 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCytoarchitecture in Words: Weakly Supervised Vision-Language Modeling for Human Brain Microscopy
Feb 26, 2026Foundation models increasingly offer potential to support interactive, agentic workflows that assist researchers during analysis and interpretation of image data. Such workflows often require coupling vision to language to provide a natural-language interface. However, paired image-text data needed to learn this coupling are scarce and difficult to obtain in many research and clinical settings. One such setting is microscopic analysis of cell-body-stained histological human brain sections, which enables the study of cytoarchitecture: cell density and morphology and their laminar and areal organization. Here, we propose a label-mediated method that generates meaningful captions from images by linking images and text only through a label, without requiring curated paired image-text data. Given the label, we automatically mine area descriptions from related literature and use them as synthetic captions reflecting canonical cytoarchitectonic attributes. An existing cytoarchitectonic vision foundation model (CytoNet) is then coupled to a large language model via an image-to-text training objective, enabling microscopy regions to be described in natural language. Across 57 brain areas, the resulting method produces plausible area-level descriptions and supports open-set use through explicit rejection of unseen areas. It matches the cytoarchitectonic reference label for in-scope patches with 90.6% accuracy and, with the area label masked, its descriptions remain discriminative enough to recover the area in an 8-way test with 68.6% accuracy. These results suggest that weak, label-mediated pairing can suffice to connect existing biomedical vision foundation models to language, providing a practical recipe for integrating natural-language in domains where fine-grained paired annotations are scarce.
The Polynomial Stein Discrepancy for Assessing Moment Convergence
Dec 06, 2024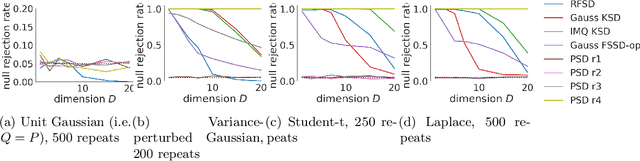
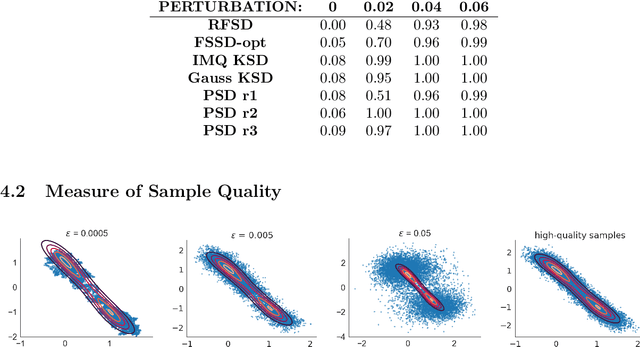
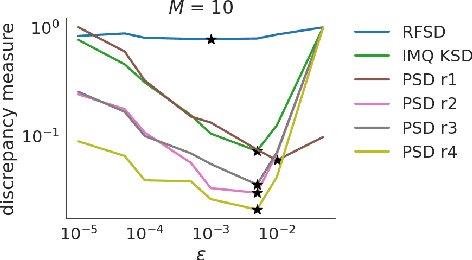
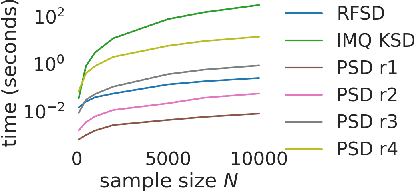
We propose a novel method for measuring the discrepancy between a set of samples and a desired posterior distribution for Bayesian inference. Classical methods for assessing sample quality like the effective sample size are not appropriate for scalable Bayesian sampling algorithms, such as stochastic gradient Langevin dynamics, that are asymptotically biased. Instead, the gold standard is to use the kernel Stein Discrepancy (KSD), which is itself not scalable given its quadratic cost in the number of samples. The KSD and its faster extensions also typically suffer from the curse-of-dimensionality and can require extensive tuning. To address these limitations, we develop the polynomial Stein discrepancy (PSD) and an associated goodness-of-fit test. While the new test is not fully convergence-determining, we prove that it detects differences in the first r moments in the Bernstein-von Mises limit. We empirically show that the test has higher power than its competitors in several examples, and at a lower computational cost. Finally, we demonstrate that the PSD can assist practitioners to select hyper-parameters of Bayesian sampling algorithms more efficiently than competitors.
