 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNN-PARS: A Parallelized Neural Network Based Circuit Simulation Framework
Feb 13, 2020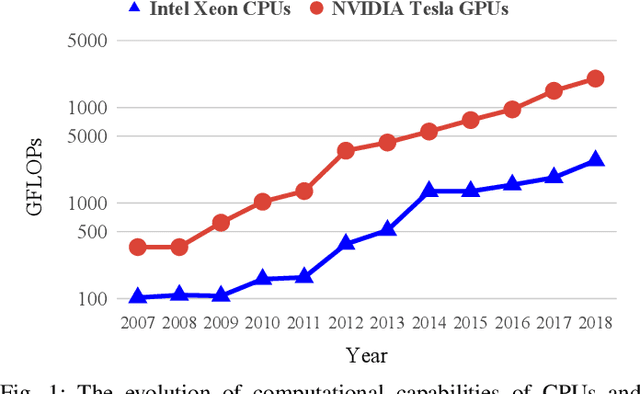
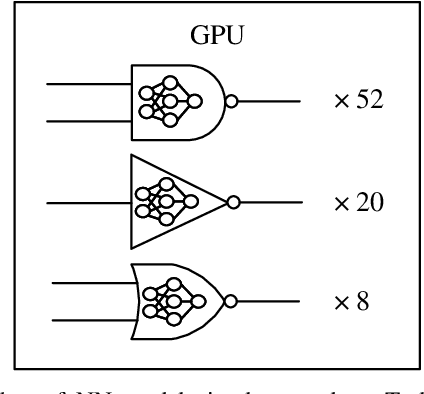
The shrinking of transistor geometries as well as the increasing complexity of integrated circuits, significantly aggravate nonlinear design behavior. This demands accurate and fast circuit simulation to meet the design quality and time-to-market constraints. The existing circuit simulators which utilize lookup tables and/or closed-form expressions are either slow or inaccurate in analyzing the nonlinear behavior of designs with billions of transistors. To address these shortcomings, we present NN-PARS, a neural network (NN) based and parallelized circuit simulation framework with optimized event-driven scheduling of simulation tasks to maximize concurrency, according to the underlying GPU parallel processing capabilities. NN-PARS replaces the required memory queries in traditional techniques with parallelized NN-based computation tasks. Experimental results show that compared to a state-of-the-art current-based simulation method, NN-PARS reduces the simulation time by over two orders of magnitude in large circuits. NN-PARS also provides high accuracy levels in signal waveform calculations, with less than $2\%$ error compared to HSPICE.
CSM-NN: Current Source Model Based Logic Circuit Simulation -- A Neural Network Approach
Feb 13, 2020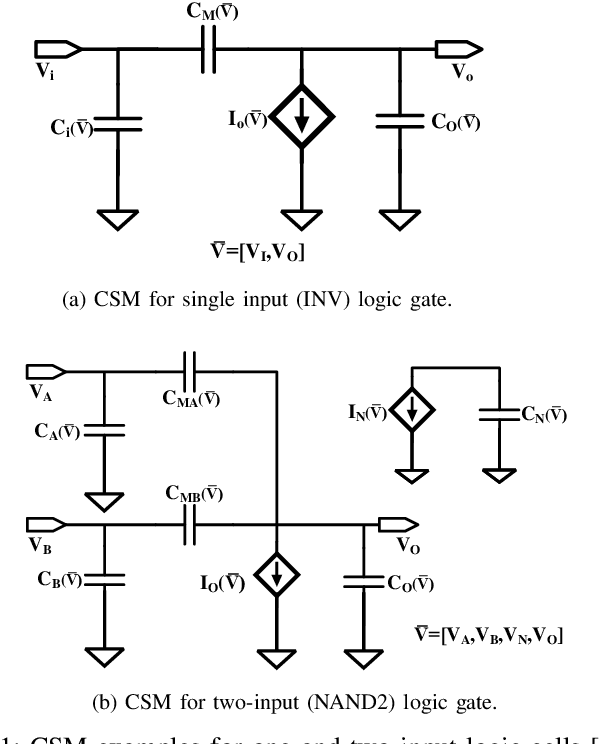
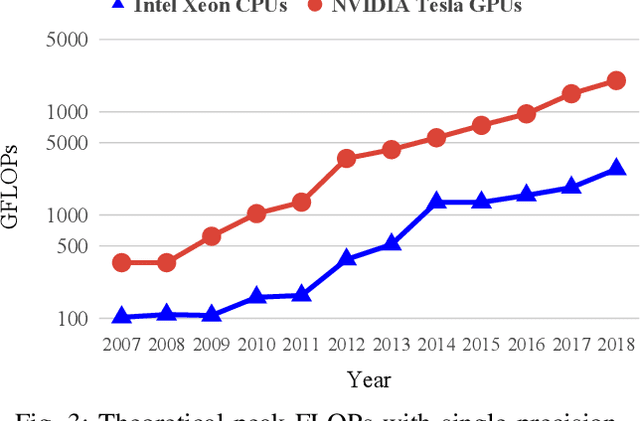

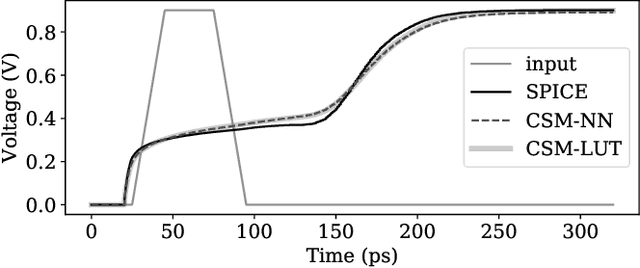
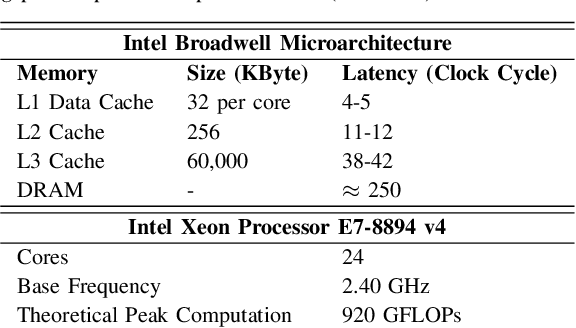
The miniaturization of transistors down to 5nm and beyond, plus the increasing complexity of integrated circuits, significantly aggravate short channel effects, and demand analysis and optimization of more design corners and modes. Simulators need to model output variables related to circuit timing, power, noise, etc., which exhibit nonlinear behavior. The existing simulation and sign-off tools, based on a combination of closed-form expressions and lookup tables are either inaccurate or slow, when dealing