 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttend Before Attention: Efficient and Scalable Video Understanding via Autoregressive Gazing
Mar 12, 2026Multi-modal large language models (MLLMs) have advanced general-purpose video understanding but struggle with long, high-resolution videos -- they process every pixel equally in their vision transformers (ViTs) or LLMs despite significant spatiotemporal redundancy. We introduce AutoGaze, a lightweight module that removes redundant patches before processed by a ViT or an MLLM. Trained with next-token prediction and reinforcement learning, AutoGaze autoregressively selects a minimal set of multi-scale patches that can reconstruct the video within a user-specified error threshold, eliminating redundancy while preserving information. Empirically, AutoGaze reduces visual tokens by 4x-100x and accelerates ViTs and MLLMs by up to 19x, enabling scaling MLLMs to 1K-frame 4K-resolution videos and achieving superior results on video benchmarks (e.g., 67.0% on VideoMME). Furthermore, we introduce HLVid: the first high-resolution, long-form video QA benchmark with 5-minute 4K-resolution videos, where an MLLM scaled with AutoGaze improves over the baseline by 10.1% and outperforms the previous best MLLM by 4.5%. Project page: https://autogaze.github.io/.
Progressive Checkerboards for Autoregressive Multiscale Image Generation
Feb 03, 2026A key challenge in autoregressive image generation is to efficiently sample independent locations in parallel, while still modeling mutual dependencies with serial conditioning. Some recent works have addressed this by conditioning between scales in a multiscale pyramid. Others have looked at parallelizing samples in a single image using regular partitions or randomized orders. In this work we examine a flexible, fixed ordering based on progressive checkerboards for multiscale autoregressive image generation. Our ordering draws samples in parallel from evenly spaced regions at each scale, maintaining full balance in all levels of a quadtree subdivision at each step. This enables effective conditioning both between and within scales. Intriguingly, we find evidence that in our balanced setting, a wide range of scale-up factors lead to similar results, so long as the total number of serial steps is constant. On class-conditional ImageNet, our method achieves competitive performance compared to recent state-of-the-art autoregressive systems with like model capacity, using fewer sampling steps.
Enhancing Worldwide Image Geolocation by Ensembling Satellite-Based Ground-Level Attribute Predictors
Jul 18, 2024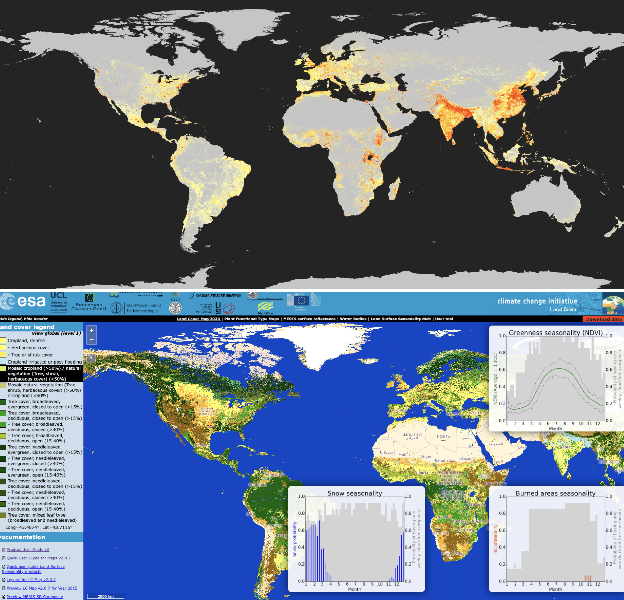
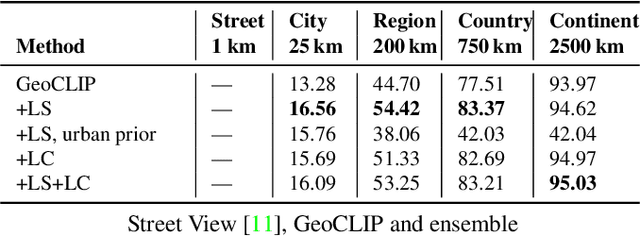

Geolocating images of a ground-level scene entails estimating the location on Earth where the picture was taken, in absence of GPS or other location metadata. Typically, methods are evaluated by measuring the Great Circle Distance (GCD) between a predicted location and ground truth. However, this measurement is limited because it only evaluates a single point, not estimates of regions or score heatmaps. This is especially important in applications to rural, wilderness and under-sampled areas, where finding the exact location may not be possible, and when used in aggregate systems that progressively narrow down locations. In this paper, we introduce a novel metric, Recall vs Area (RvA), which measures the accuracy of estimated distributions of locations. RvA treats image geolocation results similarly to document retrieval, measuring recall as a function of area: For a ranked list of (possibly non-contiguous) predicted regions, we measure the accumulated area required for the region to contain the ground truth coordinate. This produces a curve similar to a precision-recall curve, where "precision" is replaced by square kilometers area, allowing evaluation of performance for different downstream search area budgets. Following directly from this view of the problem, we then examine a simple ensembling approach to global-scale image geolocation, which incorporates information from multiple sources to help address domain shift, and can readily incorporate multiple models, attribute predictors, and data sources. We study its effectiveness by combining the geolocation models GeoEstimation and the current SOTA GeoCLIP, with attribute predictors based on ORNL LandScan and ESA-CCI Land Cover. We find significant improvements in image geolocation for areas that are under-represented in the training set, particularly non-urban areas, on both Im2GPS3k and Street View images.
