 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Worldwide Image Geolocation by Ensembling Satellite-Based Ground-Level Attribute Predictors
Jul 18, 2024
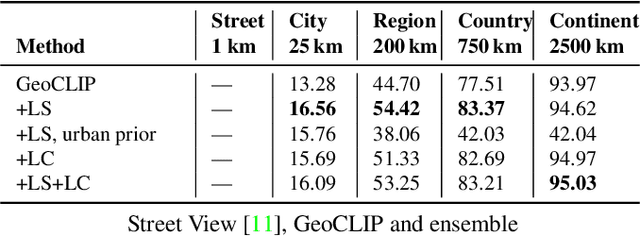

Geolocating images of a ground-level scene entails estimating the location on Earth where the picture was taken, in absence of GPS or other location metadata. Typically, methods are evaluated by measuring the Great Circle Distance (GCD) between a predicted location and ground truth. However, this measurement is limited because it only evaluates a single point, not estimates of regions or score heatmaps. This is especially important in applications to rural, wilderness and under-sampled areas, where finding the exact location may not be possible, and when used in aggregate systems that progressively narrow down locations. In this paper, we introduce a novel metric, Recall vs Area (RvA), which measures the accuracy of estimated distributions of locations. RvA treats image geolocation results similarly to document retrieval, measuring recall as a function of area: For a ranked list of (possibly non-contiguous) predicted regions, we measure the accumulated area required for the region to contain the ground truth coordinate. This produces a curve similar to a precision-recall curve, where "precision" is replaced by square kilometers area, allowing evaluation of performance for different downstream search area budgets. Following directly from this view of the problem, we then examine a simple ensembling approach to global-scale image geolocation, which incorporates information from multiple sources to help address domain shift, and can readily incorporate multiple models, attribute predictors, and data sources. We study its effectiveness by combining the geolocation models GeoEstimation and the current SOTA GeoCLIP, with attribute predictors based on ORNL LandScan and ESA-CCI Land Cover. We find significant improvements in image geolocation for areas that are under-represented in the training set, particularly non-urban areas, on both Im2GPS3k and Street View images.
Audio scene monitoring using redundant un-localized microphone arrays
Mar 02, 2021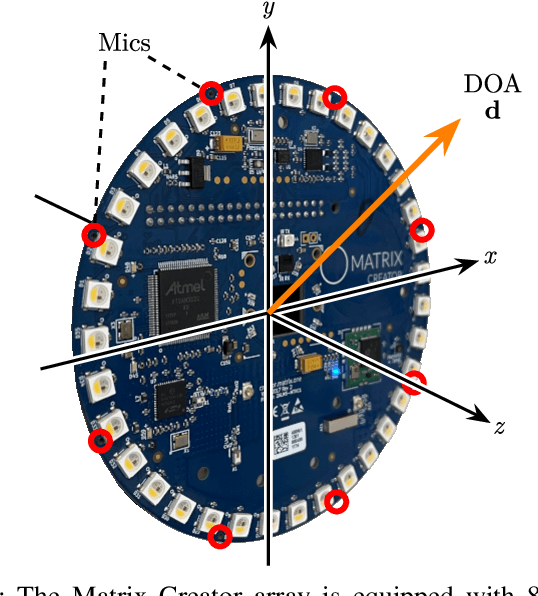
