 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Neural Network-Based Anomaly Detection for River Network Systems
Apr 20, 2023

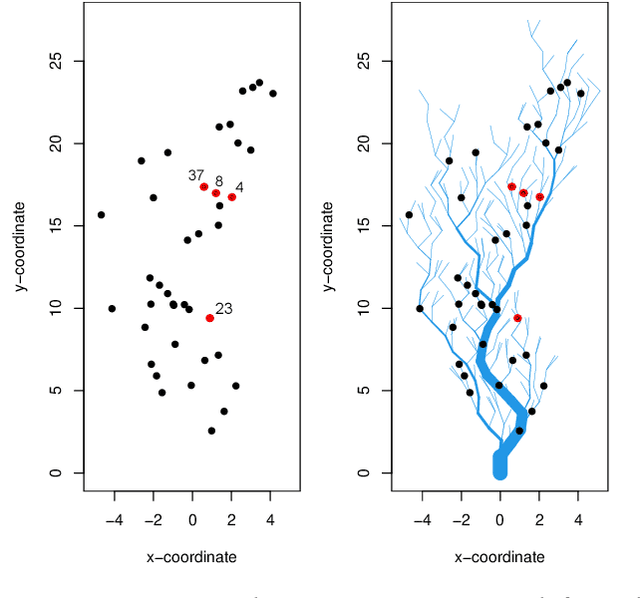

Water is the lifeblood of river networks, and its quality plays a crucial role in sustaining both aquatic ecosystems and human societies. Real-time monitoring of water quality is increasingly reliant on in-situ sensor technology. Anomaly detection is crucial for identifying erroneous patterns in sensor data, but can be a challenging task due to the complexity and variability of the data, even under normal conditions. This paper presents a solution to the challenging task of anomaly detection for river network sensor data, which is essential for accurate and continuous monitoring. We use a graph neural network model, the recently proposed Graph Deviation Network (GDN), which employs graph attention-based forecasting to capture the complex spatio-temporal relationships between sensors. We propose an alternate anomaly scoring method, GDN+, based on the learned graph. To evaluate the model's efficacy, we introduce new benchmarking simulation experiments with highly-sophisticated dependency structures and subsequence anomalies of various types. We further examine the strengths and weaknesses of this baseline approach, GDN, in comparison to other benchmarking methods on complex real-world river network data. Findings suggest that GDN+ outperforms the baseline approach in high-dimensional data, while also providing improved interpretability. We also introduce software called gnnad.
clusterBMA: Bayesian model averaging for clustering
Sep 09, 2022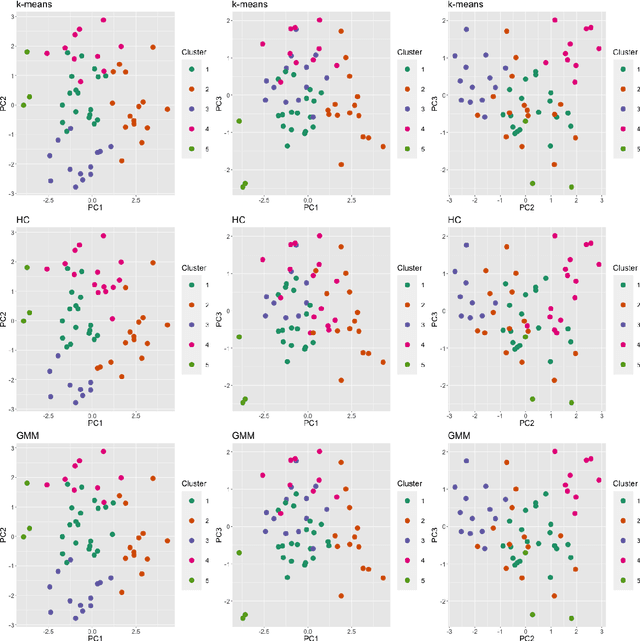
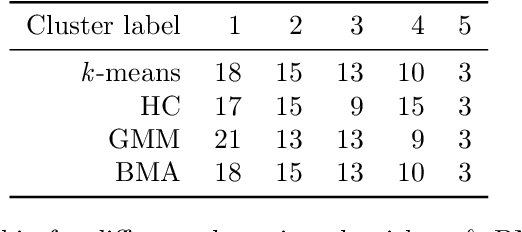
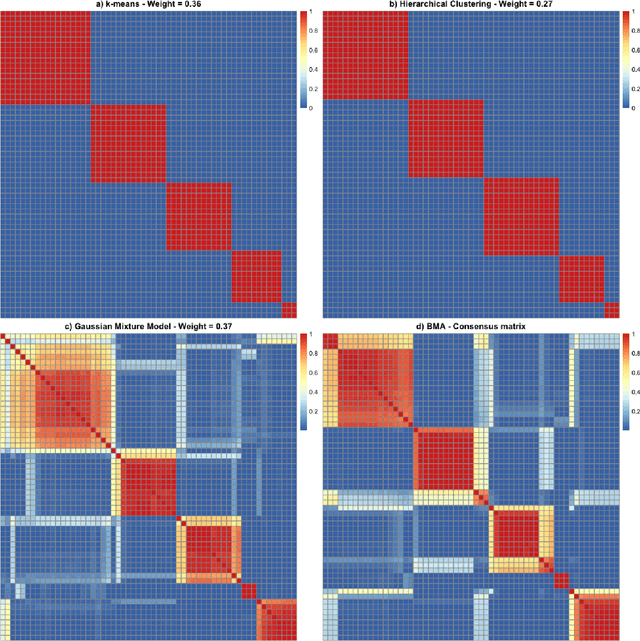
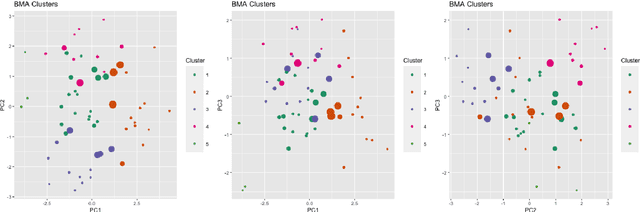
Various methods have been developed to combine inference across multiple sets of results for unsupervised clustering, within the ensemble and consensus clustering literature. The approach of reporting results from one `best' model out of several candidate clustering models generally ignores the uncertainty that arises from model selection, and results in inferences that are sensitive to the particular model and parameters chosen, and assumptions made, especially with small sample size or small cluster sizes. Bayesian model averaging (BMA) is a popular approach for combining results across multiple models that offers some attractive benefits in this setting, including probabilistic interpretation of the combine cluster structure and quantification of model-based uncertainty. In this work we introduce clusterBMA, a method that enables weighted model averaging across results from multiple unsupervised clustering algorithms. We use a combination of clustering internal validation criteria as a novel approximation of the posterior model probability for weighting the results from each model. From a combined posterior similarity matrix representing a weighted average of the clustering solutions across models, we apply symmetric simplex matrix factorisation to calculate final probabilistic cluster allocations. This method is implemented in an accompanying R package. We explore the performance of this approach through a case study that aims to to identify probabilistic clusters of individuals based on electroencephalography (EEG) data. We also use simulated datasets to explore the ability of the proposed technique to identify robust integrated clusters with varying levels of separations between subgroups, and with varying numbers of clusters between models.
