 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Task-Relevant Features for Few-Shot Learning by Category Traversal
May 27, 2019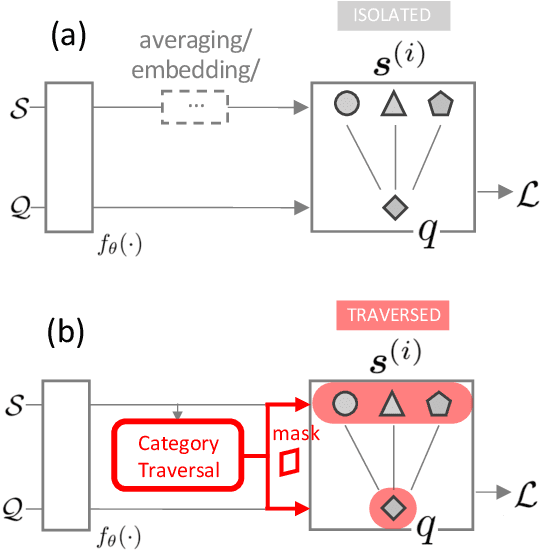
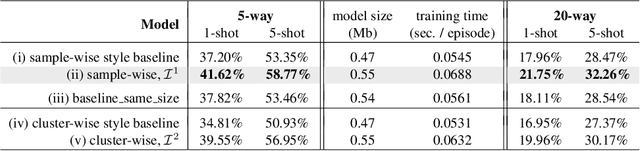
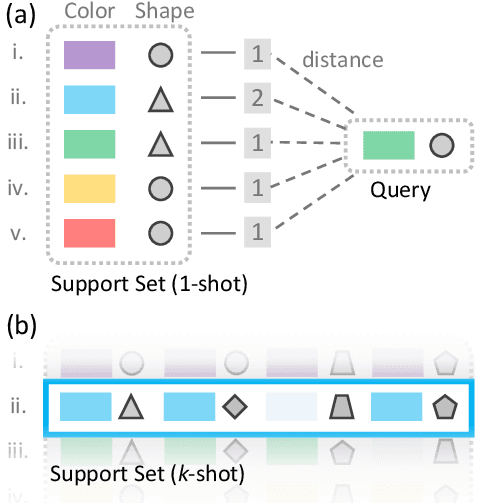
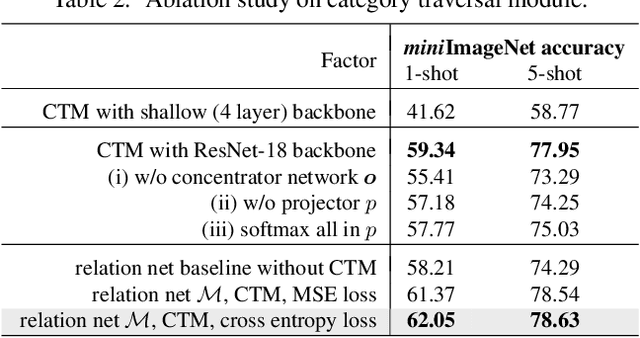
Few-shot learning is an important area of research. Conceptually, humans are readily able to understand new concepts given just a few examples, while in more pragmatic terms, limited-example training situations are common in practice. Recent effective approaches to few-shot learning employ a metric-learning framework to learn a feature similarity comparison between a query (test) example, and the few support (training) examples. However, these approaches treat each support class independently from one another, never looking at the entire task as a whole. Because of this, they are constrained to use a single set of features for all possible test-time tasks, which hinders the ability to distinguish the most relevant dimensions for the task at hand. In this work, we introduce a Category Traversal Module that can be inserted as a plug-and-play module into most metric-learning based few-shot learners. This component traverses across the entire support set at once, identifying task-relevant features based on both intra-class commonality and inter-class uniqueness in the feature space. Incorporating our module improves performance considerably (5%-10% relative) over baseline systems on both mini-ImageNet and tieredImageNet benchmarks, with overall performance competitive with recent state-of-the-art systems.
