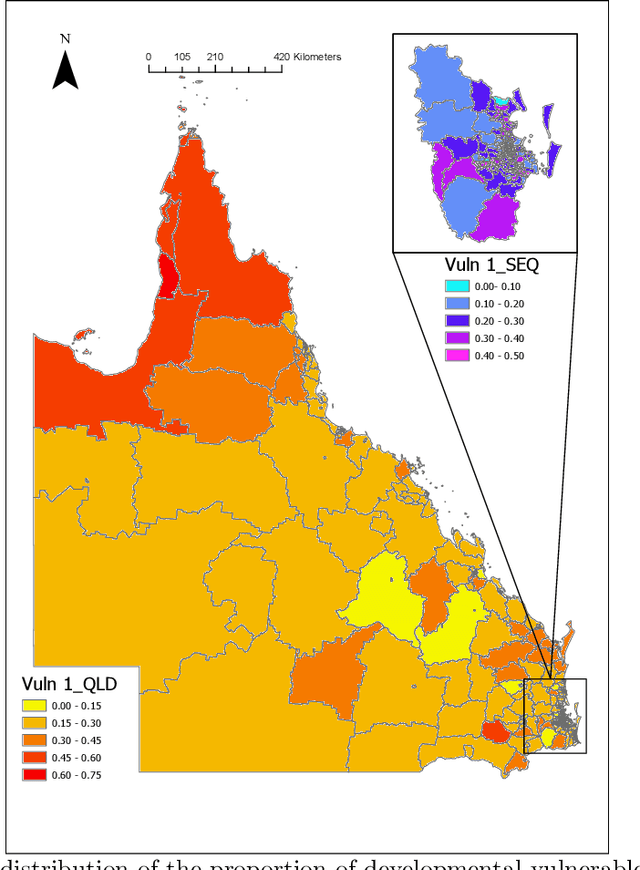
The research explores the influence of preschool attendance (one year before full-time school) on the development of children during their first year of school. Using data collected by the Australian Early Development Census, the findings show that areas with high proportions of preschool attendance tended to have lower proportions of children with at least one developmental vulnerability. Developmental vulnerablities include not being able to cope with the school day (tired, hungry, low energy), unable to get along with others or aggressive behaviour, trouble with reading/writing or numbers. These findings, of course, vary by region. Using Data Analysis and Machine Learning, the researchers were able to identify three distinct clusters within Queensland, each characterised by different socio-demographic variables influencing the relationship between preschool attendance and developmental vulnerability. These analyses contribute to understanding regions with high vulnerability and the potential need for tailored policies or investments
Graph Neural Network-Based Anomaly Detection for River Network Systems
Apr 20, 2023

