Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Learning of Spatiotemporally Coherent Metrics
Paper and Code
Sep 08, 2015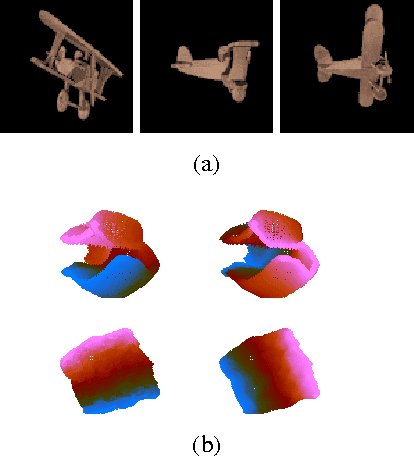

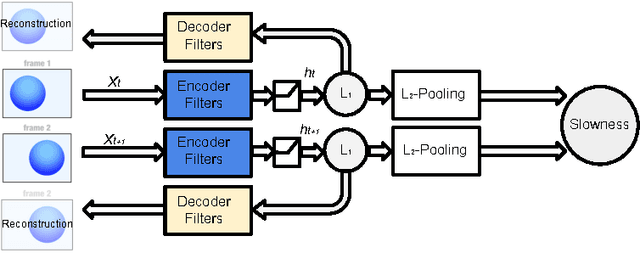
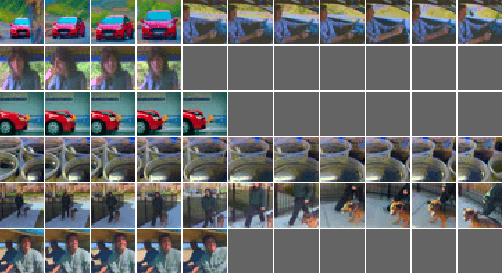
Current state-of-the-art classification and detection algorithms rely on supervised training. In this work we study unsupervised feature learning in the context of temporally coherent video data. We focus on feature learning from unlabeled video data, using the assumption that adjacent video frames contain semantically similar information. This assumption is exploited to train a convolutional pooling auto-encoder regularized by slowness and sparsity. We establish a connection between slow feature learning to metric learning and show that the trained encoder can be used to define a more temporally and semantically coherent metric.
* To appear at ICCV2015
View paper on