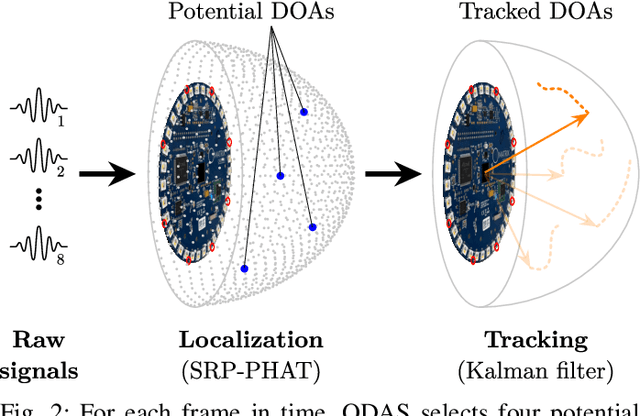
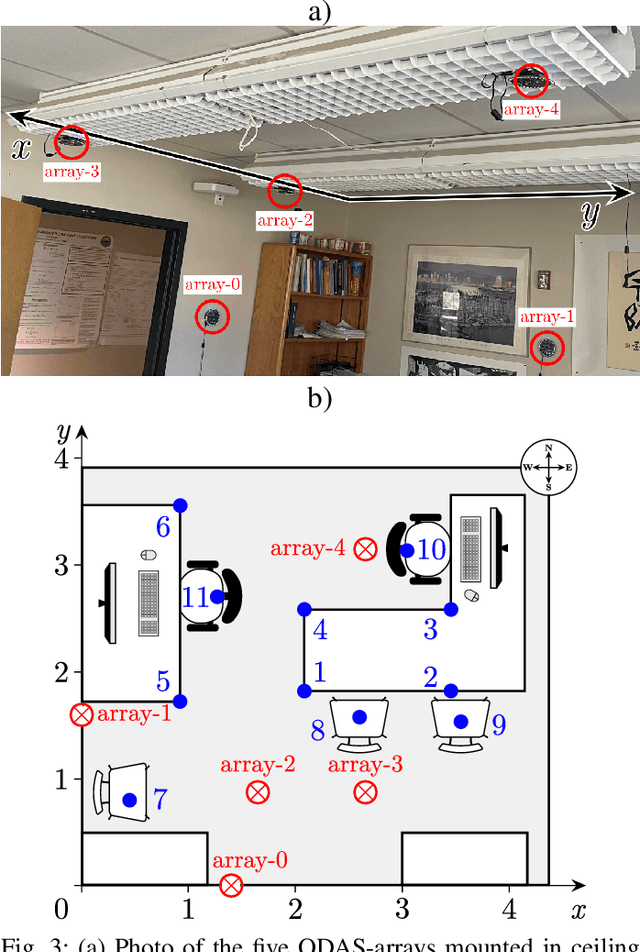

We present a system for localizing sound sources in a room with several microphone arrays. Unlike most existing approaches, the positions of the arrays in space are assumed to be unknown. Each circular array performs direction of arrival (DOA) estimation independently. The DOAs are then fed to a fusion center where they are concatenated and used to perform the localization based on two proposed methods, which require only few labeled source locations for calibration. The first proposed method is based on principal component analysis (PCA) of the observed DOA and does not require any calibration. The array cluster can then perform localization on a manifold defined by the PCA of concatenated DOAs over time. The second proposed method performs localization using an affine transformation between the DOA vectors and the room manifold. The PCA approach has fewer requirements on the training sequence, but is less robust to missing DOAs from one of the arrays. The approach is demonstrated with a set of five 8-microphone circular arrays, placed at unknown fixed locations in an office. Both the PCA approach and the direct approach can easily map out a rectangle based on a few calibration points with similar accuracy as calibration points. The methods demonstrated here provide a step towards monitoring activities in a smart home and require little installation effort as the array locations are not needed.
Semi-supervised source localization in reverberant environments with deep generative modeling
Jan 26, 2021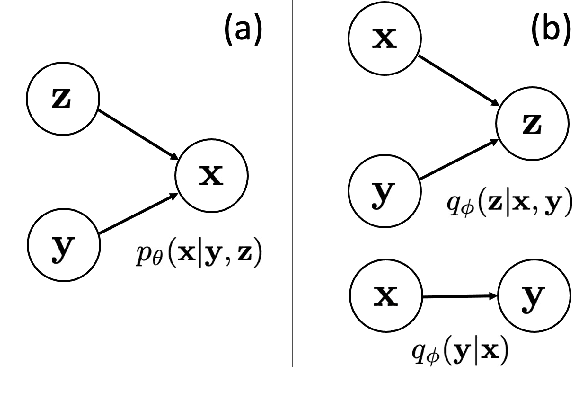

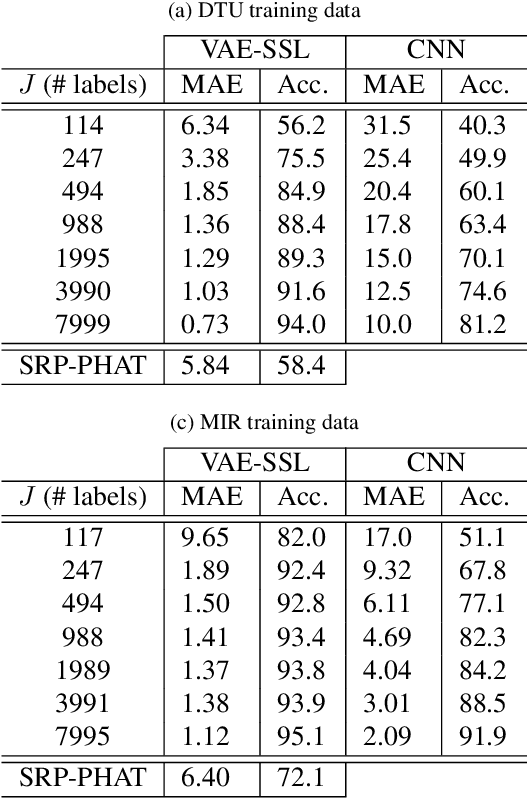
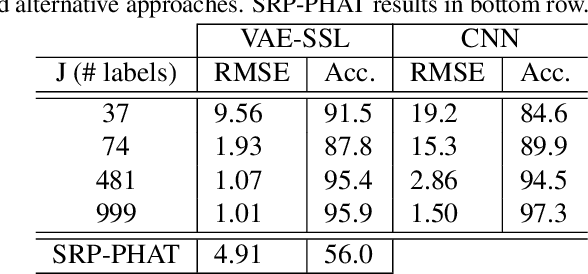
A semi-supervised approach to acoustic source localization in reverberant environments, based on deep generative modeling, is proposed. Localization in reverberant environments remains an open challenge. Even with large data volumes, the number of labels available for supervised learning in reverberant environments is usually small. We address this issue by performing semi-supervised learning (SSL) with convolutional variational autoencoders (VAEs) on speech signals in reverberant environments. The VAE