 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTempered Guided Diffusion
May 05, 2026Training-free conditional diffusion provides a flexible alternative to task-specific conditional model training, but existing samplers often allocate computation inefficiently: independent guided trajectories can vary widely in quality, and additional function evaluations along a single trajectory may not recover from poor early decisions. We propose Tempered Guided Diffusion (TGD), an annealed sequential Monte Carlo framework for training-free conditional sampling with diffusion priors. TGD targets tempered posterior distributions over the clean signal, using noisy diffusion states only as auxiliary variables for proposing reconstructions and propagating particles. Particles are reweighted by incremental likelihood ratios, resampled, and propagated across noise levels, concentrating computation on trajectories plausible under both the prior and observation. Under idealized exact-reconstruction assumptions, full TGD yields a consistent particle approximation to the posterior as the number of particles grows. For expensive reconstruction tasks, Accelerated TGD (A-TGD) retains early particle exploration but prunes to a single high-likelihood trajectory partway through sampling. Experiments on a controlled two-dimensional inverse problem and image inverse problems show improved posterior approximation and favorable wall-clock speed-quality tradeoffs over independent multi-trajectory baselines.
Scalable Model-Based Clustering with Sequential Monte Carlo
Apr 16, 2026In online clustering problems, there is often a large amount of uncertainty over possible cluster assignments that cannot be resolved until more data are observed. This difficulty is compounded when clusters follow complex distributions, as is the case with text data. Sequential Monte Carlo (SMC) methods give a natural way of representing and updating this uncertainty over time, but have prohibitive memory requirements for large-scale problems. We propose a novel SMC algorithm that decomposes clustering problems into approximately independent subproblems, allowing a more compact representation of the algorithm state. Our approach is motivated by the knowledge base construction problem, and we show that our method is able to accurately and efficiently solve clustering problems in this setting and others where traditional SMC struggles.
Scalable Monte Carlo for Bayesian Learning
Jul 17, 2024



This book aims to provide a graduate-level introduction to advanced topics in Markov chain Monte Carlo (MCMC) algorithms, as applied broadly in the Bayesian computational context. Most, if not all of these topics (stochastic gradient MCMC, non-reversible MCMC, continuous time MCMC, and new techniques for convergence assessment) have emerged as recently as the last decade, and have driven substantial recent practical and theoretical advances in the field. A particular focus is on methods that are scalable with respect to either the amount of data, or the data dimension, motivated by the emerging high-priority application areas in machine learning and AI.
Stochastic Gradient Piecewise Deterministic Monte Carlo Samplers
Jun 27, 2024Recent work has suggested using Monte Carlo methods based on piecewise deterministic Markov processes (PDMPs) to sample from target distributions of interest. PDMPs are non-reversible continuous-time processes endowed with momentum, and hence can mix better than standard reversible MCMC samplers. Furthermore, they can incorporate exact sub-sampling schemes which only require access to a single (randomly selected) data point at each iteration, yet without introducing bias to the algorithm's stationary distribution. However, the range of models for which PDMPs can be used, particularly with sub-sampling, is limited. We propose approximate simulation of PDMPs with sub-sampling for scalable sampling from posterior distributions. The approximation takes the form of an Euler approximation to the true PDMP dynamics, and involves using an estimate of the gradient of the log-posterior based on a data sub-sample. We thus call this class of algorithms stochastic-gradient PDMPs. Importantly, the trajectories of stochastic-gradient PDMPs are continuous and can leverage recent ideas for sampling from measures with continuous and atomic components. We show these methods are easy to implement, present results on their approximation error and demonstrate numerically that this class of algorithms has similar efficiency to, but is more robust than, stochastic gradient Langevin dynamics.
A Constant-per-Iteration Likelihood Ratio Test for Online Changepoint Detection for Exponential Family Models
Feb 09, 2023Online changepoint detection algorithms that are based on likelihood-ratio tests have been shown to have excellent statistical properties. However, a simple online implementation is computationally infeasible as, at time $T$, it involves considering $O(T)$ possible locations for the change. Recently, the FOCuS algorithm has been introduced for detecting changes in mean in Gaussian data that decreases the per-iteration cost to $O(\log T)$. This is possible by using pruning ideas, which reduce the set of changepoint locations that need to be considered at time $T$ to approximately $\log T$. We show that if one wishes to perform the likelihood ratio test for a different one-parameter exponential family model, then exactly the same pruning rule can be used, and again one need only consider approximately $\log T$ locations at iteration $T$. Furthermore, we show how we can adaptively perform the maximisation step of the algorithm so that we need only maximise the test statistic over a small subset of these possible locations. Empirical results show that the resulting online algorithm, which can detect changes under a wide range of models, has a constant-per-iteration cost on average.