with circuits with more than billions of transistors. In this work, we present CSM-NN, a scalable simulation framework with optimized neural network structures and processing algorithms. CSM-NN is aimed at optimizing the simulation time by accounting for the latency of the required memory query and computation, given the underlying CPU and GPU parallel processing capabilities. Experimental results show that CSM-NN reduces the simulation time by up to $6\times$ compared to a state-of-the-art current source model based simulator running on a CPU. This speedup improves by up to $15\times$ when running on a GPU. CSM-NN also provides high accuracy levels, with less than $2\%$ error, compared to HSPICE.
Efficient Training of Deep Convolutional Neural Networks by Augmentation in Embedding Space
Feb 12, 2020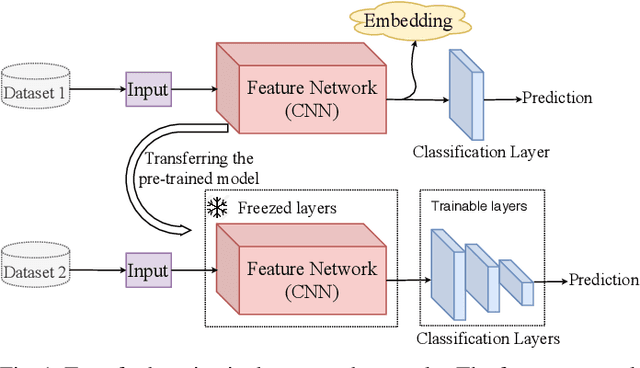
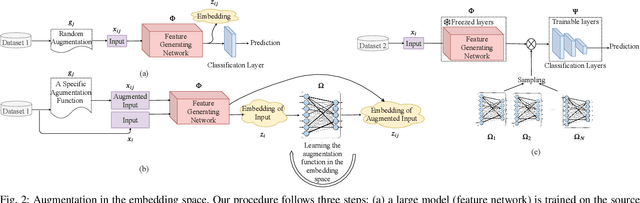
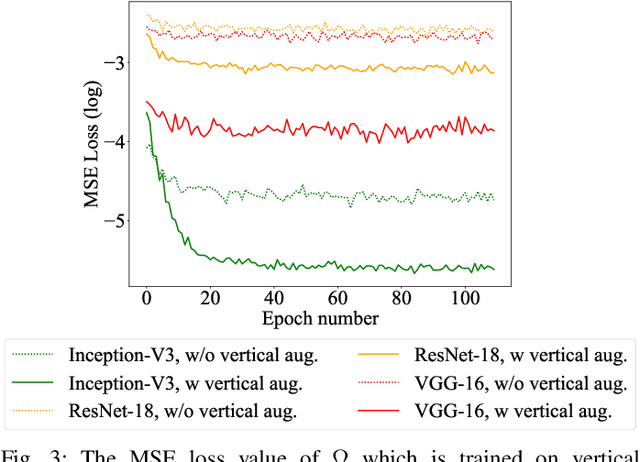
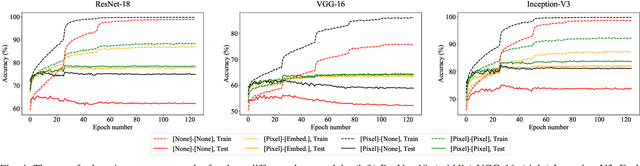
Recent advances in the field of artificial intelligence have been made possible by deep neural networks. In applications where data are scarce, transfer learning and data augmentation techniques are commonly used to improve the generalization of deep learning models. However, fine-tuning a transfer model with data augmentation in the raw input space has a high computational cost to run the full network for every augmented input. This is particularly critical when large models are implemented on embedded devices with limited computational and energy resources. In this work, we propose a method that replaces the augmentation in the raw input space with an approximate one that acts purely in the embedding space. Our experimental results show that the proposed method drastically reduces the computation, while the accuracy of models is negligibly compromised.
A Meta-Learning Approach for Custom Model Training
Sep 21, 2018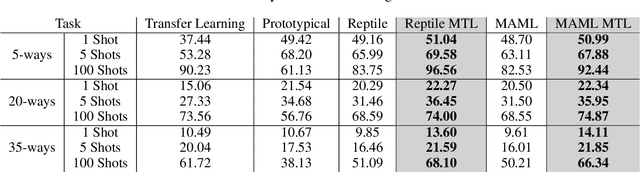