is trained to generate the phase of relative transfer functions (RTFs) between microphones, in parallel with a direction of arrival (DOA) classifier based on RTF-phase, on both labeled and unlabeled RTF samples. In learning to perform these tasks, the VAE-SSL explicitly learns to separate the physical causes of the RTF-phase (i.e., source location) from distracting signal characteristics such as noise and speech activity. Relative to existing semi-supervised localization methods in acoustics, VAE-SSL is effectively an end-to-end processing approach which relies on minimal preprocessing of RTF-phase features. The VAE-SSL approach is compared with the steered response power with phase transform (SRP-PHAT) and fully supervised CNNs. We find that VAE-SSL can outperform both SRP-PHAT and CNN in label-limited scenarios. Further, the trained VAE-SSL system can generate new RTF-phase samples, which shows the VAE-SSL approach learns the physics of the acoustic environment. The generative modeling in VAE-SSL thus provides a means of interpreting the learned representations.
Semi-supervised source localization with deep generative modeling
May 27, 2020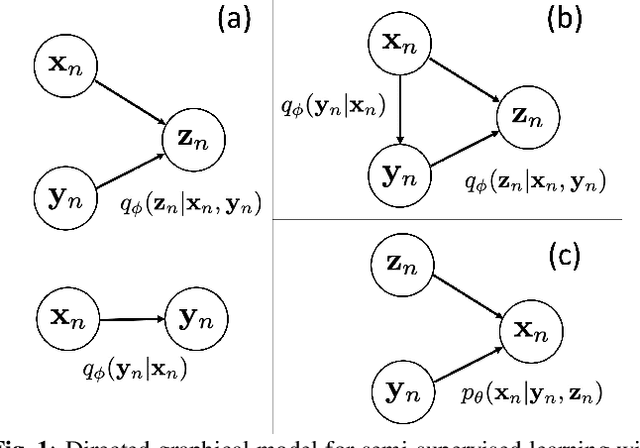
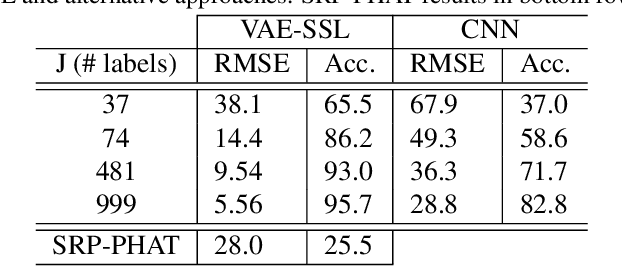
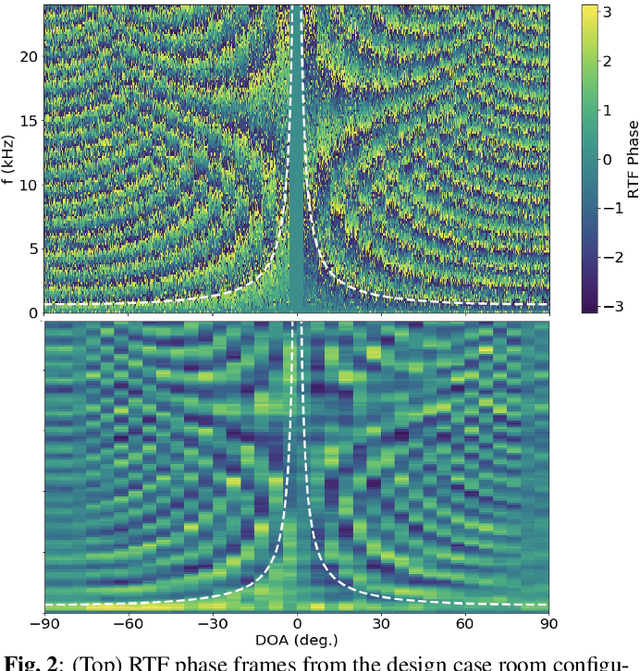
We develop a semi-supervised learning (SSL) approach for acoustic source localization based on deep generative modeling. Source localization in reverberant environments remains an open challenge, which machine learning (ML) has shown promise in addressing. While there are often large volumes of acoustic data in reverberant environments, the labels available for supervised learning are usually few. This limitation can impair practical implementation of ML. In our approach, we perform SSL with variational autoencoders (VAEs). This VAE-SSL approach uses a classifier network to estimate source location, and a VAE as a generative physical model. The VAE is trained to generate the phase of relative transfer functions (RTFs), in parallel with classifier training, on both labelled and unlabeled RTF samples. The VAE-SSL approach is compared with SRP-PHAT and convolutional neural networks. The VAE-SSL generated RTF phase patterns are assessed.