Scalable Vertical Federated Learning via Data Augmentation and Amortized Inference
May 07, 2024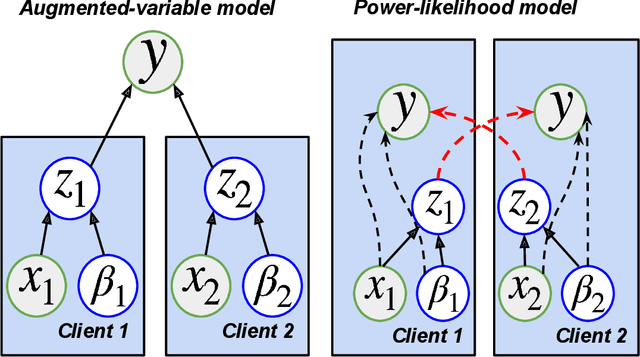


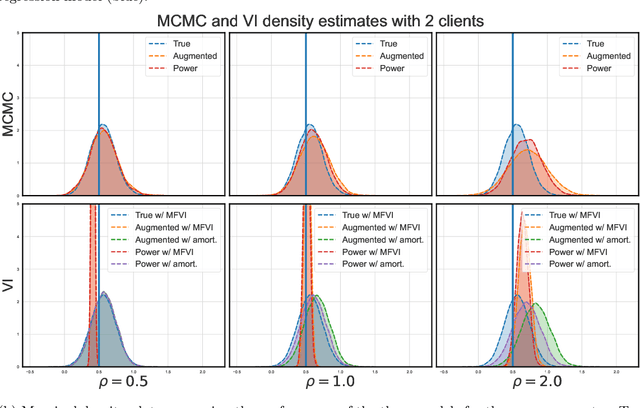
Vertical federated learning (VFL) has emerged as a paradigm for collaborative model estimation across multiple clients, each holding a distinct set of covariates. This paper introduces the first comprehensive framework for fitting Bayesian models in the VFL setting. We propose a novel approach that leverages data augmentation techniques to transform VFL problems into a form compatible with existing Bayesian federated learning algorithms. We present an innovative model formulation for specific VFL scenarios where the joint likelihood factorizes into a product of client-specific likelihoods. To mitigate the dimensionality challenge posed by data augmentation, which scales with the number of observations and clients, we develop a factorized amortized variational approximation that achieves scalability independent of the number of observations. We showcase the efficacy of our framework through extensive numerical experiments on logistic regression, multilevel regression, and a novel hierarchical Bayesian split neural net model. Our work paves the way for privacy-preserving, decentralized Bayesian inference in vertically partitioned data scenarios, opening up new avenues for research and applications in various domains.
Transport Reversible Jump Proposals
Oct 22, 2022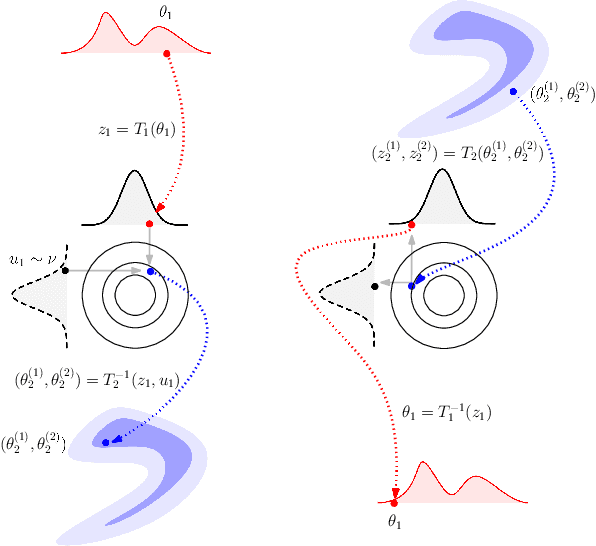
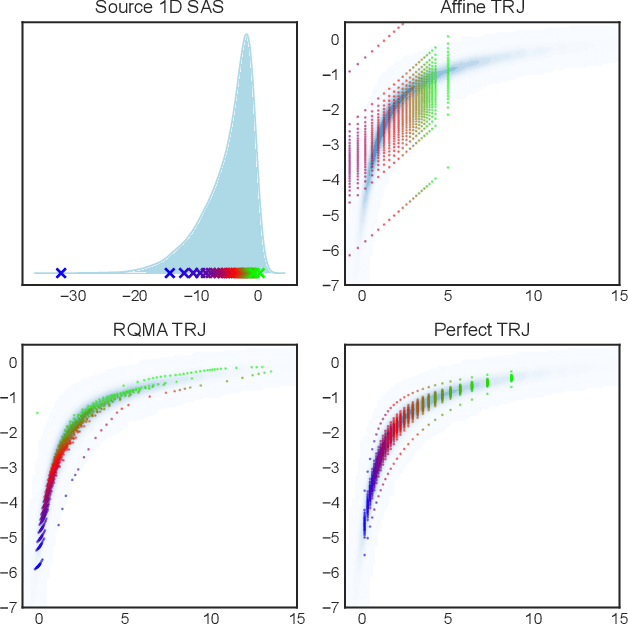
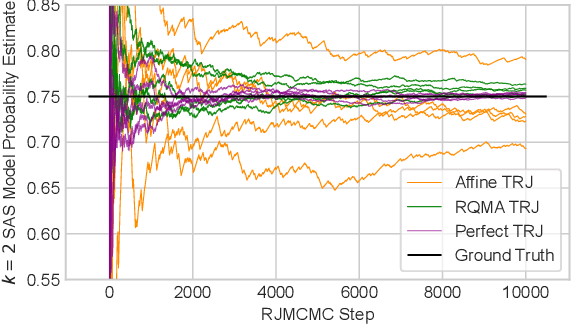
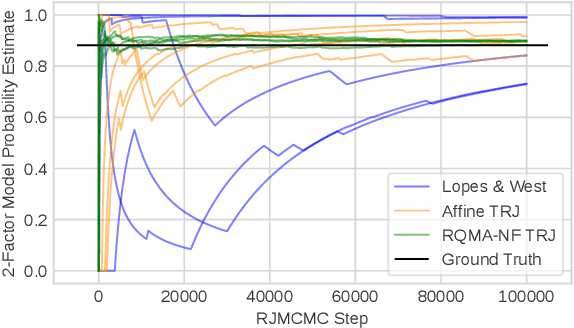
Reversible jump Markov chain Monte Carlo (RJMCMC) proposals that achieve reasonable acceptance rates and mixing are notoriously difficult to design in most applications. Inspired by recent advances in deep neural network-based normalizing flows and density estimation, we demonstrate an approach to enhance the efficiency of RJMCMC sampling