Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture
Paper and Code
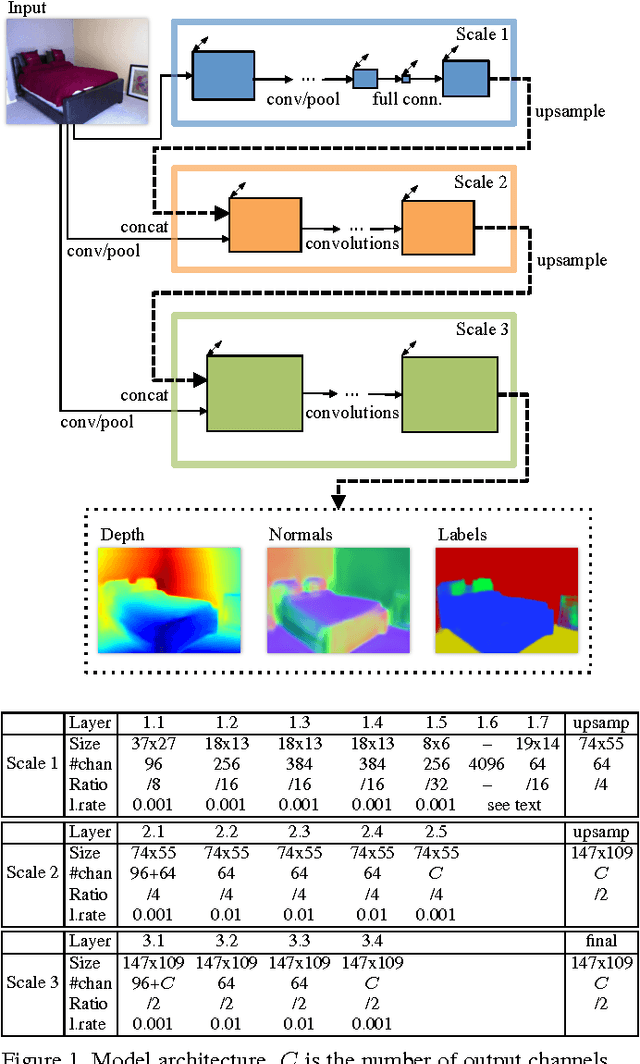

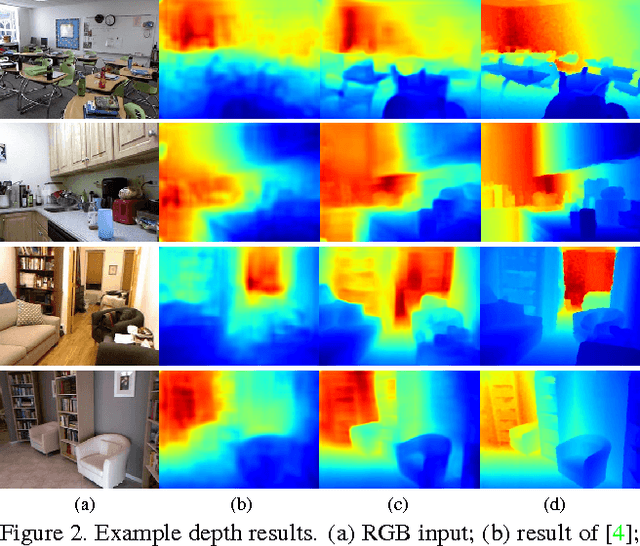
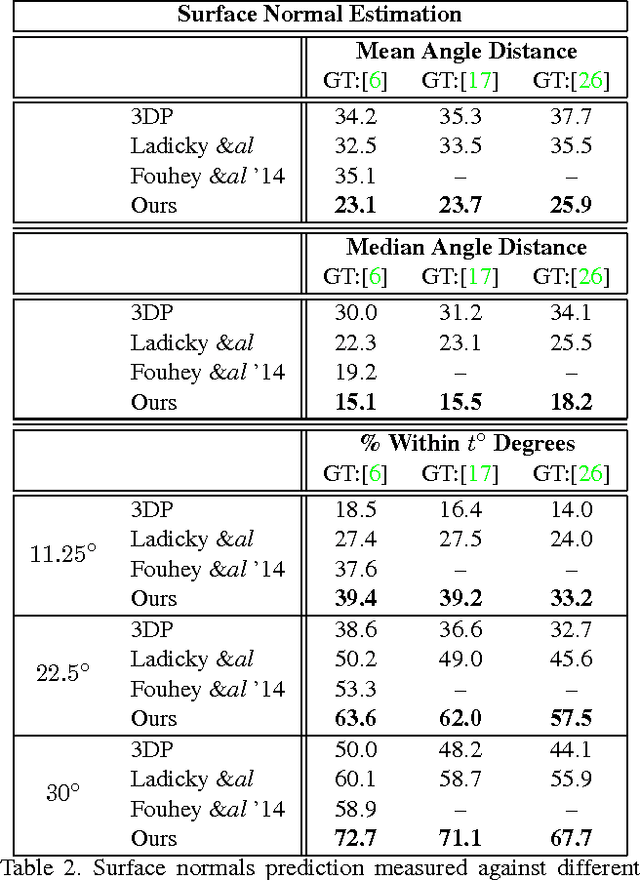
In this paper we address three different computer vision tasks using a single basic architecture: depth prediction, surface normal estimation, and semantic labeling. We use a multiscale convolutional network that is able to adapt easily to each task using only small modifications, regressing from the input image to the output map directly. Our method progressively refines predictions using a sequence of scales, and captures many image details without any superpixels or low-level segmentation. We achieve state-of-the-art performance on benchmarks for all three tasks.
View paper on