Efficient Training of Deep Convolutional Neural Networks by Augmentation in Embedding Space
Feb 12, 2020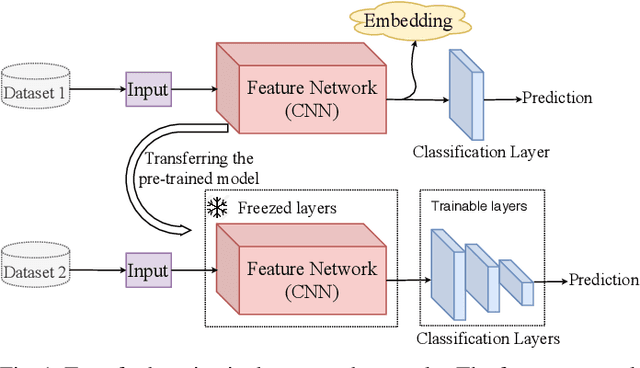
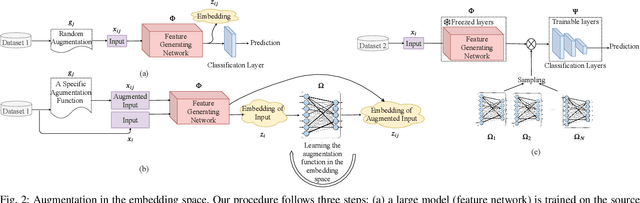
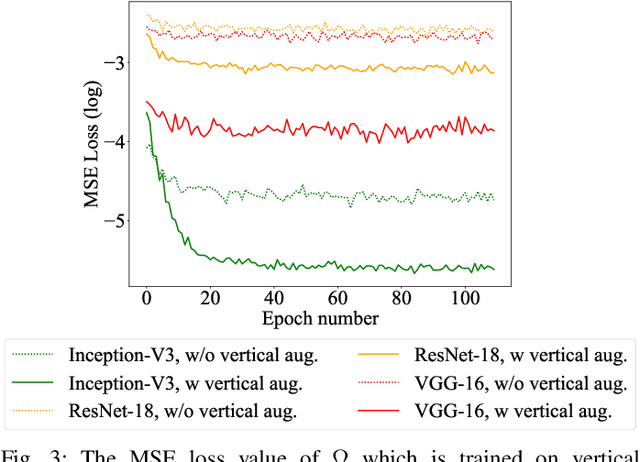
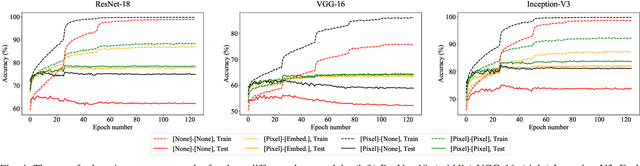
Recent advances in the field of artificial intelligence have been made possible by deep neural networks. In applications where data are scarce, transfer learning and data augmentation techniques are commonly used to improve the generalization of deep learning models. However, fine-tuning a transfer model with data augmentation in the raw input space has a high computational cost to run the full network for every augmented input. This is particularly critical when large models are implemented on embedded devices with limited computational and energy resources. In this work, we propose a method that replaces the augmentation in the raw input space with an approximate one that acts purely in the embedding space. Our experimental results show that the proposed method drastically reduces the computation, while the accuracy of models is negligibly compromised.
