 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage models recognize dropout and Gaussian noise applied to their activations
Apr 19, 2026We provide evidence that language models can detect, localize and, to a certain degree, verbalize the difference between perturbations applied to their activations. More precisely, we either (a) \emph{mask} activations, simulating \emph{dropout}, or (b) add \emph{Gaussian noise} to them, at a target sentence. We then ask a multiple-choice question such as ``\emph{Which of the previous sentences was perturbed?}'' or ``\emph{Which of the two perturbations was applied?}''. We test models from the Llama, Olmo, and Qwen families, with sizes between 8B and 32B, all of which can easily detect and localize the perturbations, often with perfect accuracy. These models can also learn, when taught in context, to distinguish between dropout and Gaussian noise. Notably, \qwenb's \emph{zero-shot} accuracy in identifying which perturbation was applied improves as a function of the perturbation strength and, moreover, decreases if the in-context labels are flipped, suggesting a prior for the correct ones -- even modulo controls. Because dropout has been used as a training-regularization technique, while Gaussian noise is sometimes added during inference, we discuss the possibility of a data-agnostic ``training awareness'' signal and the implications for AI safety. The code and data are available at \href{https://github.com/saifh-github/llm-dropout-noise-recognition}{link 1} and \href{https://drive.google.com/file/d/1es-Sfw_AH9GficeXgeqpy87rocrZZ_PQ/view}{link 2}, respectively.
AIMS.au: A Dataset for the Analysis of Modern Slavery Countermeasures in Corporate Statements
Feb 10, 2025



Despite over a decade of legislative efforts to address modern slavery in the supply chains of large corporations, the effectiveness of government oversight remains hampered by the challenge of scrutinizing thousands of statements annually. While Large Language Models (LLMs) can be considered a well established solution for the automatic analysis and summarization of documents, recognizing concrete modern slavery countermeasures taken by companies and differentiating those from vague claims remains a challenging task. To help evaluate and fine-tune LLMs for the assessment of corporate statements, we introduce a dataset composed of 5,731 modern slavery statements taken from the Australian Modern Slavery Register and annotated at the sentence level. This paper details the construction steps for the dataset that include the careful design of annotation specifications, the selection and preprocessing of statements, and the creation of high-quality annotation subsets for effective model evaluations. To demonstrate our dataset's utility, we propose a machine learning methodology for the detection of sentences relevant to mandatory reporting requirements set by the Australian Modern Slavery Act. We then follow this methodology to benchmark modern language models under zero-shot and supervised learning settings.
On Using Transformers for Speech-Separation
Feb 06, 2022



Transformers have enabled major improvements in deep learning. They often outperform recurrent and convolutional models in many tasks while taking advantage of parallel processing. Recently, we have proposed SepFormer, which uses self-attention and obtains state-of-the art results on WSJ0-2/3 Mix datasets for speech separation. In this paper, we extend our previous work by providing results on more datasets including LibriMix, and WHAM!, WHAMR! which include noisy and noisy-reverberant conditions. Moreover we provide denoising, and denoising+dereverberation results in the context of speech enhancement, respectively on WHAM! and WHAMR! datasets. We also investigate incorporating recently proposed efficient self-attention mechanisms inside the SepFormer model, and show that by using efficient self-attention mechanisms it is possible to reduce the memory requirements significantly while performing better than the popular convtasnet model on WSJ0-2Mix dataset.
Accounting for Variance in Machine Learning Benchmarks
Mar 01, 2021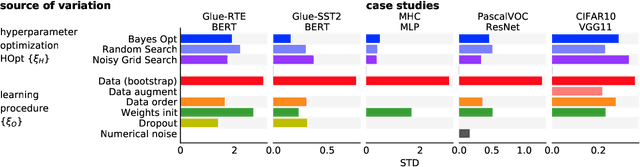
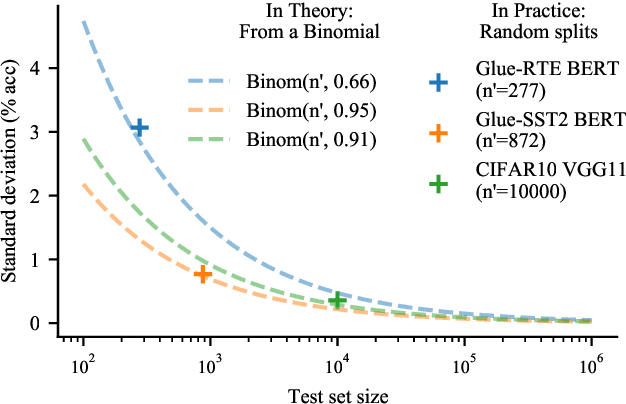
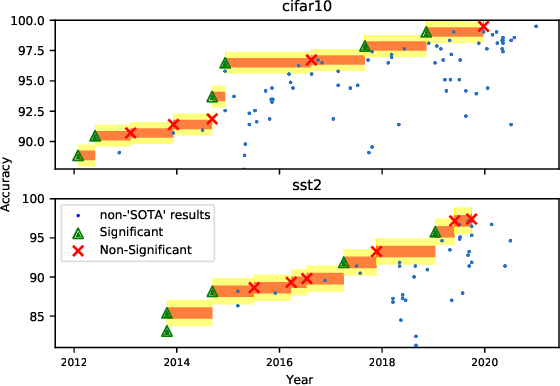
Strong empirical evidence that one machine-learning algorithm A outperforms another one B ideally calls for multiple trials optimizing the learning pipeline over sources of variation such as data sampling, data augmentation, parameter initialization, and hyperparameters choices. This is prohibitively expensive, and corners are cut to reach conclusions. We model the whole benchmarking process, revealing that variance due to data sampling, parameter initialization and hyperparameter choice impact markedly the results. We analyze the predominant comparison methods used today in the light of this variance. We show a counter-intuitive result that adding more sources of variation to an imperfect estimator approaches better the ideal estimator at a 51 times reduction in compute cost. Building on these results, we study the error rate of detecting improvements, on five different deep-learning tasks/architectures. This study leads us to propose recommendations for performance comparisons.
