 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Attention-Based Approach for Image-to-3D Texture Mapping
Sep 05, 2025



High-quality textures are critical for realistic 3D content creation, yet existing generative methods are slow, rely on UV maps, and often fail to remain faithful to a reference image. To address these challenges, we propose a transformer-based framework that predicts a 3D texture field directly from a single image and a mesh, eliminating the need for UV mapping and differentiable rendering, and enabling faster texture generation. Our method integrates a triplane representation with depth-based backprojection losses, enabling efficient training and faster inference. Once trained, it generates high-fidelity textures in a single forward pass, requiring only 0.2s per shape. Extensive qualitative, quantitative, and user preference evaluations demonstrate that our method outperforms state-of-the-art baselines on single-image texture reconstruction in terms of both fidelity to the input image and perceptual quality, highlighting its practicality for scalable, high-quality, and controllable 3D content creation.
Wavelet Latent Diffusion (Wala): Billion-Parameter 3D Generative Model with Compact Wavelet Encodings
Nov 12, 2024



Large-scale 3D generative models require substantial computational resources yet often fall short in capturing fine details and complex geometries at high resolutions. We attribute this limitation to the inefficiency of current representations, which lack the compactness required to model the generative models effectively. To address this, we introduce a novel approach called Wavelet Latent Diffusion, or WaLa, that encodes 3D shapes into wavelet-based, compact latent encodings. Specifically, we compress a $256^3$ signed distance field into a $12^3 \times 4$ latent grid, achieving an impressive 2427x compression ratio with minimal loss of detail. This high level of compression allows our method to efficiently train large-scale generative networks without increasing the inference time. Our models, both conditional and unconditional, contain approximately one billion parameters and successfully generate high-quality 3D shapes at $256^3$ resolution. Moreover, WaLa offers rapid inference, producing shapes within two to four seconds depending on the condition, despite the model's scale. We demonstrate state-of-the-art performance across multiple datasets, with significant improvements in generation quality, diversity, and computational efficiency. We open-source our code and, to the best of our knowledge, release the largest pretrained 3D generative models across different modalities.
Causal Inference in Gene Regulatory Networks with GFlowNet: Towards Scalability in Large Systems
Oct 05, 2023


Understanding causal relationships within Gene Regulatory Networks (GRNs) is essential for unraveling the gene interactions in cellular processes. However, causal discovery in GRNs is a challenging problem for multiple reasons including the existence of cyclic feedback loops and uncertainty that yields diverse possible causal structures. Previous works in this area either ignore cyclic dynamics (assume acyclic structure) or struggle with scalability. We introduce Swift-DynGFN as a novel framework that enhances causal structure learning in GRNs while addressing scalability concerns. Specifically, Swift-DynGFN exploits gene-wise independence to boost parallelization and to lower computational cost. Experiments on real single-cell RNA velocity and synthetic GRN datasets showcase the advancement in learning causal structure in GRNs and scalability in larger systems.
Pre-Training and Fine-Tuning Generative Flow Networks
Oct 05, 2023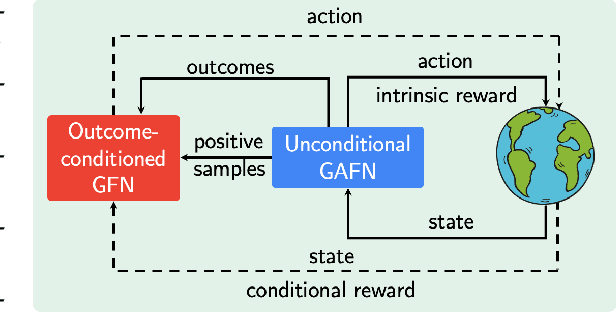

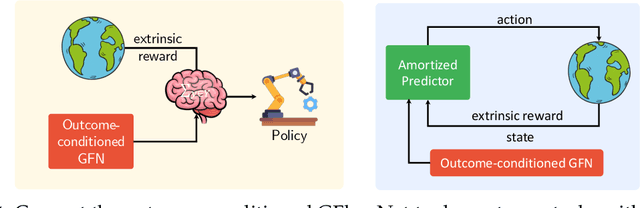
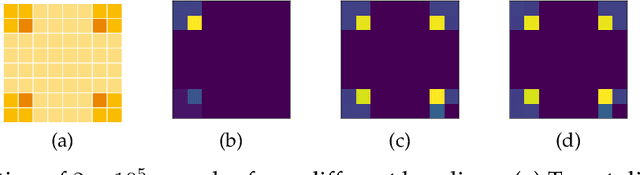