Can the early human visual system compete with Deep Neural Networks?
Oct 12, 2017
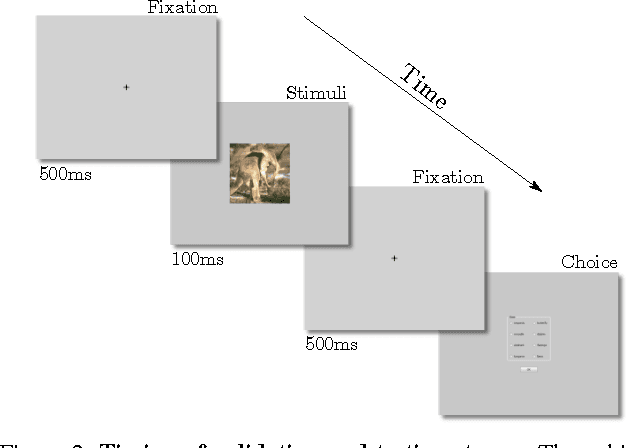

We study and compare the human visual system and state-of-the-art deep neural networks on classification of distorted images. Different from previous works, we limit the display time to 100ms to test only the early mechanisms of the human visual system, without allowing time for any eye movements or other higher level processes. Our findings show that the human visual system still outperforms modern deep neural networks under blurry and noisy images. These findings motivate future research into developing more robust deep networks.
A Study and Comparison of Human and Deep Learning Recognition Performance Under Visual Distortions
May 06, 2017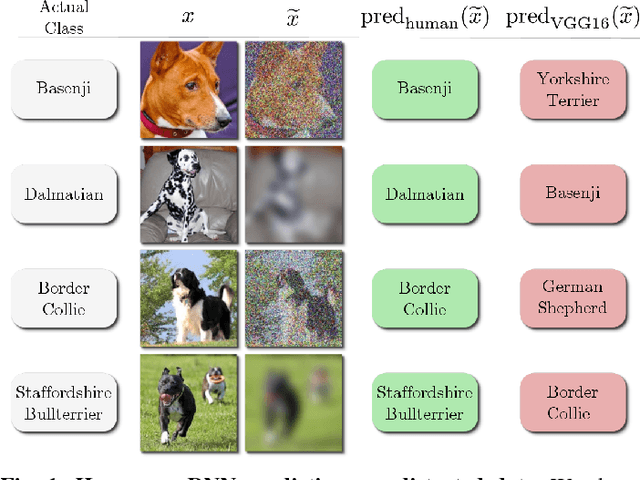


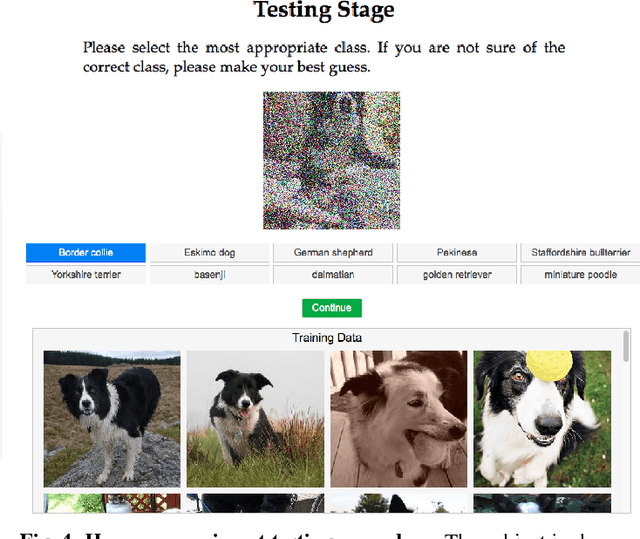
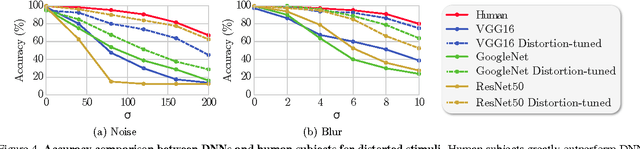
Deep neural networks (DNNs) achieve excellent performance on standard classification tasks. However, under image quality distortions such as blur and noise, classification accuracy becomes poor. In this work, we compare the performance of DNNs with human subjects on distorted images. We show that, although DNNs perform better than or on par with humans on good quality images, DNN performance is still much lower than human performance on distorted images. We additionally find that there is little correlation in errors between DNNs and human subjects. This could be an indication that the internal representation of images are different between DNNs and the human visual system. These comparisons with human performance could be used to guide future development of more robust DNNs.
