 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Using Transformers for Speech-Separation
Feb 06, 2022



Transformers have enabled major improvements in deep learning. They often outperform recurrent and convolutional models in many tasks while taking advantage of parallel processing. Recently, we have proposed SepFormer, which uses self-attention and obtains state-of-the art results on WSJ0-2/3 Mix datasets for speech separation. In this paper, we extend our previous work by providing results on more datasets including LibriMix, and WHAM!, WHAMR! which include noisy and noisy-reverberant conditions. Moreover we provide denoising, and denoising+dereverberation results in the context of speech enhancement, respectively on WHAM! and WHAMR! datasets. We also investigate incorporating recently proposed efficient self-attention mechanisms inside the SepFormer model, and show that by using efficient self-attention mechanisms it is possible to reduce the memory requirements significantly while performing better than the popular convtasnet model on WSJ0-2Mix dataset.
Audio scene monitoring using redundant un-localized microphone arrays
Mar 02, 2021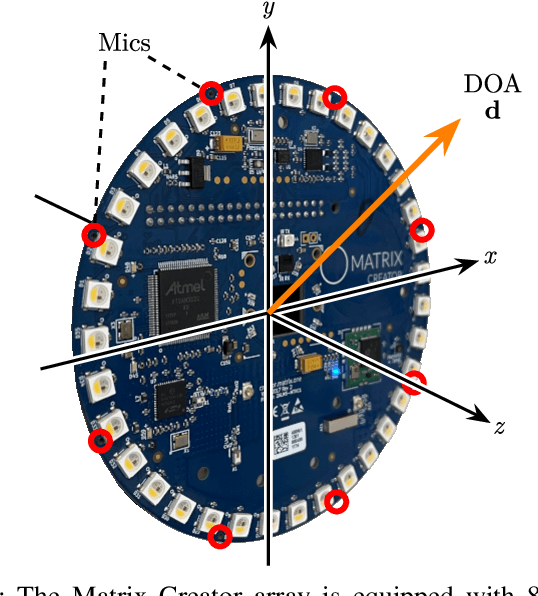
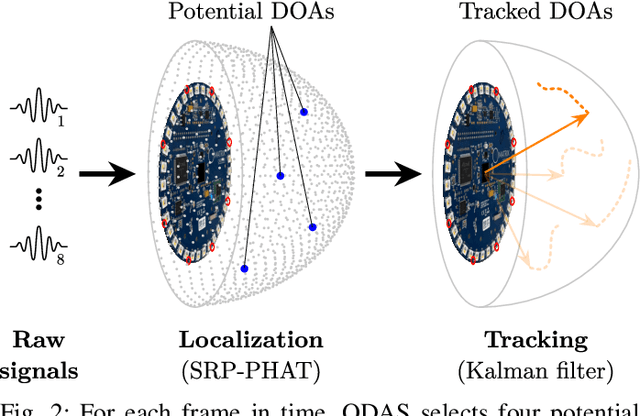
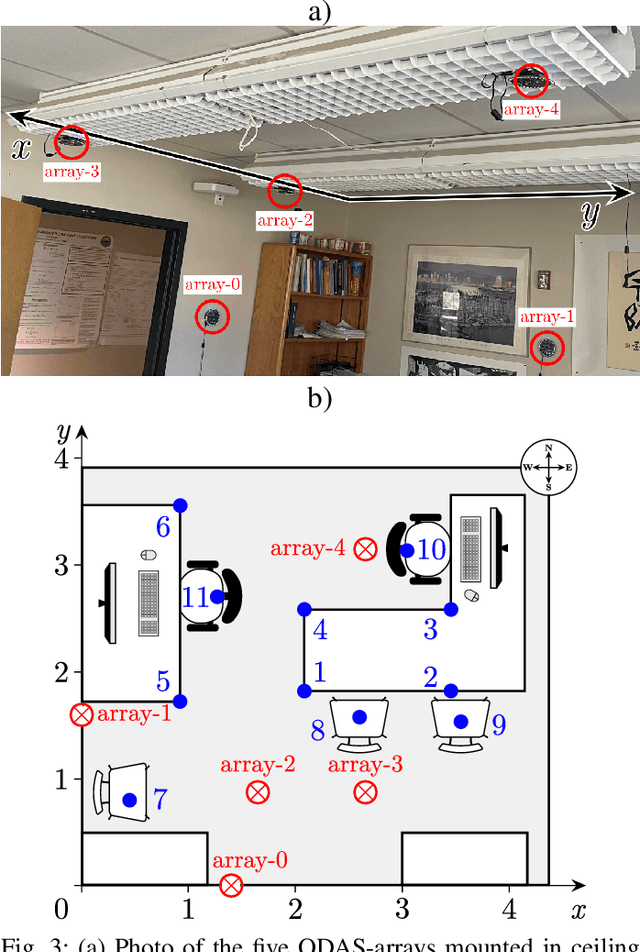

We present a system for localizing sound sources in a room with several microphone arrays. Unlike most existing approaches, the positions of the arrays in space are assumed to be unknown. Each circular array performs direction of arrival (DOA) estimation independently. The DOAs are then fed to a fusion center where they are concatenated and used to perform the localization based on two proposed methods, which require only few labeled source locations for calibration. The first proposed method is based on principal component analysis (PCA) of the observed DOA and does not require any calibration. The array cluster can then perform localization on a manifold defined by the PCA of concatenated DOAs over time. The second proposed method performs localization using an affine transformation between the DOA vectors and the room manifold. The PCA approach has fewer requirements on the training sequence, but is less robust to missing DOAs from one of the arrays. The approach is demonstrated with a set of five 8-microphone circular arrays, placed at unknown fixed locations in an office. Both the PCA approach and the direct approach can easily map out a rectangle based on a few calibration points with similar accuracy as calibration points. The methods demonstrated here provide a step towards monitoring activities in a smart home and require little installation effort as the array locations are not needed.
A Study of Enhancement, Augmentation, and Autoencoder Methods for Domain Adaptation in Distant Speech Recognition
Jun 13, 2018

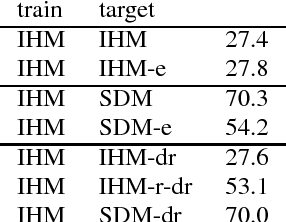
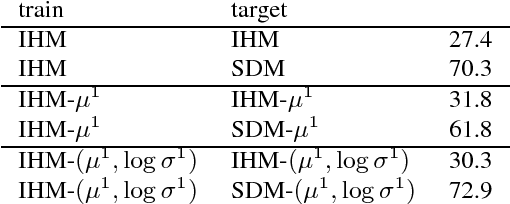
Speech recognizers trained on close-talking speech do not generalize to distant speech and the word error rate degradation can be as large as 40% absolute. Most studies focus on tackling distant speech recognition as a separate problem, leaving little effort to adapting close-talking speech recognizers to distant speech. In this work, we review several approaches from a domain adaptation perspective. These approaches, including speech enhancement, multi-condition training, data augmentation, and autoencoders, all involve a transformation of the data between domains. We conduct experiments on the AMI data set, where these approaches can be realized under the same controlled setting. These approaches lead to different amounts of improvement under their respective assumptions. The purpose of this paper is to quantify and characterize the performance gap between the two domains, setting up the basis for studying adaptation of speech recognizers from close-talking speech to distant speech. Our results also have implications for improving distant speech recognition.