by performing transdimensional jumps involving reference distributions. In contrast to other RJMCMC proposals, the proposed method is the first to apply a non-linear transport-based approach to construct efficient proposals between models with complicated dependency structures. It is shown that, in the setting where exact transports are used, our RJMCMC proposals have the desirable property that the acceptance probability depends only on the model probabilities. Numerical experiments demonstrate the efficacy of the approach.
Continuously-Tempered PDMP Samplers
May 29, 2022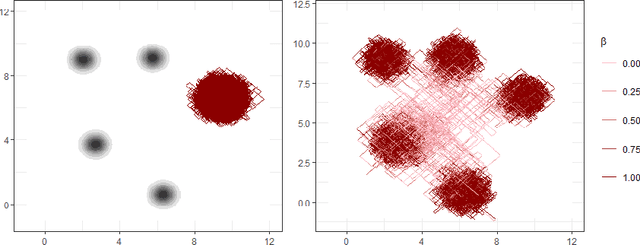
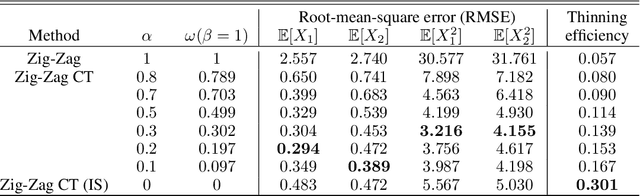
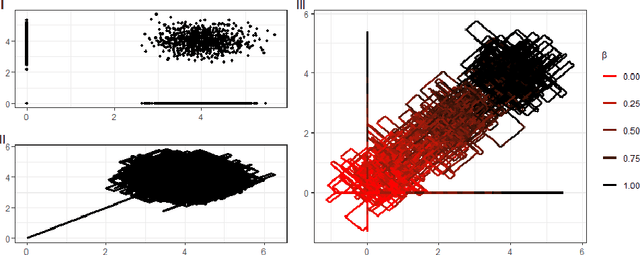
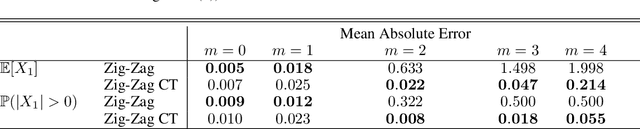
New sampling algorithms based on simulating continuous-time stochastic processes called piece-wise deterministic Markov processes (PDMPs) have shown considerable promise. However, these methods can struggle to sample from multi-modal or heavy-tailed distributions. We show how tempering ideas can improve the mixing of PDMPs in such cases. We introduce an extended distribution defined over the state of the posterior distribution and an inverse temperature, which interpolates between a tractable distribution when the inverse temperature is 0 and the posterior when the inverse temperature is 1. The marginal distribution of the inverse temperature is a mixture of a continuous distribution on [0,1) and a point mass at 1: which means that we obtain samples when the inverse temperature is 1, and these are draws from the posterior, but sampling algorithms will also explore distributions at lower temperatures which will improve mixing. We show how PDMPs, and particularly the Zig-Zag sampler, can be implemented to sample from such an extended distribution. The resulting algorithm is easy to implement and we show empirically that it can outperform existing PDMP-based samplers on challenging multimodal posteriors.