A Log-Linear Non-Parametric Online Changepoint Detection Algorithm based on Functional Pruning
Feb 06, 2023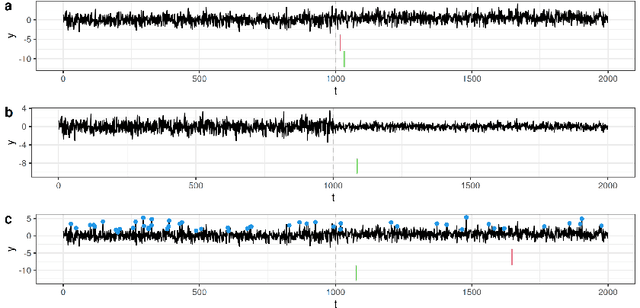
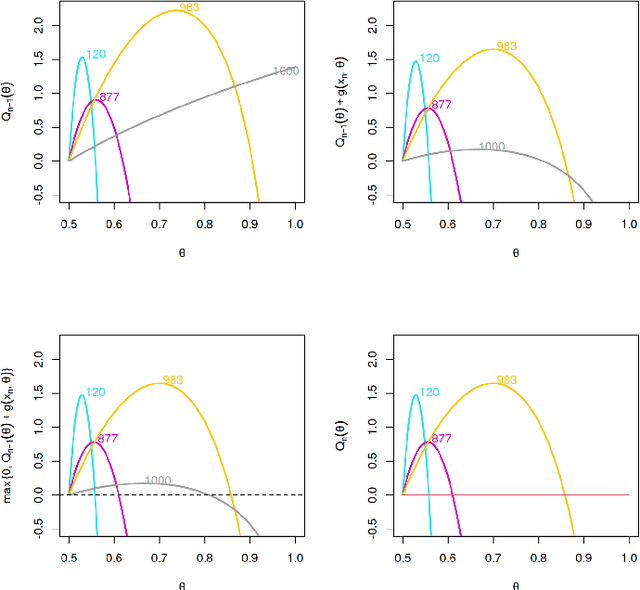
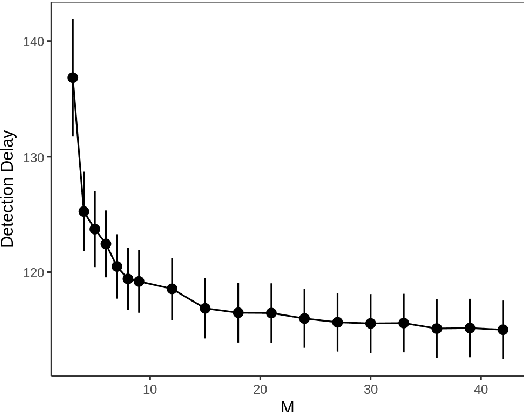
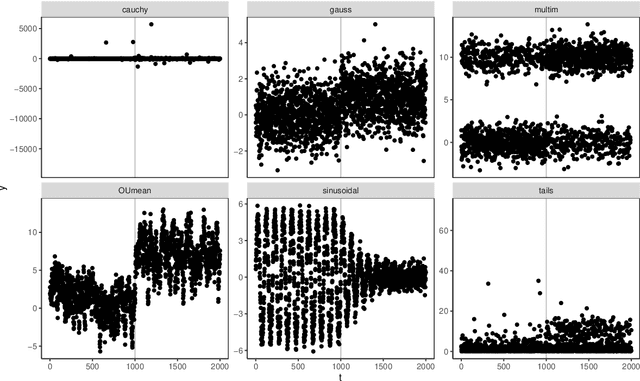
Online changepoint detection aims to detect anomalies and changes in real-time in high-frequency data streams, sometimes with limited available computational resources. This is an important task that is rooted in many real-world applications, including and not limited to cybersecurity, medicine and astrophysics. While fast and efficient online algorithms have been recently introduced, these rely on parametric assumptions which are often violated in practical applications. Motivated by data streams from the telecommunications sector, we build a flexible nonparametric approach to detect a change in the distribution of a sequence. Our procedure, NP-FOCuS, builds a sequential likelihood ratio test for a change in a set of points of the empirical cumulative density function of our data. This is achieved by keeping track of the number of observations above or below those points. Thanks to functional pruning ideas, NP-FOCuS has a computational cost that is log-linear in the number of observations and is suitable for high-frequency data streams. In terms of detection power, NP-FOCuS is seen to outperform current nonparametric online changepoint techniques in a variety of settings. We demonstrate the utility of the procedure on both simulated and real data.