Machine learning in acoustics: a review
May 11, 2019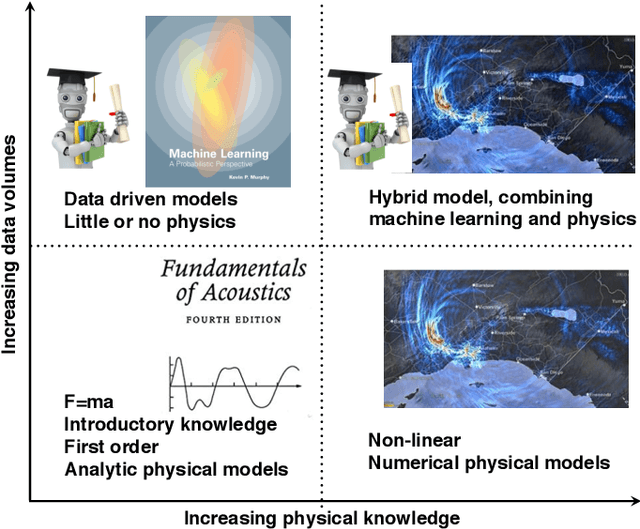
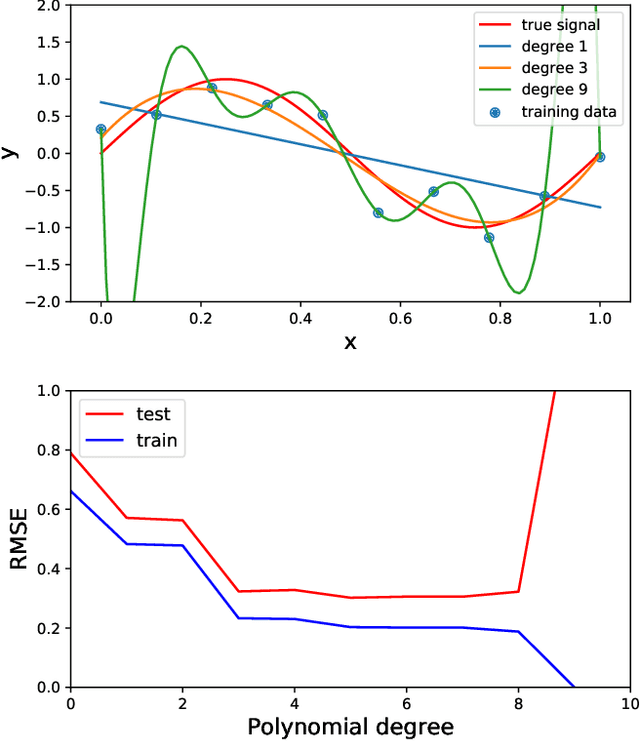
Acoustic data provide scientific and engineering insights in fields ranging from biology and communications to ocean and Earth science. We survey the recent advances and transformative potential of machine learning (ML), including deep learning, in the field of acoustics. ML is a broad family of statistical techniques for automatically detecting and utilizing patterns in data. Relative to conventional acoustics and signal processing, ML is data-driven. Given sufficient training data, ML can discover complex relationships between features. With large volumes of training data, ML can discover models describing complex acoustic phenomena such as human speech and reverberation. ML in acoustics is rapidly developing with compelling results and significant future promise. We first introduce ML, then highlight ML developments in five acoustics research areas: source localization in speech processing, source localization in ocean acoustics, bioacoustics, seismic exploration, and environmental sounds in everyday scenes.