 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Training of Deep Convolutional Neural Networks by Augmentation in Embedding Space
Paper and Code
Feb 12, 2020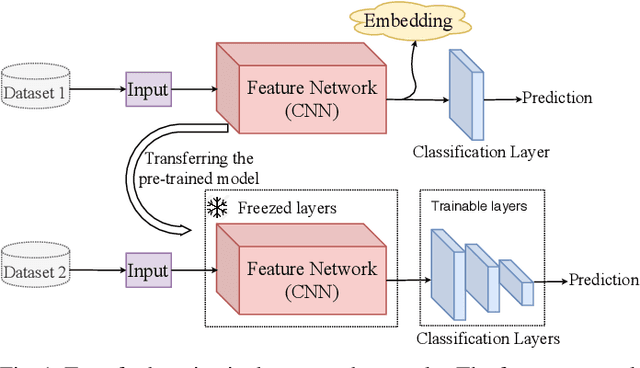
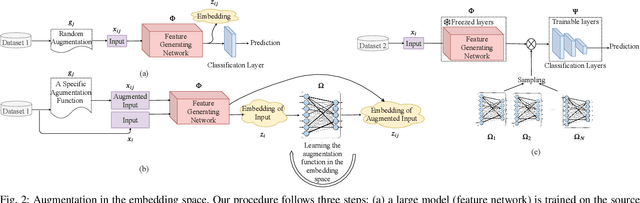
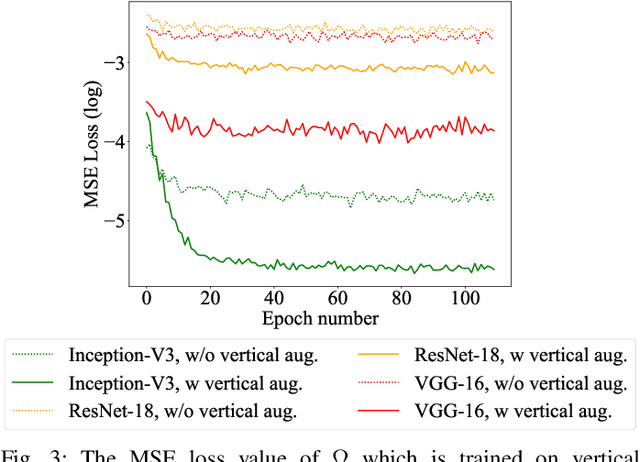
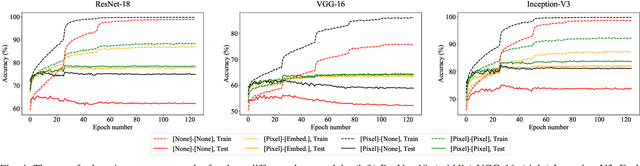
Recent advances in the field of artificial intelligence have been made possible by deep neural networks. In applications where data are scarce, transfer learning and data augmentation techniques are commonly used to improve the generalization of deep learning models. However, fine-tuning a transfer model with data augmentation in the raw input space has a high computational cost to run the full network for every augmented input. This is particularly critical when large models are implemented on embedded devices with limited computational and energy resources. In this work, we propose a method that replaces the augmentation in the raw input space with an approximate one that acts purely in the embedding space. Our experimental results show that the proposed method drastically reduces the computation, while the accuracy of models is negligibly compromised.