Automatic Change-Point Detection in Time Series via Deep Learning
Nov 07, 2022Detecting change-points in data is challenging because of the range of possible types of change and types of behaviour of data when there is no change. Statistically efficient methods for detecting a change will depend on both of these features, and it can be difficult for a practitioner to develop an appropriate detection method for their application of interest. We show how to automatically generate new detection methods based on training a neural network. Our approach is motivated by many existing tests for the presence of a change-point being able to be represented by a simple neural network, and thus a neural network trained with sufficient data should have performance at least as good as these methods. We present theory that quantifies the error rate for such an approach, and how it depends on the amount of training data. Empirical results show that, even with limited training data, its performance is competitive with the standard CUSUM test for detecting a change in mean when the noise is independent and Gaussian, and can substantially outperform it in the presence of auto-correlated or heavy-tailed noise. Our method also shows strong results in detecting and localising changes in activity based on accelerometer data.
Preferential Subsampling for Stochastic Gradient Langevin Dynamics
Oct 28, 2022



Stochastic gradient MCMC (SGMCMC) offers a scalable alternative to traditional MCMC, by constructing an unbiased estimate of the gradient of the log-posterior with a small, uniformly-weighted subsample of the data. While efficient to compute, the resulting gradient estimator may exhibit a high variance and impact sampler performance. The problem of variance control has been traditionally addressed by constructing a better stochastic gradient estimator, often using control variates. We propose to use a discrete, non-uniform probability distribution to preferentially subsample data points that have a greater impact on the stochastic gradient. In addition, we present a method of adaptively adjusting the subsample size at each iteration of the algorithm, so that we increase the subsample size in areas of the sample space where the gradient is harder to estimate. We demonstrate that such an approach can maintain the same level of accuracy while substantially reducing the average subsample size that is used.
Continuously-Tempered PDMP Samplers
May 29, 2022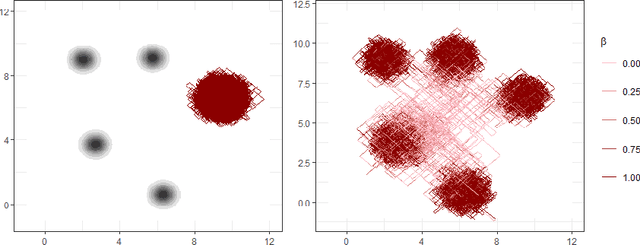
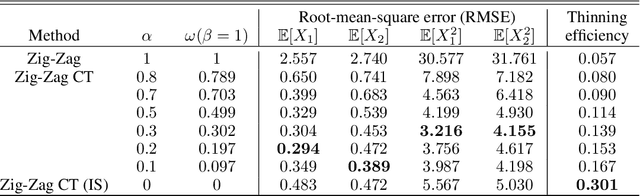
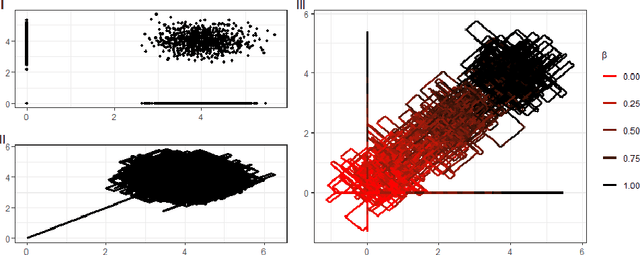
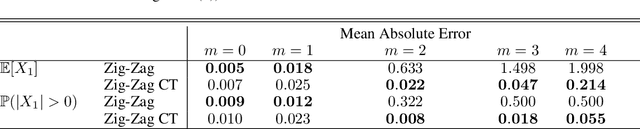
New sampling algorithms based on simulating continuous-time stochastic processes called piece-wise deterministic Markov processes (PDMPs) have shown considerable promise. However, these methods can struggle to sample from multi-modal or heavy-tailed distributions. We show how tempering ideas can improve the mixing of PDMPs in such cases. We introduce an extended distribution defined over the state of the posterior distribution and an inverse temperature, which interpolates between a tractable distribution when the inverse temperature is 0 and the posterior when the inverse temperature is 1. The marginal distribution of the inverse temperature is a mixture of a continuous distribution on [0,1) and a point mass at 1: which means that we obtain samples when the inverse temperature is 1, and these are draws from the posterior, but sampling algorithms will also explore distributions at lower temperatures which will improve mixing. We show how PDMPs, and particularly the Zig-Zag sampler, can be implemented to sample from such an extended distribution. The resulting algorithm is easy to implement and we show empirically that it can outperform existing PDMP-based samplers on challenging multimodal posteriors.
