 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal partitioning of directed acyclic graphs with dependent costs between clusters
Aug 08, 2023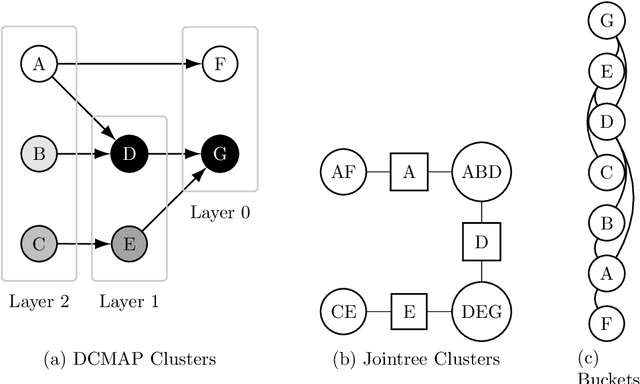

Many statistical inference contexts, including Bayesian Networks (BNs), Markov processes and Hidden Markov Models (HMMS) could be supported by partitioning (i.e.~mapping) the underlying Directed Acyclic Graph (DAG) into clusters. However, optimal partitioning is challenging, especially in statistical inference as the cost to be optimised is dependent on both nodes within a cluster, and the mapping of clusters connected via parent and/or child nodes, which we call dependent clusters. We propose a novel algorithm called DCMAP for optimal cluster mapping with dependent clusters. Given an arbitrarily defined, positive cost function based on the DAG and cluster mappings, we show that DCMAP converges to find all optimal clusters, and returns near-optimal solutions along the way. Empirically, we find that the algorithm is time-efficient for a DBN model of a seagrass complex system using a computation cost function. For a 25 and 50-node DBN, the search space size was $9.91\times 10^9$ and $1.51\times10^{21}$ possible cluster mappings, respectively, but near-optimal solutions with 88\% and 72\% similarity to the optimal solution were found at iterations 170 and 865, respectively. The first optimal solution was found at iteration 934 $(\text{95\% CI } 926,971)$, and 2256 $(2150,2271)$ with a cost that was 4\% and 0.2\% of the naive heuristic cost, respectively.
clusterBMA: Bayesian model averaging for clustering
Sep 09, 2022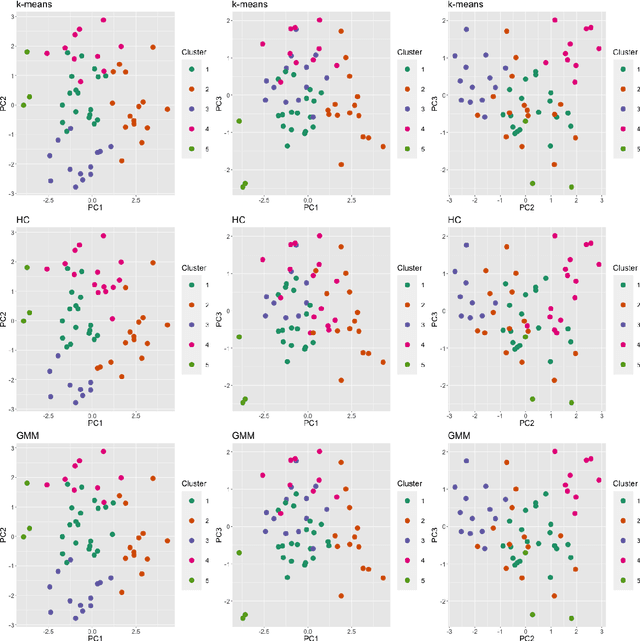
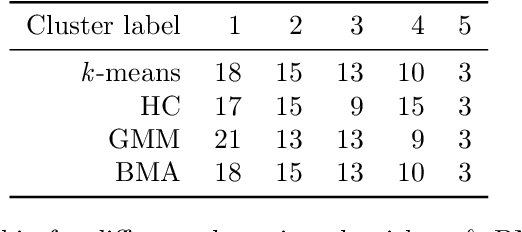
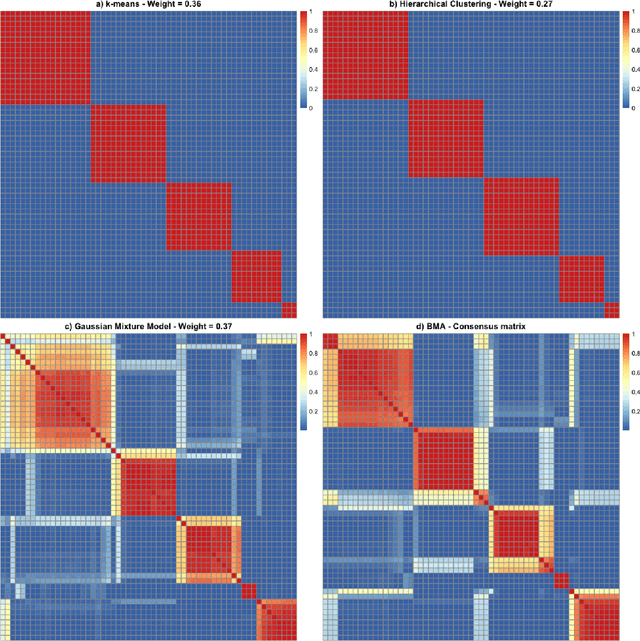
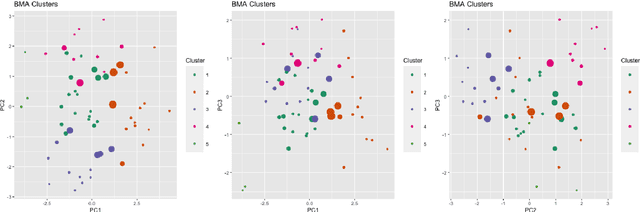
Various methods have been developed to combine inference across multiple sets of results for unsupervised clustering, within the ensemble and consensus clustering literature. The approach of reporting results from one `best' model out of several candidate clustering models generally ignores the uncertainty that arises from model selection, and results in inferences that are sensitive to the particular model and parameters chosen, and assumptions made, especially with small sample size or small cluster sizes. Bayesian model averaging (BMA) is a popular approach for combining results across multiple models that offers some attractive benefits in this setting, including probabilistic interpretation of the combine cluster structure and quantification of model-based uncertainty. In this work we introduce clusterBMA, a method that enables weighted model averaging across results from multiple unsupervised clustering algorithms. We use a combination of clustering internal validation criteria as a novel approximation of the posterior model probability for weighting the results from each model. From a combined posterior similarity matrix representing a weighted average of the clustering solutions across models, we apply symmetric simplex matrix factorisation to calculate final probabilistic cluster allocations. This method is implemented in an accompanying R package. We explore the performance of this approach through a case study that aims to to identify probabilistic clusters of individuals based on electroencephalography (EEG) data. We also use simulated datasets to explore the ability of the proposed technique to identify robust integrated clusters with varying levels of separations between subgroups, and with varying numbers of clusters between models.