Generative Flow Networks (GFlowNets) are amortized samplers that learn stochastic policies to sequentially generate compositional objects from a given unnormalized reward distribution. They can generate diverse sets of high-reward objects, which is an important consideration in scientific discovery tasks. However, as they are typically trained from a given extrinsic reward function, it remains an important open challenge about how to leverage the power of pre-training and train GFlowNets in an unsupervised fashion for efficient adaptation to downstream tasks. Inspired by recent successes of unsupervised pre-training in various domains, we introduce a novel approach for reward-free pre-training of GFlowNets. By framing the training as a self-supervised problem, we propose an outcome-conditioned GFlowNet (OC-GFN) that learns to explore the candidate space. Specifically, OC-GFN learns to reach any targeted outcomes, akin to goal-conditioned policies in reinforcement learning. We show that the pre-trained OC-GFN model can allow for a direct extraction of a policy capable of sampling from any new reward functions in downstream tasks. Nonetheless, adapting OC-GFN on a downstream task-specific reward involves an intractable marginalization over possible outcomes. We propose a novel way to approximate this marginalization by learning an amortized predictor enabling efficient fine-tuning. Extensive experimental results validate the efficacy of our approach, demonstrating the effectiveness of pre-training the OC-GFN, and its ability to swiftly adapt to downstream tasks and discover modes more efficiently. This work may serve as a foundation for further exploration of pre-training strategies in the context of GFlowNets.
Thompson sampling for improved exploration in GFlowNets
Jun 30, 2023Generative flow networks (GFlowNets) are amortized variational inference algorithms that treat sampling from a distribution over compositional objects as a sequential decision-making problem with a learnable action policy. Unlike other algorithms for hierarchical sampling that optimize a variational bound, GFlowNet algorithms can stably run off-policy, which can be advantageous for discovering modes of the target distribution. Despite this flexibility in the choice of behaviour policy, the optimal way of efficiently selecting trajectories for training has not yet been systematically explored. In this paper, we view the choice of trajectories for training as an active learning problem and approach it using Bayesian techniques inspired by methods for multi-armed bandits. The proposed algorithm, Thompson sampling GFlowNets (TS-GFN), maintains an approximate posterior distribution over policies and samples trajectories from this posterior for training. We show in two domains that TS-GFN yields improved exploration and thus faster convergence to the target distribution than the off-policy exploration strategies used in past work.
Reusable Slotwise Mechanisms
Feb 21, 2023Agents that can understand and reason over the dynamics of objects can have a better capability to act robustly and generalize to novel scenarios. Such an ability, however, requires a suitable representation of the scene as well as an understanding of the mechanisms that govern the interactions of different subsets of objects. To address this problem, we propose RSM, or Reusable Slotwise Mechanisms, that jointly learns a slotwise representation of the scene and a modular architecture that dynamically chooses one mechanism among a set of reusable mechanisms to predict the next state of each slot. RSM crucially takes advantage of a \textit{Central Contextual Information (CCI)}, which lets each selected reusable mechanism access the rest of the slots through a bottleneck, effectively allowing for modeling higher order and complex interactions that might require a sparse subset of objects. We show how this model outperforms state-of-the-art methods in a variety of next-step prediction tasks ranging from grid-world environments to Atari 2600 games. Particularly, we challenge methods that model the dynamics with Graph Neural Networks (GNNs) on top of slotwise representations, and modular architectures that restrict the interactions to be only pairwise. Finally, we show that RSM is able to generalize to scenes with objects varying in number and shape, highlighting its out-of-distribution generalization capabilities. Our implementation is available online\footnote{\hyperlink{https://github.com/trangnnp/RSM}{github.com/trangnnp/RSM}}.
