 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditioning Gaussian Processes on Almost Anything
May 20, 2026Gaussian processes (GPs) offer a principled probabilistic model over functions, but exact inference is restricted to the linear-Gaussian regime. We establish an explicit equivalence between GPs and a class of linear diffusion models, recasting predictive sampling as an ODE with closed-form Gaussian dynamics and a likelihood-dependent guidance term that admits a simple Monte Carlo approximation. In the linear-Gaussian setting, we recover standard GP conditioning exactly; beyond conjugacy, the same machinery handles any conditioning statement admitting point-wise likelihood evaluation -- including non-linear physics, and, for the first time, natural language via large language models. Whitening isolates the irreducible non-Gaussian dynamics, minimising Wasserstein-2 transport cost and eliminating numerical stiffness. The result is a general-purpose GP inference scheme requiring no bespoke derivations. Together, these results provide a general mechanism for incorporating the full richness of real-world knowledge as conditioning information, opening a new frontier for the probabilistic modelling of real-world problems.
Hypergraph Generation via Structured Stochastic Diffusion
May 06, 2026Hypergraphs model higher-order interactions, but realistic hypergraph generation remains difficult because incidence, hyperedge-size heterogeneity, and overlap structure are not faithfully captured by pairwise reductions. We propose \HEDGE, a generative model defined directly on relaxed incidence matrices via a structured stochastic diffusion. The forward process combines a hypergraph-specific two-sided heat operator with an Ornstein--Uhlenbeck component, preserving structure-aware noising near the data while yielding an explicit Gaussian terminal law. Conditional on an observed hypergraph, this forward process is linear-Gaussian, so conditional means, covariances, scores, and reverse-drift targets are available in closed form. We therefore learn a permutation-equivariant state-only reverse-drift field in incidence space by regressing onto exact conditional targets, and generate samples by simulating a learned reverse-time SDE from the Gaussian base law. We establish exactness in the ideal state-only setting together with finite-horizon stability guarantees, and empirically show improved hypergraph generation quality relative to strong baselines.
Scalable Model-Based Clustering with Sequential Monte Carlo
Apr 16, 2026In online clustering problems, there is often a large amount of uncertainty over possible cluster assignments that cannot be resolved until more data are observed. This difficulty is compounded when clusters follow complex distributions, as is the case with text data. Sequential Monte Carlo (SMC) methods give a natural way of representing and updating this uncertainty over time, but have prohibitive memory requirements for large-scale problems. We propose a novel SMC algorithm that decomposes clustering problems into approximately independent subproblems, allowing a more compact representation of the algorithm state. Our approach is motivated by the knowledge base construction problem, and we show that our method is able to accurately and efficiently solve clustering problems in this setting and others where traditional SMC struggles.
Generator-based Graph Generation via Heat Diffusion
Feb 03, 2026Graph generative modelling has become an essential task due to the wide range of applications in chemistry, biology, social networks, and knowledge representation. In this work, we propose a novel framework for generating graphs by adapting the Generator Matching (arXiv:2410.20587) paradigm to graph-structured data. We leverage the graph Laplacian and its associated heat kernel to define a continous-time diffusion on each graph. The Laplacian serves as the infinitesimal generator of this diffusion, and its heat kernel provides a family of conditional perturbations of the initial graph. A neural network is trained to match this generator by minimising a Bregman divergence between the true generator and a learnable surrogate. Once trained, the surrogate generator is used to simulate a time-reversed diffusion process to sample new graph structures. Our framework unifies and generalises existing diffusion-based graph generative models, injecting domain-specific inductive bias via the Laplacian, while retaining the flexibility of neural approximators. Experimental studies demonstrate that our approach captures structural properties of real and synthetic graphs effectively.