Coarse2Fine: A Two-stage Training Method for Fine-grained Visual Classification
Sep 06, 2019

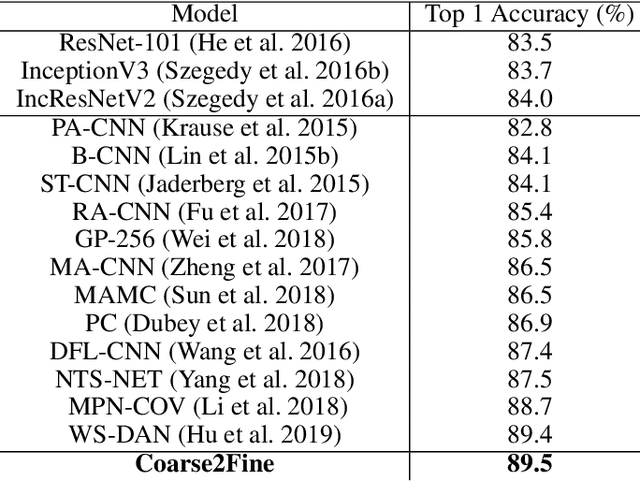
Small inter-class and large intra-class variations are the main challenges in fine-grained visual classification. Objects from different classes share visually similar structures and objects in the same class can have different poses and viewpoints. Therefore, the proper extraction of discriminative local features (e.g. bird's beak or car's headlight) is crucial. Most of the recent successes on this problem are based upon the attention models which can localize and attend the local discriminative objects parts. In this work, we propose a training method for visual attention networks, Coarse2Fine, which creates a differentiable path from the input space to the attended feature maps. Coarse2Fine learns an inverse mapping function from the attended feature maps to the informative regions in the raw image, which will guide the attention maps to better attend the fine-grained features. We show Coarse2Fine and orthogonal initialization of the attention weights can surpass the state-of-the-art accuracies on common fine-grained classification tasks.
Finding Task-Relevant Features for Few-Shot Learning by Category Traversal
May 27, 2019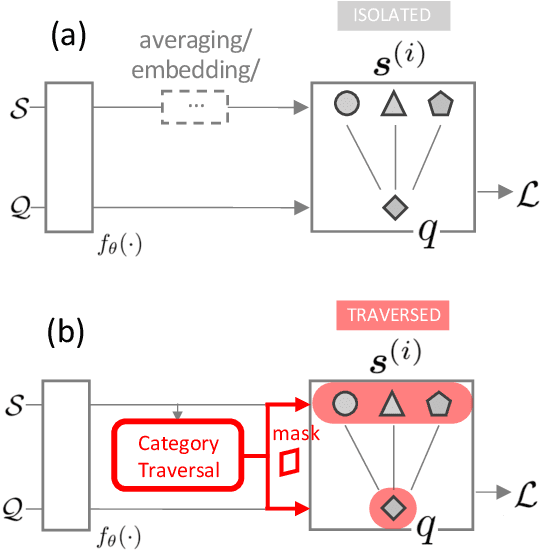
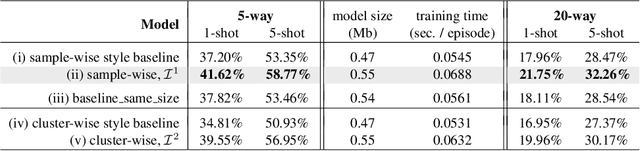
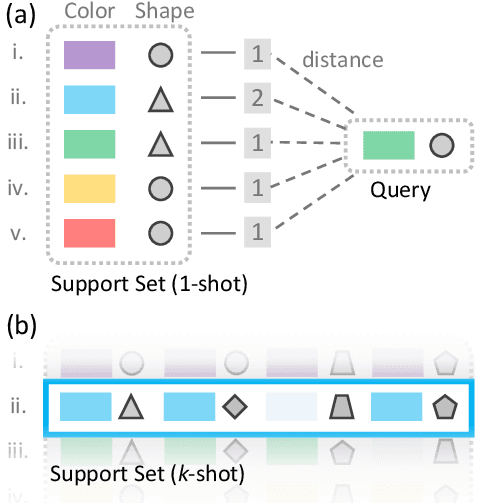
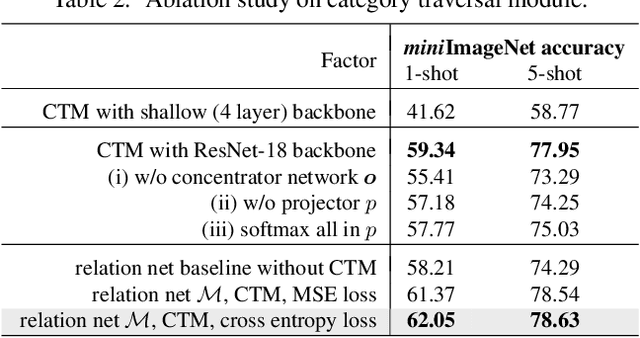
Few-shot learning is an important area of research. Conceptually, humans are readily able to understand new concepts given just a few examples, while in more pragmatic terms, limited-example training situations are common in practice. Recent effective approaches to few-shot learning employ a metric-learning framework to learn a feature similarity comparison between a query (test) example, and the few support (training) examples. However, these approaches treat each support class independently from one another, never looking at the entire task as a whole. Because of this, they are constrained to use a single set of features for all possible test-time tasks, which hinders the ability to distinguish