On the intrinsic dimensionality of Covid-19 data: a global perspective
Mar 08, 2022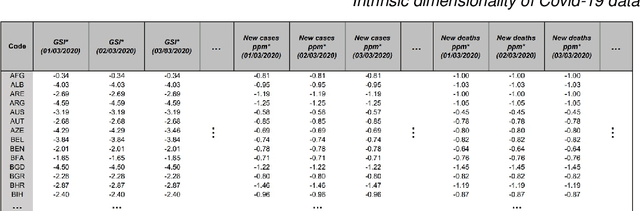
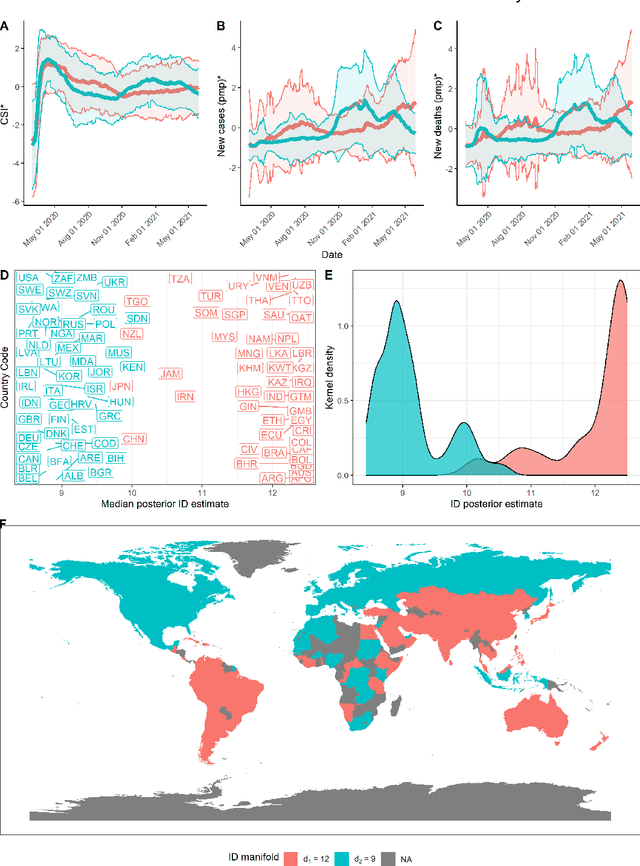
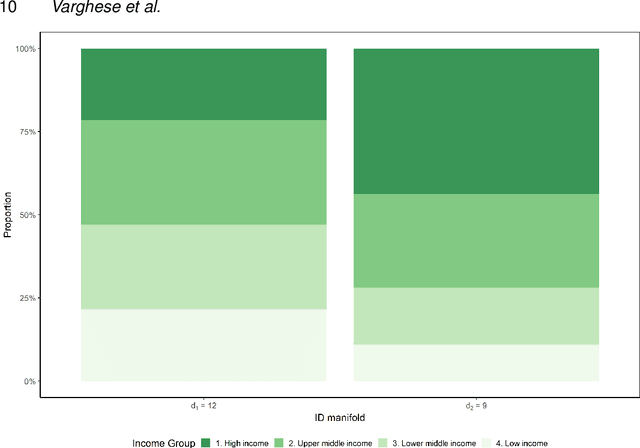
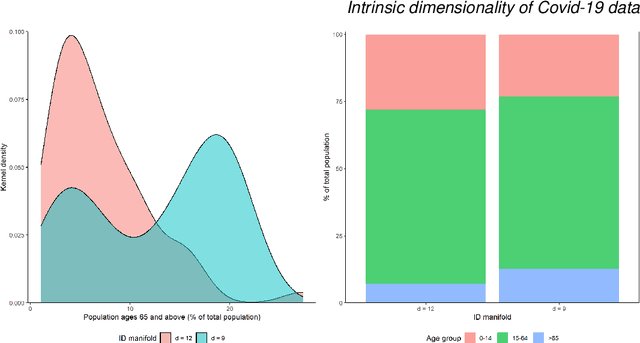
This paper aims to develop a global perspective of the complexity of the relationship between the standardised per-capita growth rate of Covid-19 cases, deaths, and the OxCGRT Covid-19 Stringency Index, a measure describing a country's stringency of lockdown policies. To achieve our goal, we use a heterogeneous intrinsic dimension estimator implemented as a Bayesian mixture model, called Hidalgo. We identify that the Covid-19 dataset may project onto two low-dimensional manifolds without significant information loss. The low dimensionality suggests strong dependency among the standardised growth rates of cases and deaths per capita and the OxCGRT Covid-19 Stringency Index for a country over 2020-2021. Given the low dimensional structure, it may be feasible to model observable Covid-19 dynamics with few parameters. Importantly, we identify spatial autocorrelation in the intrinsic dimension distribution worldwide. Moreover, we highlight that high-income countries are more likely to lie on low-dimensional manifolds, likely arising from aging populations, comorbidities, and increased per capita mortality burden from Covid-19. Finally, we temporally stratify the dataset to examine the intrinsic dimension at a more granular level throughout the Covid-19 pandemic.