Deep Learning Surrogates for Real-Time Gas Emission Inversion
Jun 17, 2025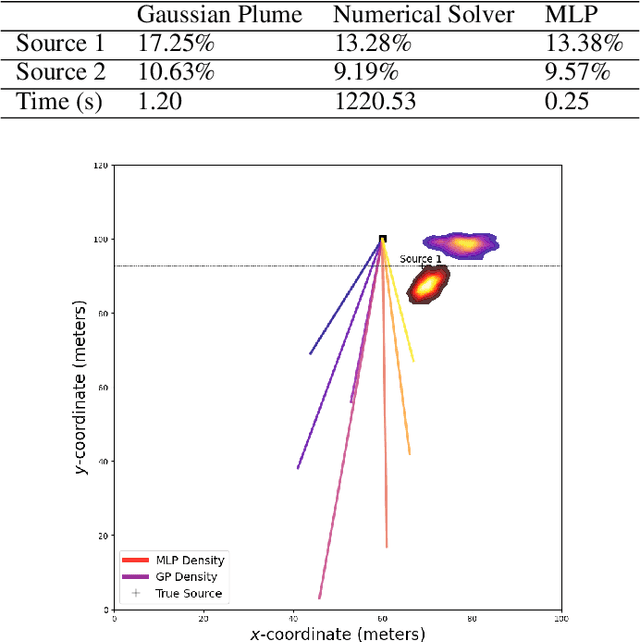
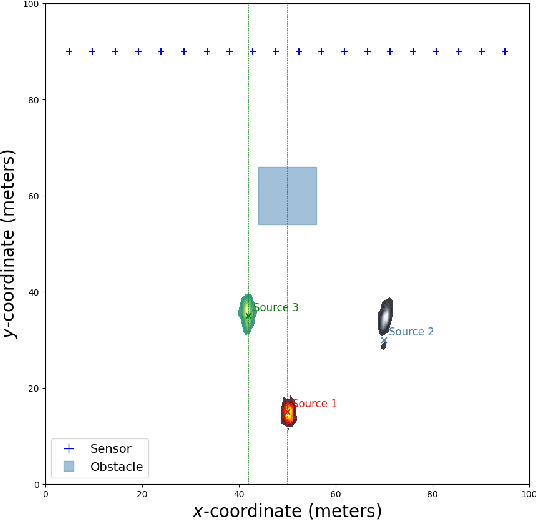
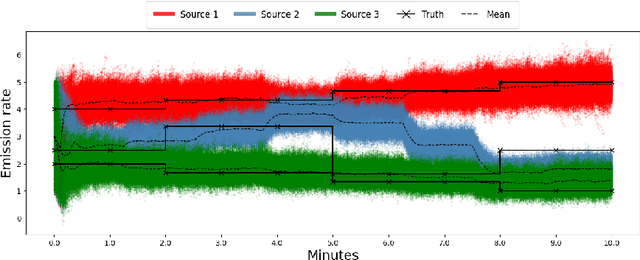
Real-time identification and quantification of greenhouse-gas emissions under transient atmospheric conditions is a critical challenge in environmental monitoring. We introduce a spatio-temporal inversion framework that embeds a deep-learning surrogate of computational fluid dynamics (CFD) within a sequential Monte Carlo algorithm to perform Bayesian inference of both emission rate and source location in dynamic flow fields. By substituting costly numerical solvers with a multilayer perceptron trained on high-fidelity CFD outputs, our surrogate captures spatial heterogeneity and temporal evolution of gas dispersion, while delivering near-real-time predictions. Validation on the Chilbolton methane release dataset demonstrates comparable accuracy to full CFD solvers and Gaussian plume models, yet achieves orders-of-magnitude faster runtimes. Further experiments under simulated obstructed-flow scenarios confirm robustness in complex environments. This work reconciles physical fidelity with computational feasibility, offering a scalable solution for industrial emissions monitoring and other time-sensitive spatio-temporal inversion tasks in environmental and scientific modeling.
Scalable Monte Carlo for Bayesian Learning
Jul 17, 2024



This book aims to provide a graduate-level introduction to advanced topics in Markov chain Monte Carlo (MCMC) algorithms, as applied broadly in the Bayesian computational context. Most, if not all of these topics (stochastic gradient MCMC, non-reversible MCMC, continuous time MCMC, and new techniques for convergence assessment) have emerged as recently as the last decade, and have driven substantial recent practical and theoretical advances in the field. A particular focus is on methods that are scalable with respect to either the amount of data, or the data dimension, motivated by the emerging high-priority application areas in machine learning and AI.
Learning-Rate-Free Stochastic Optimization over Riemannian Manifolds
Jun 04, 2024



In recent years, interest in gradient-based optimization over Riemannian manifolds has surged. However, a significant challenge lies in the reliance on hyperparameters, especially the learning rate, which requires meticulous tuning by practitioners to ensure convergence at a suitable rate. In this work, we introduce innovative learning-rate-free algorithms for stochastic optimization over Riemannian manifolds, eliminating the need for hand-tuning and providing a more robust and user-friendly approach. We establish high probability convergence guarantees that are optimal, up to logarithmic factors, compared to the best-known optimally tuned rate in the deterministic setting. Our approach is validated through numerical experiments, demonstrating competitive performance against learning-rate-dependent algorithms.