the most relevant dimensions for the task at hand. In this work, we introduce a Category Traversal Module that can be inserted as a plug-and-play module into most metric-learning based few-shot learners. This component traverses across the entire support set at once, identifying task-relevant features based on both intra-class commonality and inter-class uniqueness in the feature space. Incorporating our module improves performance considerably (5%-10% relative) over baseline systems on both mini-ImageNet and tieredImageNet benchmarks, with overall performance competitive with recent state-of-the-art systems.
Gradient Agreement as an Optimization Objective for Meta-Learning
Oct 18, 2018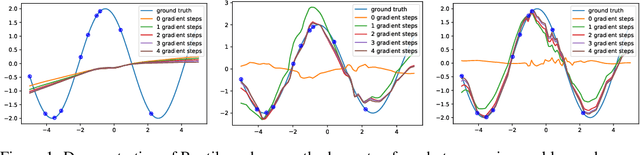
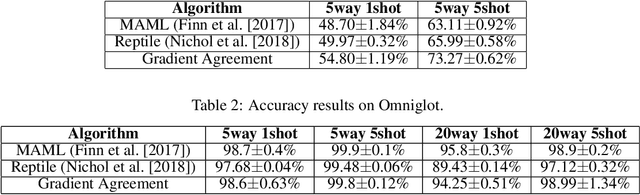
This paper presents a novel optimization method for maximizing generalization over tasks in meta-learning. The goal of meta-learning is to learn a model for an agent adapting rapidly when presented with previously unseen tasks. Tasks are sampled from a specific distribution which is assumed to be similar for both seen and unseen tasks. We focus on a family of meta-learning methods learning initial parameters of a base model which can be fine-tuned quickly on a new task, by few gradient steps (MAML). Our approach is based on pushing the parameters of the model to a direction in which tasks have more agreement upon. If the gradients of a task agree with the parameters update vector, then their inner product will be a large positive value. As a result, given a batch of tasks to be optimized for, we associate a positive (negative) weight to the loss function of a task, if the inner product between its gradients and the average of the gradients of all tasks in the batch is a positive (negative) value. Therefore, the degree of the contribution of a task to the parameter updates is controlled by introducing a set of weights on the loss function of the tasks. Our method can be easily integrated with the current meta-learning algorithms for neural networks. Our experiments demonstrate that it yields models with better generalization compared to MAML and Reptile.