Reversible Jump PDMP Samplers for Variable Selection
Oct 22, 2020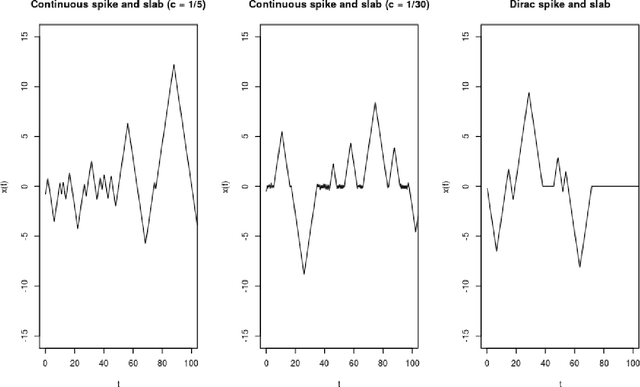
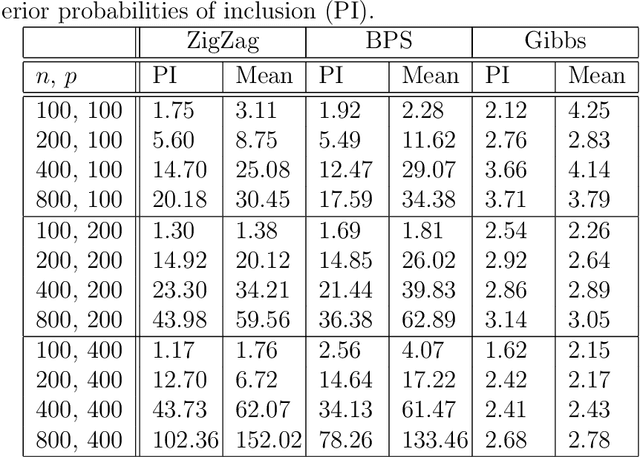
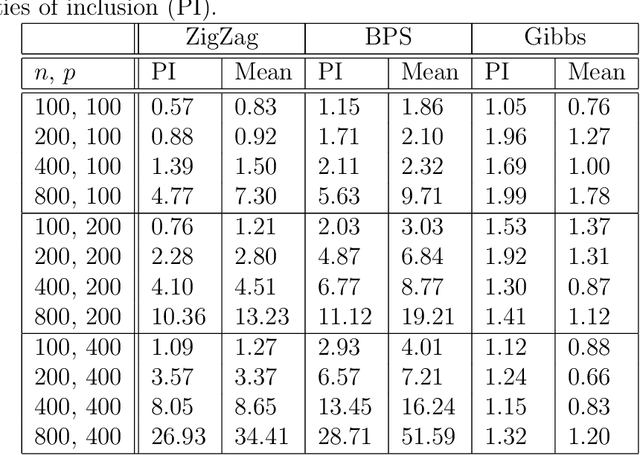
A new class of Markov chain Monte Carlo (MCMC) algorithms, based on simulating piecewise deterministic Markov processes (PDMPs), have recently shown great promise: they are non-reversible, can mix better than standard MCMC algorithms, and can use subsampling ideas to speed up computation in big data scenarios. However, current PDMP samplers can only sample from posterior densities that are differentiable almost everywhere, which precludes their use for model choice. Motivated by variable selection problems, we show how to develop reversible jump PDMP samplers that can jointly explore the discrete space of models and the continuous space of parameters. Our framework is general: it takes any existing PDMP sampler, and adds two types of trans-dimensional moves that allow for the addition or removal of a variable from the model. We show how the rates of these trans-dimensional moves can be calculated so that the sampler has the correct invariant distribution. Simulations show that the new samplers can mix better than standard MCMC algorithms. Our empirical results show they are also more efficient than gradient-based samplers that avoid model choice through use of continuous spike-and-slab priors which replace a point mass at zero for each parameter with a density concentrated around zero.