Markovian Flow Matching: Accelerating MCMC with Continuous Normalizing Flows
May 23, 2024
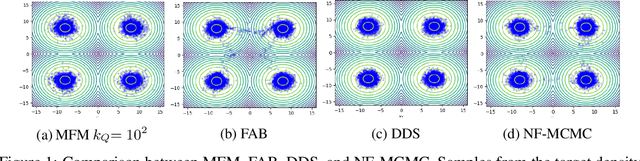
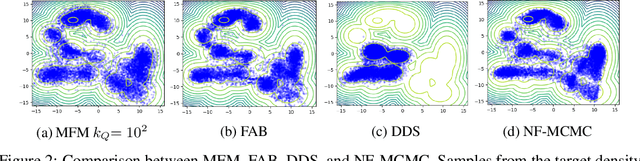
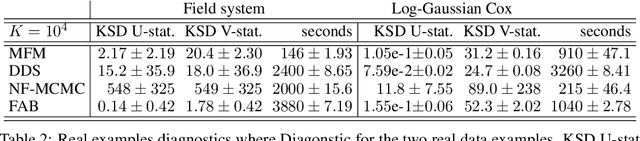
Continuous normalizing flows (CNFs) learn the probability path between a reference and a target density by modeling the vector field generating said path using neural networks. Recently, Lipman et al. (2022) introduced a simple and inexpensive method for training CNFs in generative modeling, termed flow matching (FM). In this paper, we re-purpose this method for probabilistic inference by incorporating Markovian sampling methods in evaluating the FM objective and using the learned probability path to improve Monte Carlo sampling. We propose a sequential method, which uses samples from a Markov chain to fix the probability path defining the FM objective. We augment this scheme with an adaptive tempering mechanism that allows the discovery of multiple modes in the target. Under mild assumptions, we establish convergence to a local optimum of the FM objective, discuss improvements in the convergence rate, and illustrate our methods on synthetic and real-world examples.
Position Paper: Bayesian Deep Learning in the Age of Large-Scale AI
Feb 06, 2024
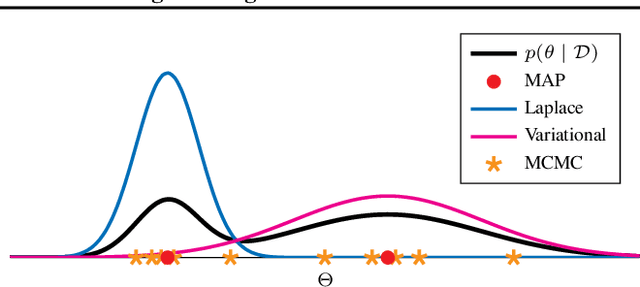
In the current landscape of deep learning research, there is a predominant emphasis on achieving high predictive accuracy in supervised tasks involving large image and language datasets. However, a broader perspective reveals a multitude of overlooked metrics, tasks, and data types, such as uncertainty, active and continual learning, and scientific data, that demand attention. Bayesian deep learning (BDL) constitutes a promising avenue, offering advantages across these diverse settings. This paper posits that BDL can elevate the capabilities of deep learning. It revisits the strengths of BDL, acknowledges existing challenges, and highlights some exciting research avenues aimed at addressing these obstacles. Looking ahead, the discussion focuses on possible ways to combine large-scale foundation models with BDL to unlock their full potential.
CoinEM: Tuning-Free Particle-Based Variational Inference for Latent Variable Models
May 24, 2023



We introduce two new particle-based algorithms for learning latent variable models via marginal maximum likelihood estimation, including one which is entirely tuning-free. Our methods are based on the perspective of marginal maximum likelihood estimation as an optimization problem: namely, as the minimization of a free energy functional. One way to solve this problem is to consider the discretization of a gradient flow associated with the free energy. We study one such approach, which resembles an extension of the popular Stein variational gradient descent algorithm. In particular, we establish a descent lemma for this algorithm, which guarantees that the free energy decreases at each iteration. This method, and any other obtained as the discretization of the gradient flow, will necessarily depend on a learning rate which must be carefully tuned by the practitioner in order to ensure convergence at a suitable rate. With this in mind, we also propose another algorithm for optimizing the free energy which is entirely learning rate free, based on coin betting techniques from convex optimization. We validate the performance of our algorithms across a broad range of numerical experiments, including several high-dimensional settings. Our results are competitive with existing particle-based methods, without the need for any hyperparameter tuning.