A Meta-Learning Approach for Custom Model Training
Sep 21, 2018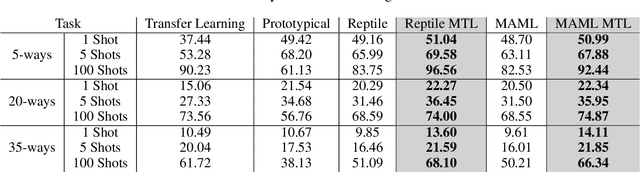

Transfer-learning and meta-learning are two effective methods to apply knowledge learned from large data sources to new tasks. In few-class, few-shot target task settings (i.e. when there are only a few classes and training examples available in the target task), meta-learning approaches that optimize for future task learning have outperformed the typical transfer approach of initializing model weights from a pre-trained starting point. But as we experimentally show, meta-learning algorithms that work well in the few-class setting do not generalize well in many-shot and many-class cases. In this paper, we propose a joint training approach that combines both transfer-learning and meta-learning. Benefiting from the advantages of each, our method obtains improved generalization performance on unseen target tasks in both few- and many-class and few- and many-shot scenarios.
Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture
Dec 17, 2015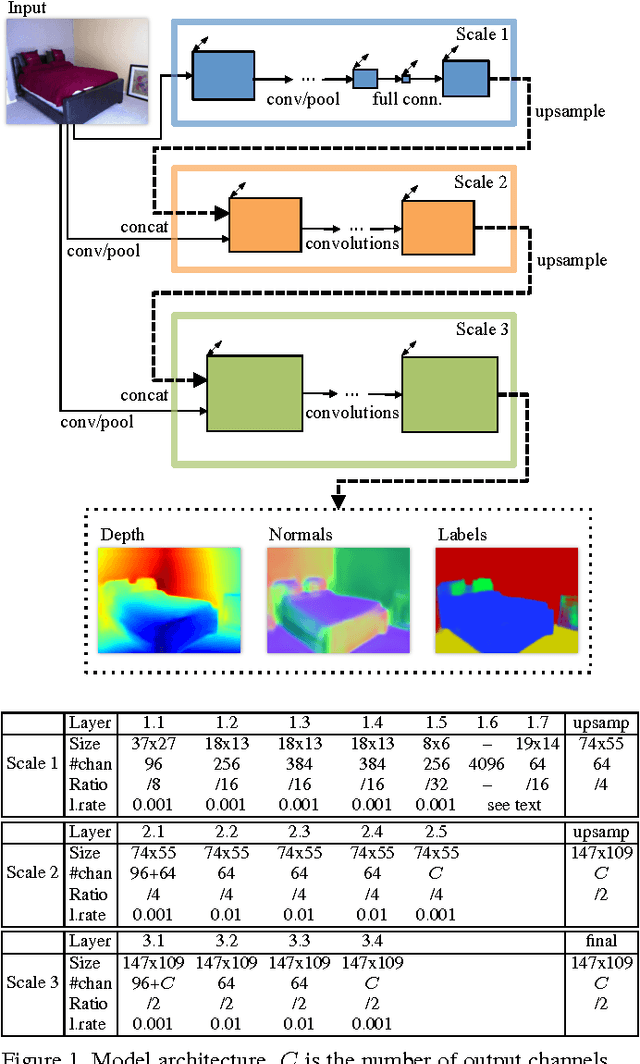

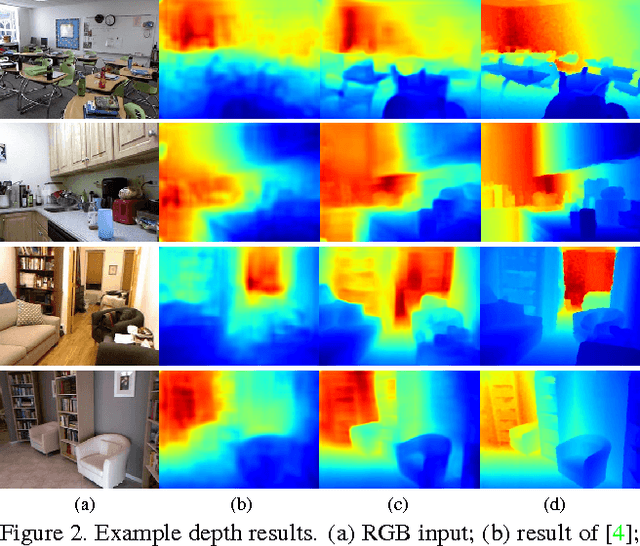
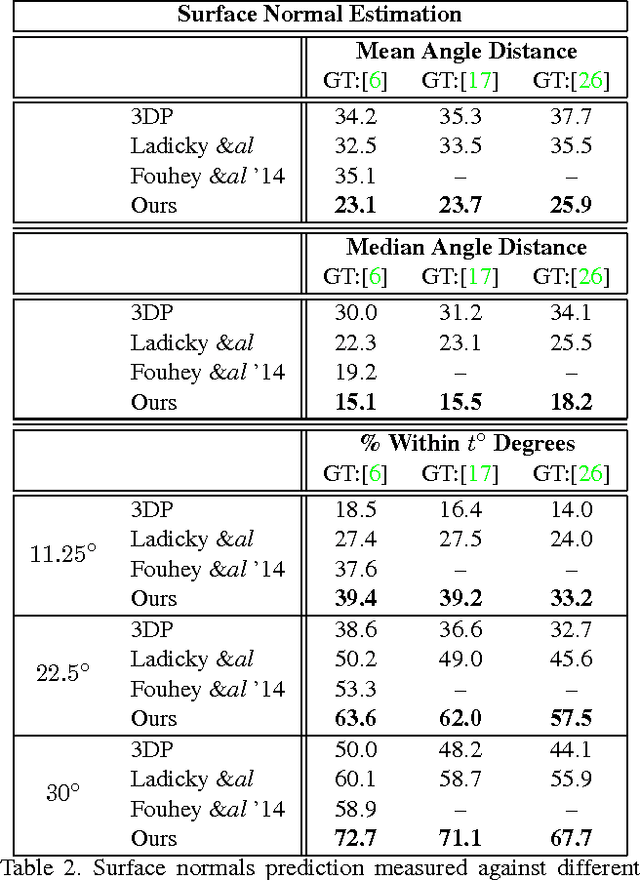