Efficient computation of the volume of a polytope in high-dimensions using Piecewise Deterministic Markov Processes
Feb 18, 2022
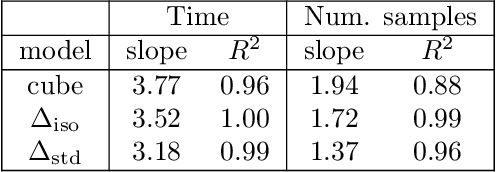

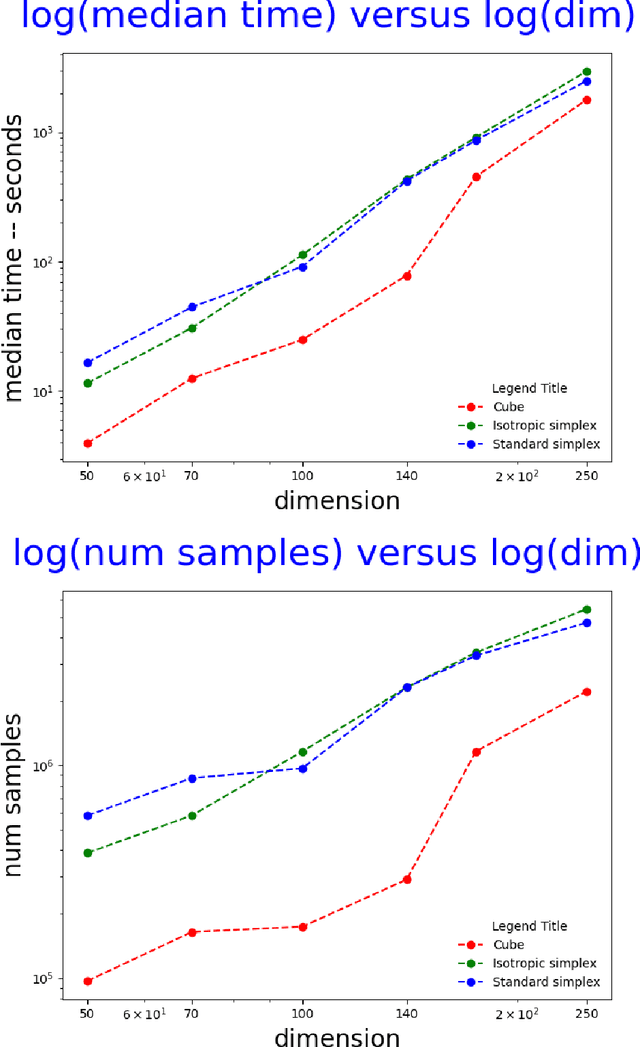
Computing the volume of a polytope in high dimensions is computationally challenging but has wide applications. Current state-of-the-art algorithms to compute such volumes rely on efficient sampling of a Gaussian distribution restricted to the polytope, using e.g. Hamiltonian Monte Carlo. We present a new sampling strategy that uses a Piecewise Deterministic Markov Process. Like Hamiltonian Monte Carlo, this new method involves simulating trajectories of a non-reversible process and inherits similar good mixing properties. However, importantly, the process can be simulated more easily due to its piecewise linear trajectories - and this leads to a reduction of the computational cost by a factor of the dimension of the space. Our experiments indicate that our method is numerically robust and is one order of magnitude faster (or better) than existing methods using Hamiltonian Monte Carlo. On a single core processor, we report computational time of a few minutes up to dimension 500.