 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling high dimensional point clouds with the spherical cluster model
Dec 26, 2025A parametric cluster model is a statistical model providing geometric insights onto the points defining a cluster. The {\em spherical cluster model} (SC) approximates a finite point set $P\subset \mathbb{R}^d$ by a sphere $S(c,r)$ as follows. Taking $r$ as a fraction $η\in(0,1)$ (hyper-parameter) of the std deviation of distances between the center $c$ and the data points, the cost of the SC model is the sum over all data points lying outside the sphere $S$ of their power distance with respect to $S$. The center $c$ of the SC model is the point minimizing this cost. Note that $η=0$ yields the celebrated center of mass used in KMeans clustering. We make three contributions. First, we show fitting a spherical cluster yields a strictly convex but not smooth combinatorial optimization problem. Second, we present an exact solver using the Clarke gradient on a suitable stratified cell complex defined from an arrangement of hyper-spheres. Finally, we present experiments on a variety of datasets ranging in dimension from $d=9$ to $d=10,000$, with two main observations. First, the exact algorithm is orders of magnitude faster than BFGS based heuristics for datasets of small/intermediate dimension and small values of $η$, and for high dimensional datasets (say $d>100$) whatever the value of $η$. Second, the center of the SC model behave as a parameterized high-dimensional median. The SC model is of direct interest for high dimensional multivariate data analysis, and the application to the design of mixtures of SC will be reported in a companion paper.
Efficient computation of the volume of a polytope in high-dimensions using Piecewise Deterministic Markov Processes
Feb 18, 2022
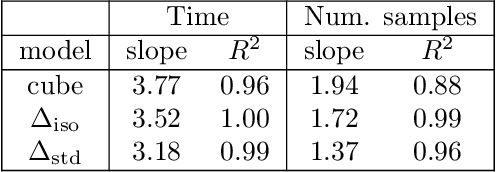

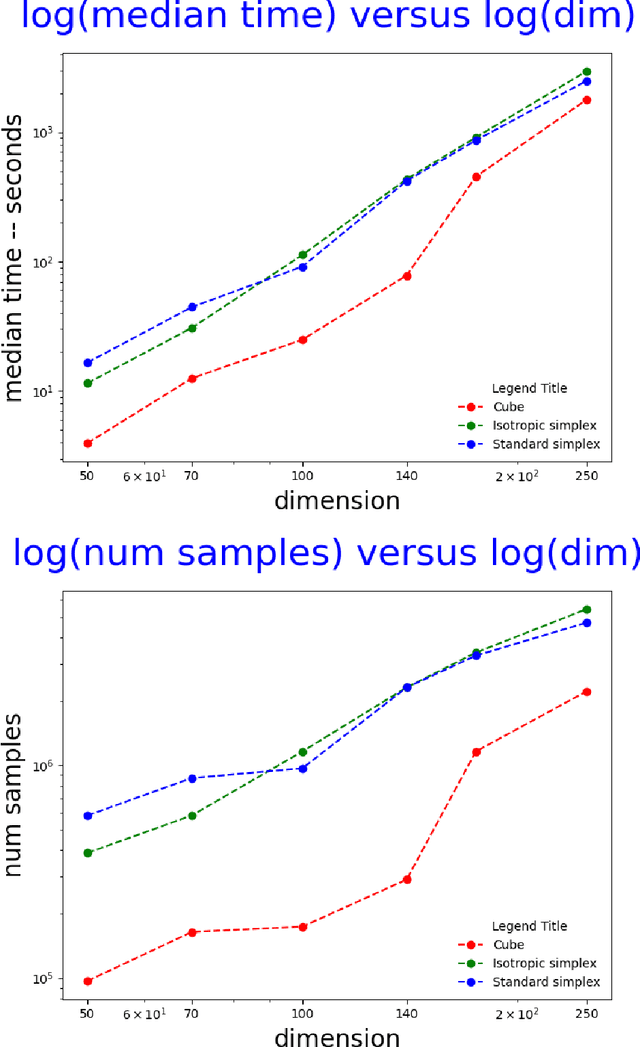
Computing the volume of a polytope in high dimensions is computationally challenging but has wide applications. Current state-of-the-art algorithms to compute such volumes rely on efficient sampling of a Gaussian distribution restricted to the polytope, using e.g. Hamiltonian Monte Carlo. We present a new sampling strategy that uses a Piecewise Deterministic Markov Process. Like Hamiltonian Monte Carlo, this new method involves simulating trajectories of a non-reversible process and inherits similar good mixing properties. However, importantly, the process can be simulated more easily due to its piecewise linear trajectories - and this leads to a reduction of the computational cost by a factor of the dimension of the space. Our experiments indicate that our method is numerically robust and is one order of magnitude faster (or better) than existing methods using Hamiltonian Monte Carlo. On a single core processor, we report computational time of a few minutes up to dimension 500.
kd-switch: A Universal Online Predictor with an application to Sequential Two-Sample Testing
Jan 23, 2019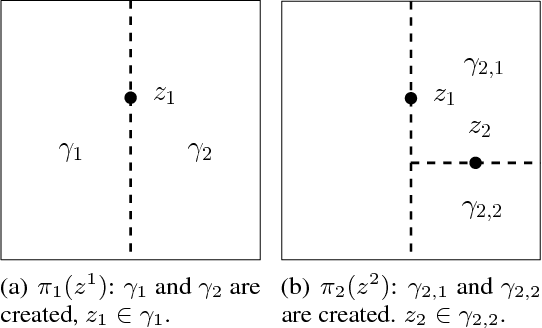
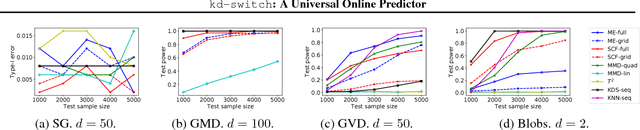
We propose a novel online predictor for discrete labels conditioned on multivariate features in $\mathbb{R}^d$. The predictor is pointwise universal: it achieves a normalized log loss performance asymptotically as good as the true conditional entropy of the labels given the features. The predictor is based on a feature space discretization induced by a full-fledged k-d tree with randomly picked directions and a switch distribution, requiring no hyperparameter setting and automatically selecting the most relevant scales in the feature space. Using recent results, a consistent sequential two-sample test is built from this predictor. In terms of discrimination power, on selected challenging datasets, it is comparable to or better than state-of-the-art non-sequential two-sample tests based on the train-test paradigm and, a recent sequential test requiring hyperparameters. The time complexity to process the $n$-th sample point is $O(\log n)$ in probability (with respect to the distribution generating the data points), in contrast to the linear complexity of the previous sequential approach.