In this paper we address three different computer vision tasks using a single basic architecture: depth prediction, surface normal estimation, and semantic labeling. We use a multiscale convolutional network that is able to adapt easily to each task using only small modifications, regressing from the input image to the output map directly. Our method progressively refines predictions using a sequence of scales, and captures many image details without any superpixels or low-level segmentation. We achieve state-of-the-art performance on benchmarks for all three tasks.
Unsupervised Learning of Spatiotemporally Coherent Metrics
Sep 08, 2015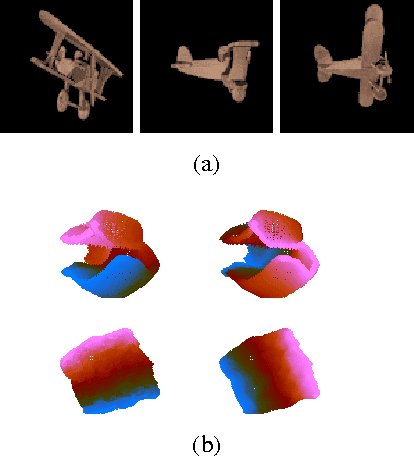

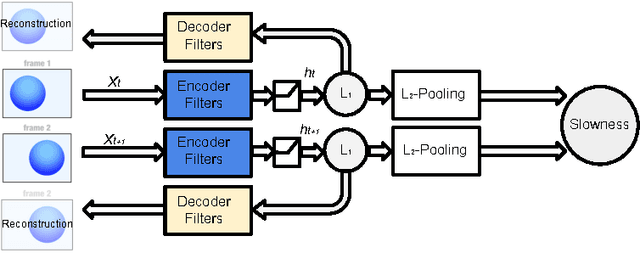
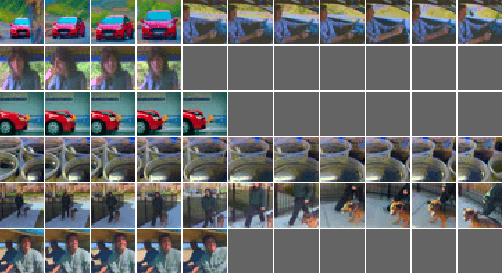
Current state-of-the-art classification and detection algorithms rely on supervised training. In this work we study unsupervised feature learning in the context of temporally coherent video data. We focus on feature learning from unlabeled video data, using the assumption that adjacent video frames contain semantically similar information. This assumption is exploited to train a convolutional pooling auto-encoder regularized by slowness and sparsity. We establish a connection between slow feature learning to metric learning and show that the trained encoder can be used to define a more temporally and semantically coherent metric.