Learning GFlowNets from partial episodes for improved convergence and stability
Sep 30, 2022
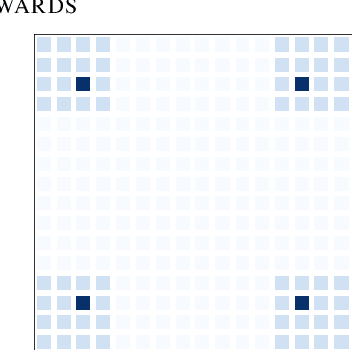


Generative flow networks (GFlowNets) are a family of algorithms for training a sequential sampler of discrete objects under an unnormalized target density and have been successfully used for various probabilistic modeling tasks. Existing training objectives for GFlowNets are either local to states or transitions, or propagate a reward signal over an entire sampling trajectory. We argue that these alternatives represent opposite ends of a gradient bias-variance tradeoff and propose a way to exploit this tradeoff to mitigate its harmful effects. Inspired by the TD($\lambda$) algorithm in reinforcement learning, we introduce subtrajectory balance or SubTB($\lambda$), a GFlowNet training objective that can learn from partial action subsequences of varying lengths. We show that SubTB($\lambda$) accelerates sampler convergence in previously studied and new environments and enables training GFlowNets in environments with longer action sequences and sparser reward landscapes than what was possible before. We also perform a comparative analysis of stochastic gradient dynamics, shedding light on the bias-variance tradeoff in GFlowNet training and the advantages of subtrajectory balance.
Fast and Slow Learning of Recurrent Independent Mechanisms
May 19, 2021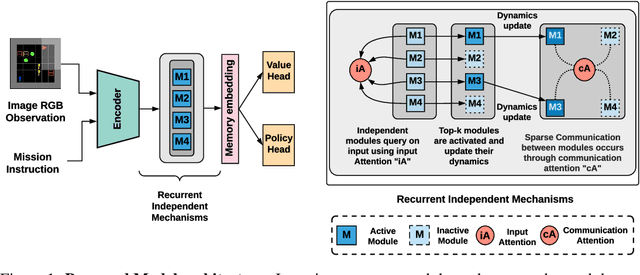

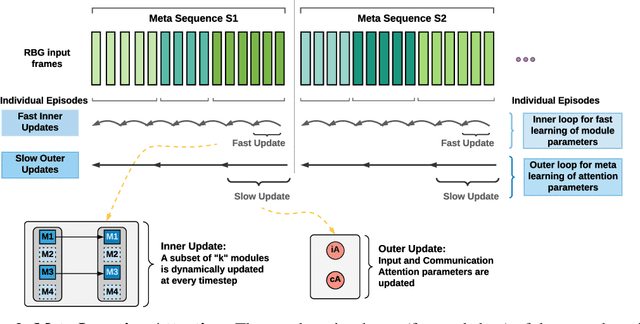
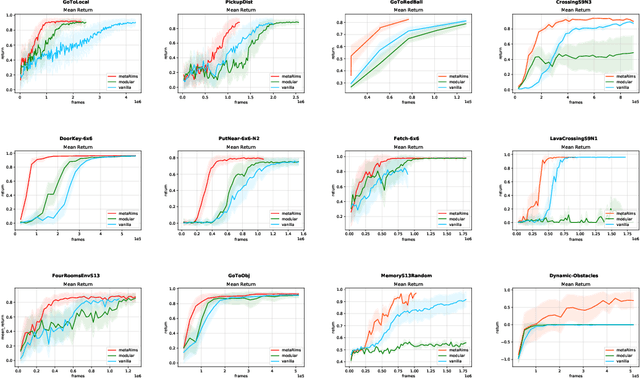
Decomposing knowledge into interchangeable pieces promises a generalization advantage when there are changes in distribution. A learning agent interacting with its environment is likely to be faced with situations requiring novel combinations of existing pieces of knowledge. We hypothesize that such a decomposition of knowledge is particularly relevant for being able to generalize in a systematic manner to out-of-distribution changes. To study these ideas, we propose a particular training framework in which we assume that the pieces of knowledge an agent needs and its reward function are stationary and can be re-used across tasks. An attention mechanism dynamically selects which modules can be adapted to the current task, and the parameters of the selected modules are allowed to change quickly as the learner is confronted with variations in what it experiences, while the parameters of the attention mechanisms act as stable, slowly changing, meta-parameters. We focus on pieces of knowledge captured by an ensemble of modules sparsely communicating with each other via a bottleneck of attention. We find that meta-learning the modular aspects of the proposed system greatly helps in achieving faster adaptation in a reinforcement learning setup involving navigation in a partially observed grid world with image-level input. We also find that reversing the role of parameters and meta-parameters does not work nearly as well, suggesting a particular role for fast adaptation of the dynamically selected modules.
