 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Multi-Objective Optimization
Dec 11, 2025Balancing competing objectives is omnipresent across disciplines, from drug design to autonomous systems. Multi-objective Bayesian optimization is a promising solution for such expensive, black-box problems: it fits probabilistic surrogates and selects new designs via an acquisition function that balances exploration and exploitation. In practice, it requires tailored choices of surrogate and acquisition that rarely transfer to the next problem, is myopic when multi-step planning is often required, and adds refitting overhead, particularly in parallel or time-sensitive loops. We present TAMO, a fully amortized, universal policy for multi-objective black-box optimization. TAMO uses a transformer architecture that operates across varying input and objective dimensions, enabling pretraining on diverse corpora and transfer to new problems without retraining: at test time, the pretrained model proposes the next design with a single forward pass. We pretrain the policy with reinforcement learning to maximize cumulative hypervolume improvement over full trajectories, conditioning on the entire query history to approximate the Pareto frontier. Across synthetic benchmarks and real tasks, TAMO produces fast proposals, reducing proposal time by 50-1000x versus alternatives while matching or improving Pareto quality under tight evaluation budgets. These results show that transformers can perform multi-objective optimization entirely in-context, eliminating per-task surrogate fitting and acquisition engineering, and open a path to foundation-style, plug-and-play optimizers for scientific discovery workflows.
Efficient Autoregressive Inference for Transformer Probabilistic Models
Oct 10, 2025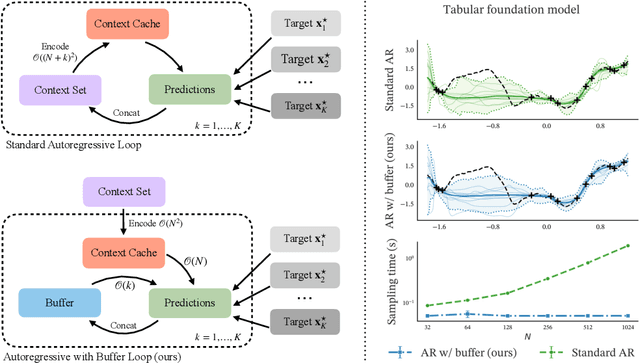

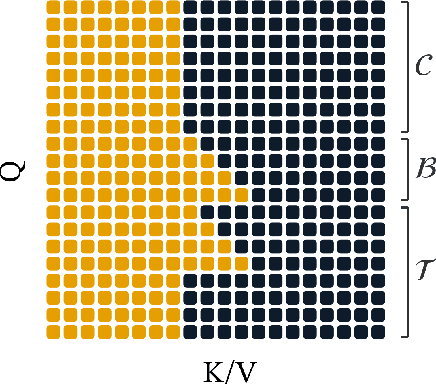

Transformer-based models for amortized probabilistic inference, such as neural processes, prior-fitted networks, and tabular foundation models, excel at single-pass marginal prediction. However, many real-world applications, from signal interpolation to multi-column tabular predictions, require coherent joint distributions that capture dependencies between predictions. While purely autoregressive architectures efficiently generate such distributions, they sacrifice the flexible set-conditioning that makes these models powerful for meta-learning. Conversely, the standard approach to obtain joint distributions from set-based models requires expensive re-encoding of the entire augmented conditioning set at each autoregressive step. We introduce a causal autoregressive buffer that preserves the advantages of both paradigms. Our approach decouples context encoding from updating the conditioning set. The model processes the context once and caches it. A dynamic buffer then captures target dependencies: as targets are incorporated, they enter the buffer and attend to both the cached context and previously buffered targets. This enables efficient batched autoregressive generation and one-pass joint log-likelihood evaluation. A unified training strategy allows seamless integration of set-based and autoregressive modes at minimal additional cost. Across synthetic functions, EEG signals, cognitive models, and tabular data, our method matches predictive accuracy of strong baselines while delivering up to 20 times faster joint sampling. Our approach combines the efficiency of autoregressive generative models with the representational power of set-based conditioning, making joint prediction practical for transformer-based probabilistic models.
Federated Learning for Non-factorizable Models using Deep Generative Prior Approximations
May 25, 2024



Federated learning (FL) allows for collaborative model training across decentralized clients while preserving privacy by avoiding data sharing. However, current FL methods assume conditional independence between client models, limiting the use of priors that capture dependence, such as Gaussian processes (GPs). We introduce the Structured Independence via deep Generative Model Approximation (SIGMA) prior which enables FL for non-factorizable models across clients, expanding the applicability of FL to fields such as spatial statistics, epidemiology, environmental science, and other domains where modeling dependencies is crucial. The SIGMA prior is a pre-trained deep generative model that approximates the desired prior and induces a specified conditional independence structure in the latent variables, creating an approximate model suitable for FL settings. We demonstrate the SIGMA prior's effectiveness on synthetic data and showcase its utility in a real-world example of FL for spatial data, using a conditional autoregressive prior to model spatial dependence across Australia. Our work enables new FL applications in domains where modeling dependent data is essential for accurate predictions and decision-making.
Scalable Vertical Federated Learning via Data Augmentation and Amortized Inference
May 07, 2024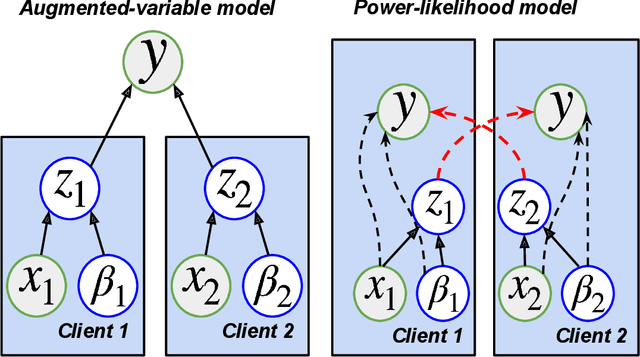