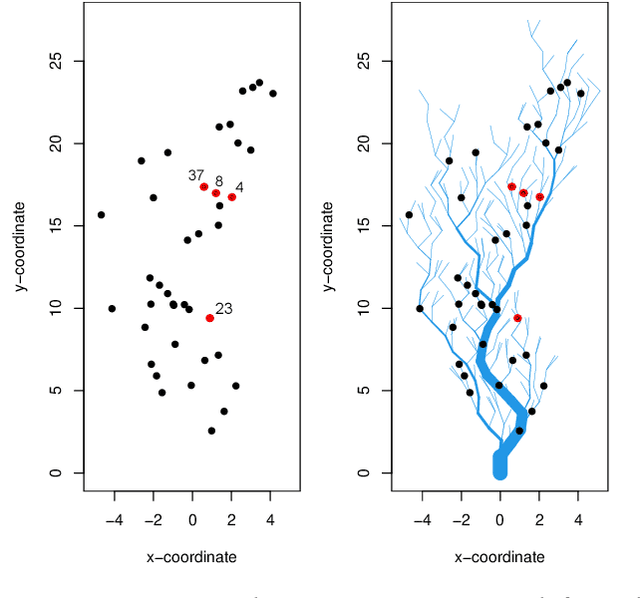

Water is the lifeblood of river networks, and its quality plays a crucial role in sustaining both aquatic ecosystems and human societies. Real-time monitoring of water quality is increasingly reliant on in-situ sensor technology. Anomaly detection is crucial for identifying erroneous patterns in sensor data, but can be a challenging task due to the complexity and variability of the data, even under normal conditions. This paper presents a solution to the challenging task of anomaly detection for river network sensor data, which is essential for accurate and continuous monitoring. We use a graph neural network model, the recently proposed Graph Deviation Network (GDN), which employs graph attention-based forecasting to capture the complex spatio-temporal relationships between sensors. We propose an alternate anomaly scoring method, GDN+, based on the learned graph. To evaluate the model's efficacy, we introduce new benchmarking simulation experiments with highly-sophisticated dependency structures and subsequence anomalies of various types. We further examine the strengths and weaknesses of this baseline approach, GDN, in comparison to other benchmarking methods on complex real-world river network data. Findings suggest that GDN+ outperforms the baseline approach in high-dimensional data, while also providing improved interpretability. We also introduce software called gnnad.
Piecewise Deterministic Markov Processes for Bayesian Neural Networks
Feb 17, 2023Inference on modern Bayesian Neural Networks (BNNs) often relies on a variational inference treatment, imposing violated assumptions of independence and the form of the posterior. Traditional MCMC approaches avoid these assumptions at the cost of increased computation due to its incompatibility to subsampling of the likelihood. New Piecewise Deterministic Markov Process (PDMP) samplers permit subsampling, though introduce a model specific inhomogenous Poisson Process (IPPs) which is difficult to sample from. This work introduces a new generic and adaptive thinning scheme for sampling from these IPPs, and demonstrates how this approach can accelerate the application of PDMPs for inference in BNNs. Experimentation illustrates how inference with these methods is computationally feasible, can improve predictive accuracy, MCMC mixing performance, and provide informative uncertainty measurements when compared against other approximate inference schemes.
Federated Variational Inference Methods for Structured Latent Variable Models
Feb 07, 2023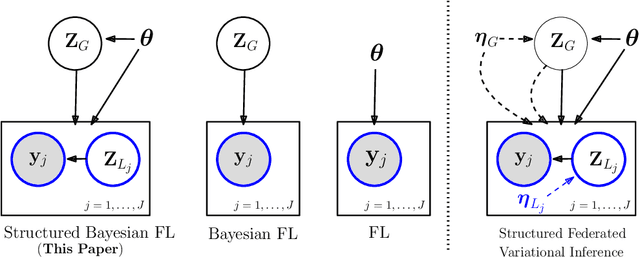
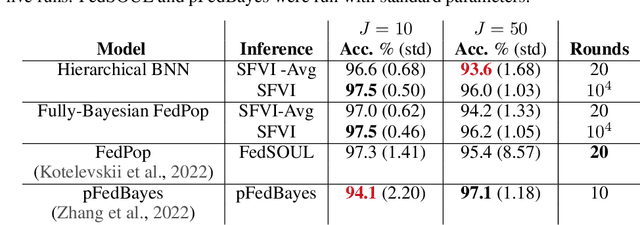
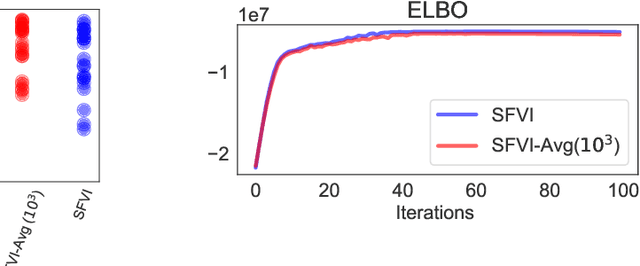
Federated learning methods, that is, methods that perform model training using data situated across different sources, whilst simultaneously not having the data leave their original source, are of increasing interest in a number of fields. However, despite this interest, the classes of models for which easily-applicable and sufficiently general approaches are available is limited, excluding many structured probabilistic models. We present a general yet elegant resolution to the aforementioned issue. The approach is based on adopting structured variational inference, an approach widely used in Bayesian machine learning, to the federated setting. Additionally, a communication-efficient variant analogous to the canonical FedAvg algorithm is explored. The effectiveness of the proposed algorithms are demonstrated, and their performance is compared on Bayesian multinomial regression, topic modelling, and mixed model examples.
A variational autoencoder-based nonnegative matrix factorisation model for deep dictionary learning
Jan 18, 2023



Construction of dictionaries using nonnegative matrix factorisation (NMF) has extensive applications in signal processing and machine learning. With the advances in deep learning, training compact and robust dictionaries using deep neural networks, i.e., dictionaries of deep features, has been proposed. In this study, we propose a probabilistic generative model which employs a variational autoencoder (VAE) to perform nonnegative dictionary learning. In contrast to the existing VAE models, we cast the model under a statistical framework with latent variables obeying a Gamma distribution and design a new loss function to guarantee the nonnegative dictionaries. We adopt an acceptance-rejection sampling reparameterization trick to update the latent variables iteratively. We apply the dictionaries learned from VAE-NMF to two signal processing tasks, i.e., enhancement of speech and extraction of muscle synergies. Experimental results demonstrate that VAE-NMF performs better in learning the latent nonnegative dictionaries in comparison with state-of-the-art methods.