Transfer-learning and meta-learning are two effective methods to apply knowledge learned from large data sources to new tasks. In few-class, few-shot target task settings (i.e. when there are only a few classes and training examples available in the target task), meta-learning approaches that optimize for future task learning have outperformed the typical transfer approach of initializing model weights from a pre-trained starting point. But as we experimentally show, meta-learning algorithms that work well in the few-class setting do not generalize well in many-shot and many-class cases. In this paper, we propose a joint training approach that combines both transfer-learning and meta-learning. Benefiting from the advantages of each, our method obtains improved generalization performance on unseen target tasks in both few- and many-class and few- and many-shot scenarios.
JointDNN: An Efficient Training and Inference Engine for Intelligent Mobile Cloud Computing Services
Jan 25, 2018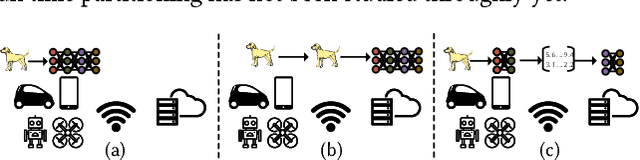

Deep neural networks are among the most influential architectures of deep learning algorithms, being deployed in many mobile intelligent applications. End-side services, such as intelligent personal assistants (IPAs), autonomous cars, and smart home services often employ either simple local models or complex remote models on the cloud. Mobile-only and cloud-only computations are currently the status quo approaches. In this paper, we propose an efficient, adaptive, and practical engine, JointDNN, for collaborative computation between a mobile device and cloud for DNNs in both inference and training phase. JointDNN not only provides an energy and performance efficient method of querying DNNs for the mobile side, but also benefits the cloud server by reducing the amount of its workload and communications compared to the cloud-only approach. Given the DNN architecture, we investigate the efficiency of processing some layers on the mobile device and some layers on the cloud server. We provide optimization formulations at layer granularity for forward and backward propagation in DNNs, which can adapt to mobile battery limitations and cloud server load constraints and quality of service. JointDNN achieves up to 18X and 32X reductions on the latency and mobile energy consumption of querying DNNs, respectively.