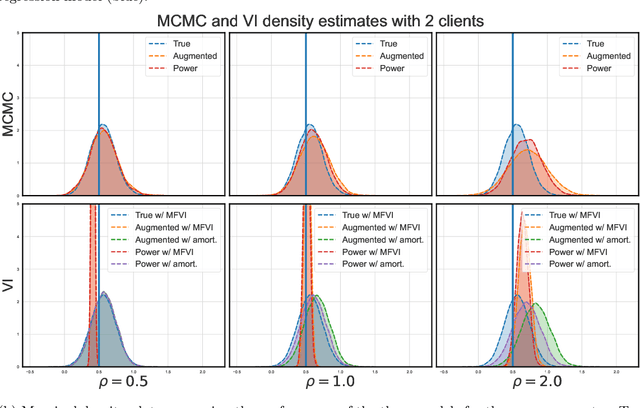
Vertical federated learning (VFL) has emerged as a paradigm for collaborative model estimation across multiple clients, each holding a distinct set of covariates. This paper introduces the first comprehensive framework for fitting Bayesian models in the VFL setting. We propose a novel approach that leverages data augmentation techniques to transform VFL problems into a form compatible with existing Bayesian federated learning algorithms. We present an innovative model formulation for specific VFL scenarios where the joint likelihood factorizes into a product of client-specific likelihoods. To mitigate the dimensionality challenge posed by data augmentation, which scales with the number of observations and clients, we develop a factorized amortized variational approximation that achieves scalability independent of the number of observations. We showcase the efficacy of our framework through extensive numerical experiments on logistic regression, multilevel regression, and a novel hierarchical Bayesian split neural net model. Our work paves the way for privacy-preserving, decentralized Bayesian inference in vertically partitioned data scenarios, opening up new avenues for research and applications in various domains.
Deep Generative Models, Synthetic Tabular Data, and Differential Privacy: An Overview and Synthesis
Jul 28, 2023This article provides a comprehensive synthesis of the recent developments in synthetic data generation via deep generative models, focusing on tabular datasets. We specifically outline the importance of synthetic data generation in the context of privacy-sensitive data. Additionally, we highlight the advantages of using deep generative models over other methods and provide a detailed explanation of the underlying concepts, including unsupervised learning, neural networks, and generative models. The paper covers the challenges and considerations involved in using deep generative models for tabular datasets, such as data normalization, privacy concerns, and model evaluation. This review provides a valuable resource for researchers and practitioners interested in synthetic data generation and its applications.
Federated Variational Inference Methods for Structured Latent Variable Models
Feb 07, 2023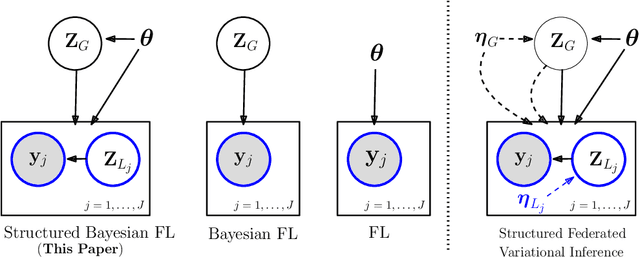
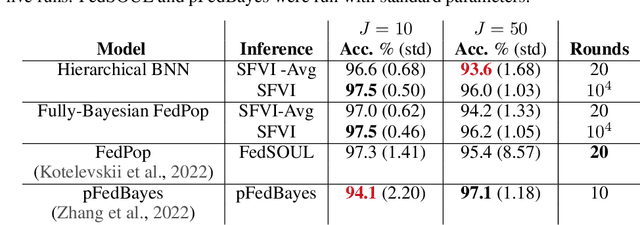
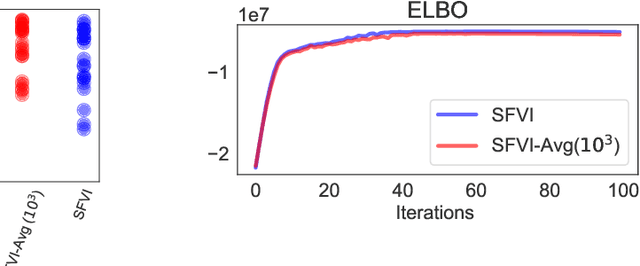
Federated learning methods, that is, methods that perform model training using data situated across different sources, whilst simultaneously not having the data leave their original source, are of increasing interest in a number of fields. However, despite this interest, the classes of models for which easily-applicable and sufficiently general approaches are available is limited, excluding many structured probabilistic models. We present a general yet elegant resolution to the aforementioned issue. The approach is based on adopting structured variational inference, an approach widely used in Bayesian machine learning, to the federated setting. Additionally, a communication-efficient variant analogous to the canonical FedAvg algorithm is explored. The effectiveness of the proposed algorithms are demonstrated, and their performance is compared on Bayesian multinomial regression, topic modelling, and mixed model examples.