A Unified Parallel Algorithm for Regularized Group PLS Scalable to Big Data
Feb 23, 2017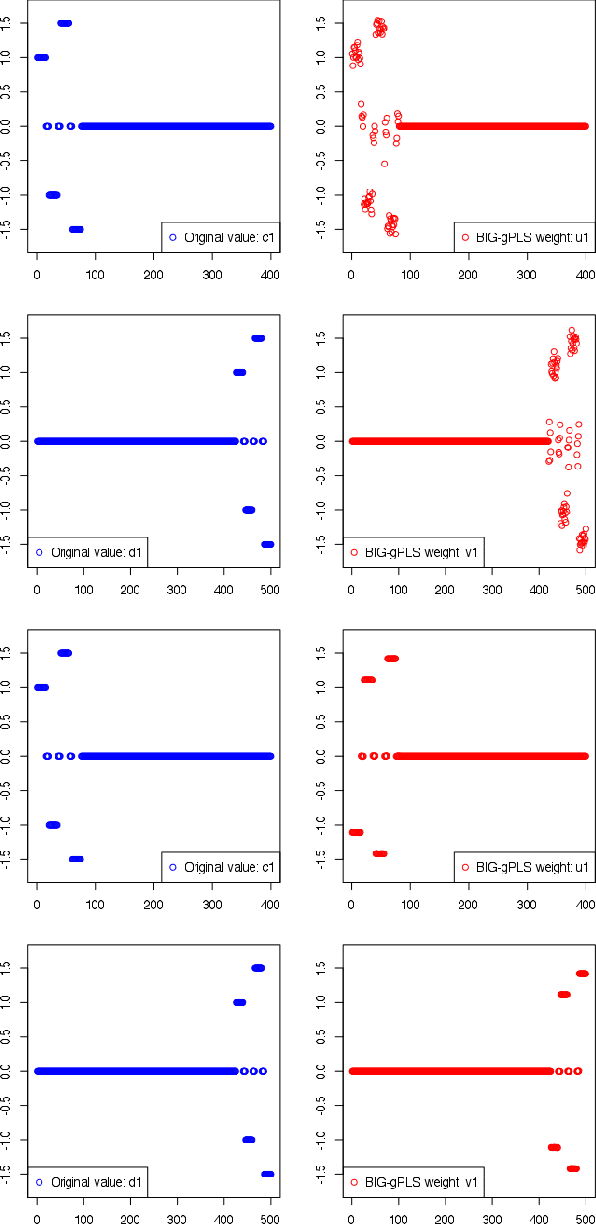
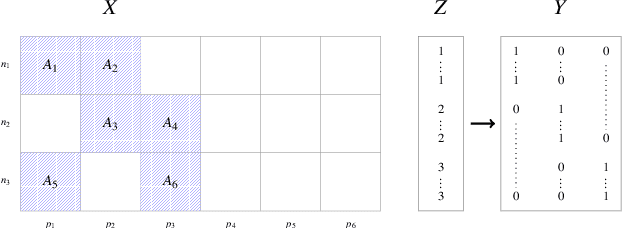
Partial Least Squares (PLS) methods have been heavily exploited to analyse the association between two blocs of data. These powerful approaches can be applied to data sets where the number of variables is greater than the number of observations and in presence of high collinearity between variables. Different sparse versions of PLS have been developed to integrate multiple data sets while simultaneously selecting the contributing variables. Sparse modelling is a key factor in obtaining better estimators and identifying associations between multiple data sets. The cornerstone of the sparsity version of PLS methods is the link between the SVD of a matrix (constructed from deflated versions of the original matrices of data) and least squares minimisation in linear regression. We present here an accurate description of the most popular PLS methods, alongside their mathematical proofs. A unified algorithm is proposed to perform all four types of PLS including their regularised versions. Various approaches to decrease the computation time are offered, and we show how the whole procedure can be scalable to big data sets.