Attention is All You Need in Speech Separation
Oct 25, 2020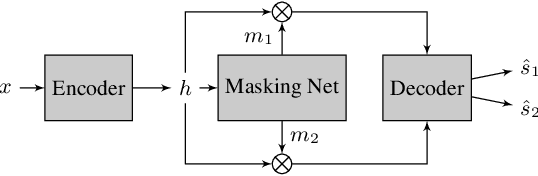
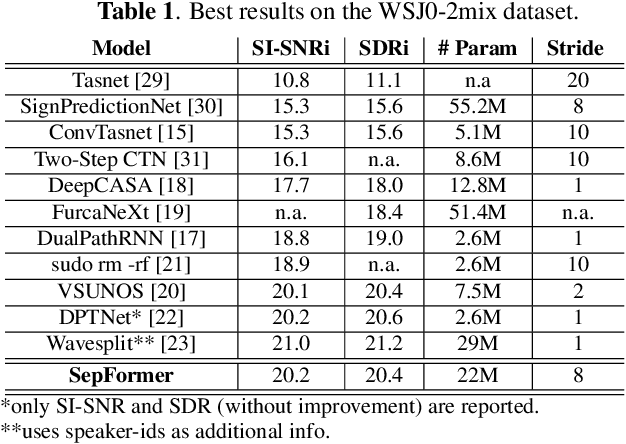
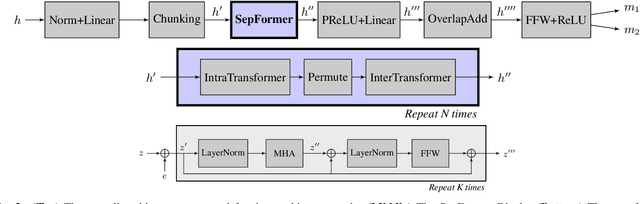
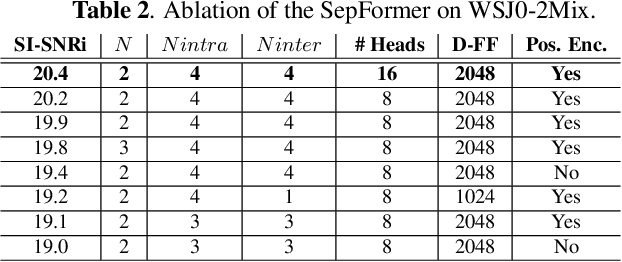
Recurrent Neural Networks (RNNs) have long been the dominant architecture in sequence-to-sequence learning. RNNs, however, are inherently sequential models that do not allow parallelization of their computations. Transformers are emerging as a natural alternative to standard RNNs, replacing recurrent computations with a multi-head attention mechanism. In this paper, we propose the `SepFormer', a novel RNN-free Transformer-based neural network for speech separation. The SepFormer learns short and long-term dependencies with a multi-scale approach that employs transformers. The proposed model matches or overtakes the state-of-the-art (SOTA) performance on the standard WSJ0-2/3mix datasets. It indeed achieves an SI-SNRi of 20.2 dB on WSJ0-2mix matching the SOTA, and an SI-SNRi of 17.6 dB on WSJ0-3mix, a SOTA result. The SepFormer inherits the parallelization advantages of Transformers and achieves a competitive performance even when downsampling the encoded representation by a factor of 8. It is thus significantly faster and it is less memory-demanding than the latest RNN-based systems.