Quality Resilient Deep Neural Networks
Mar 23, 2017
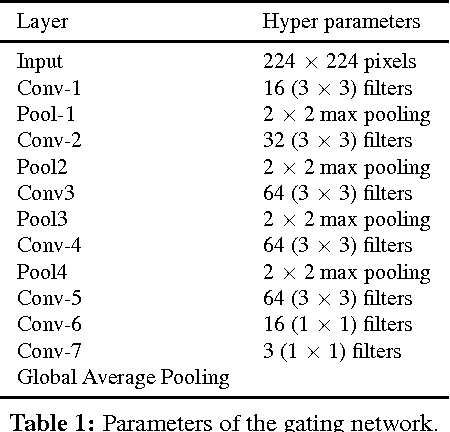
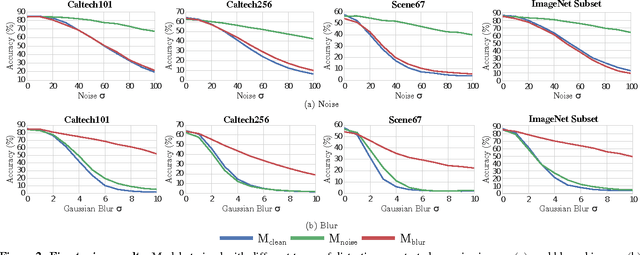
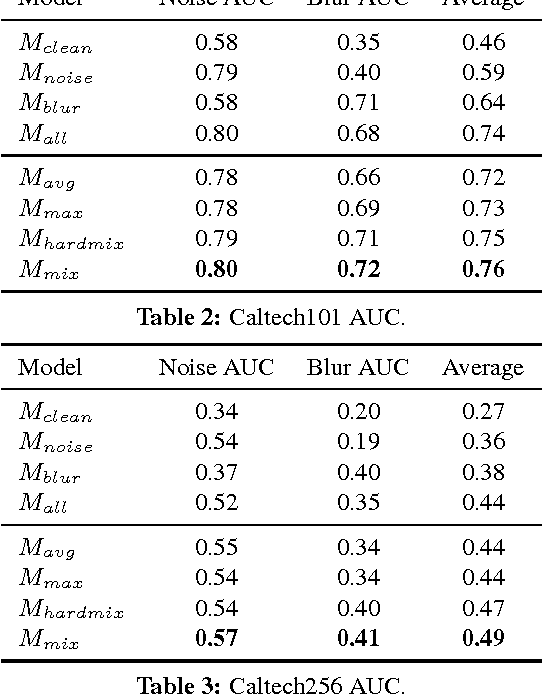
We study deep neural networks for classification of images with quality distortions. We first show that networks fine-tuned on distorted data greatly outperform the original networks when tested on distorted data. However, fine-tuned networks perform poorly on quality distortions that they have not been trained for. We propose a mixture of experts ensemble method that is robust to different types of distortions. The "experts" in our model are trained on a particular type of distortion. The output of the model is a weighted sum of the expert models, where the weights are determined by a separate gating network. The gating network is trained to predict optimal weights for a particular distortion type and level. During testing, the network is blind to the distortion level and type, yet can still assign appropriate weights to the expert models. We additionally investigate weight sharing methods for the mixture model and show that improved performance can be achieved with a large reduction in the number of unique network parameters.