Accounting for Variance in Machine Learning Benchmarks
Mar 01, 2021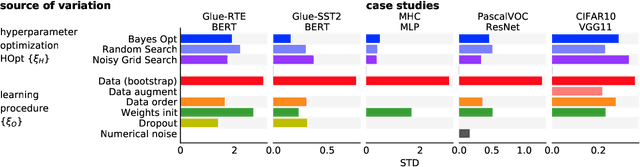
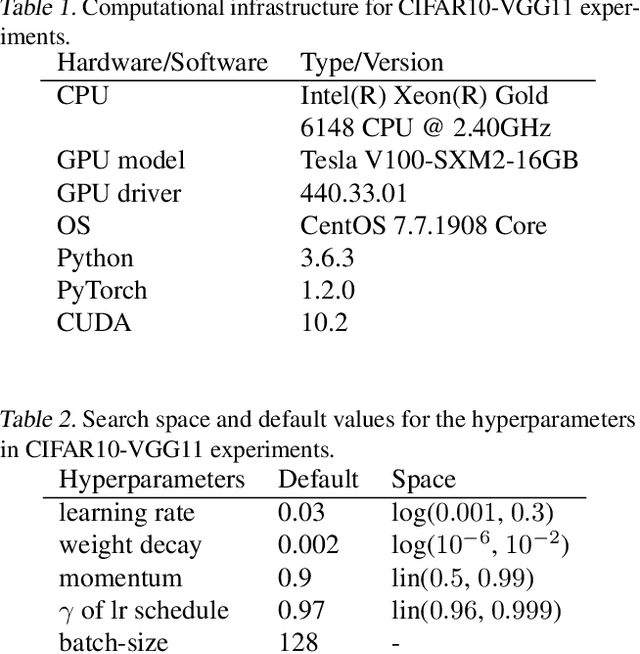
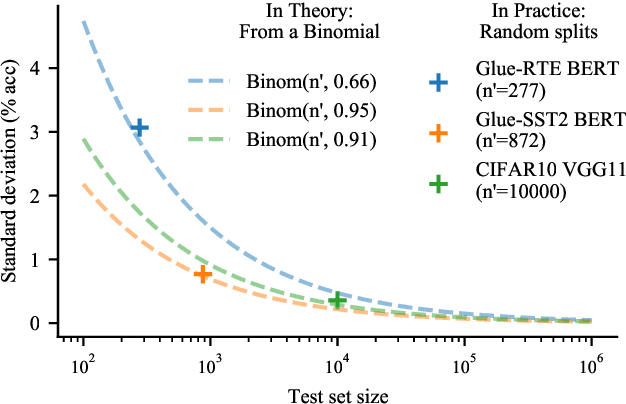
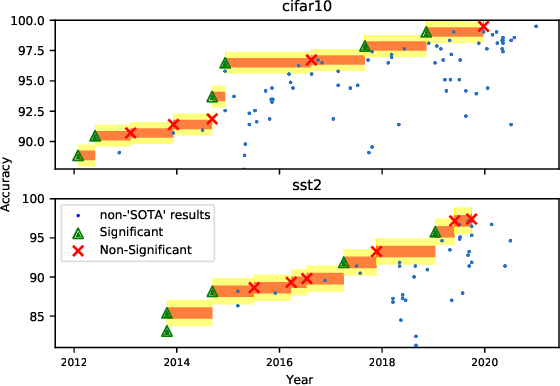
Strong empirical evidence that one machine-learning algorithm A outperforms another one B ideally calls for multiple trials optimizing the learning pipeline over sources of variation such as data sampling, data augmentation, parameter initialization, and hyperparameters choices. This is prohibitively expensive, and corners are cut to reach conclusions. We model the whole benchmarking process, revealing that variance due to data sampling, parameter initialization and hyperparameter choice impact markedly the results. We analyze the predominant comparison methods used today in the light of this variance. We show a counter-intuitive result that adding more sources of variation to an imperfect estimator approaches better the ideal estimator at a 51 times reduction in compute cost. Building on these results, we study the error rate of detecting improvements, on five different deep-learning tasks/architectures. This study leads us to propose recommendations for performance comparisons.