 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Gradient Piecewise Deterministic Monte Carlo Samplers
Jun 27, 2024Recent work has suggested using Monte Carlo methods based on piecewise deterministic Markov processes (PDMPs) to sample from target distributions of interest. PDMPs are non-reversible continuous-time processes endowed with momentum, and hence can mix better than standard reversible MCMC samplers. Furthermore, they can incorporate exact sub-sampling schemes which only require access to a single (randomly selected) data point at each iteration, yet without introducing bias to the algorithm's stationary distribution. However, the range of models for which PDMPs can be used, particularly with sub-sampling, is limited. We propose approximate simulation of PDMPs with sub-sampling for scalable sampling from posterior distributions. The approximation takes the form of an Euler approximation to the true PDMP dynamics, and involves using an estimate of the gradient of the log-posterior based on a data sub-sample. We thus call this class of algorithms stochastic-gradient PDMPs. Importantly, the trajectories of stochastic-gradient PDMPs are continuous and can leverage recent ideas for sampling from measures with continuous and atomic components. We show these methods are easy to implement, present results on their approximation error and demonstrate numerically that this class of algorithms has similar efficiency to, but is more robust than, stochastic gradient Langevin dynamics.
Particle Metropolis adjusted Langevin algorithms for state space models
Dec 24, 2014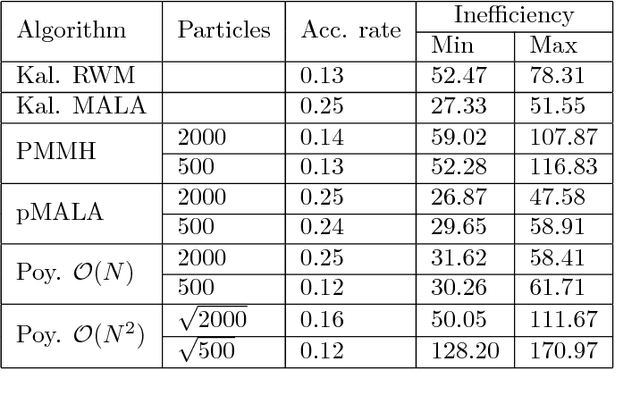
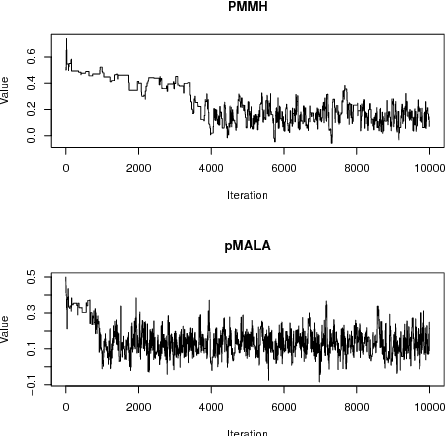
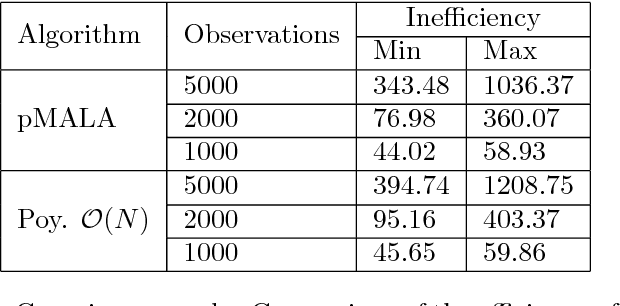
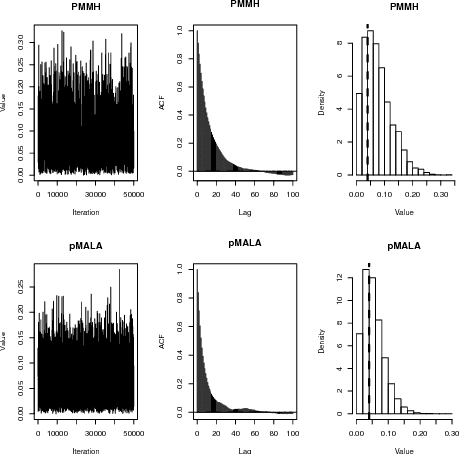
Particle MCMC is a class of algorithms that can be used to analyse state-space models. They use MCMC moves to update the parameters of the models, and particle filters to propose values for the path of the state-space model. Currently the default is to use random walk Metropolis to update the parameter values. We show that it is possible to use information from the output of the particle filter to obtain better proposal distributions for the parameters. In particular it is possible to obtain estimates of the gradient of the log posterior from each run of the particle filter, and use these estimates within a Langevin-type proposal. We propose using the recent computationally efficient approach of Nemeth et al. (2013) for obtaining such estimates. We show empirically that for a variety of state-space models this proposal is more efficient than the standard random walk Metropolis proposal in terms of: reducing autocorrelation of the posterior samples, reducing the burn-in time of the MCMC sampler and increasing the squared jump distance between posterior samples.