Visual Saliency Prediction Using a Mixture of Deep Neural Networks
Feb 01, 2017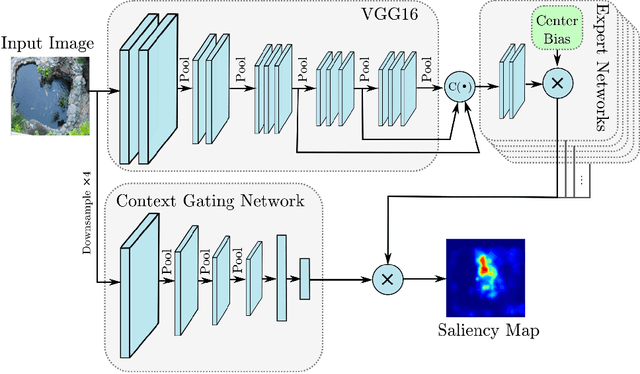
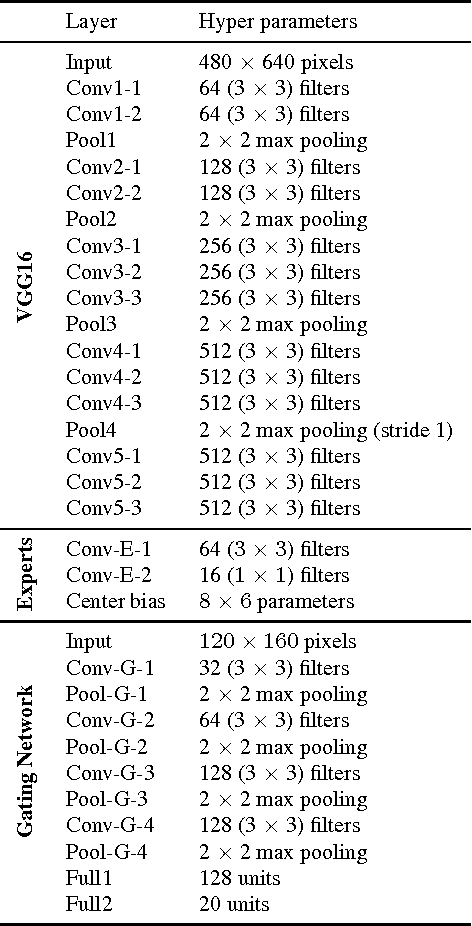

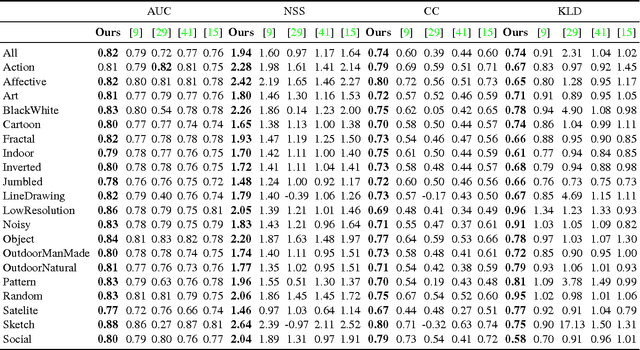
Visual saliency models have recently begun to incorporate deep learning to achieve predictive capacity much greater than previous unsupervised methods. However, most existing models predict saliency using local mechanisms limited to the receptive field of the network. We propose a model that incorporates global scene semantic information in addition to local information gathered by a convolutional neural network. Our model is formulated as a mixture of experts. Each expert network is trained to predict saliency for a set of closely related images. The final saliency map is computed as a weighted mixture of the expert networks' output, with weights determined by a separate gating network. This gating network is guided by global scene information to predict weights. The expert networks and the gating network are trained simultaneously in an end-to-end manner. We show that our mixture formulation leads to improvement in performance over an otherwise identical non-mixture model that does not incorporate global scene information.
Understanding How Image Quality Affects Deep Neural Networks
Apr 21, 2016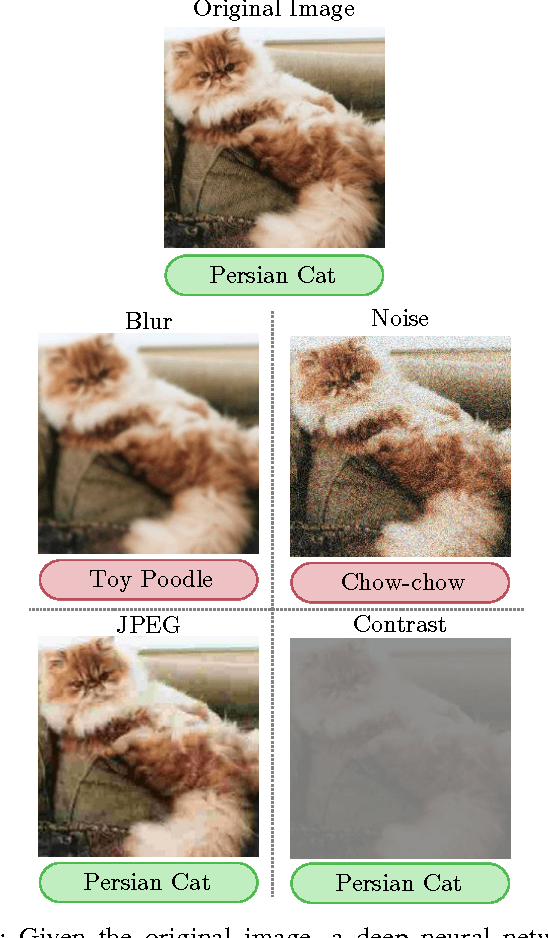
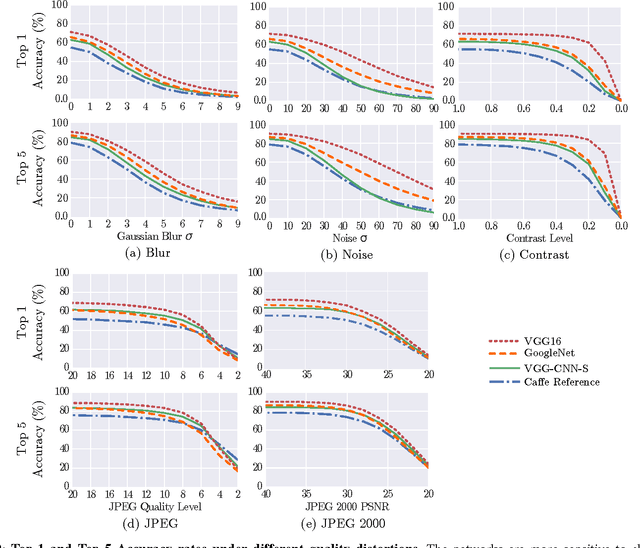

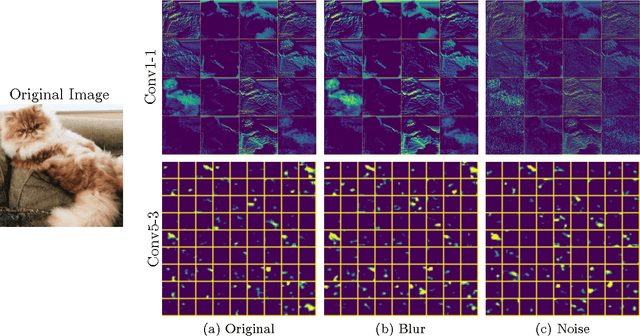
Image quality is an important practical challenge that is often overlooked in the design of machine vision systems. Commonly, machine vision systems are trained and tested on high quality image datasets, yet in practical applications the input images can not be assumed to be of high quality. Recently, deep neural networks have obtained state-of-the-art performance on many machine vision tasks. In this paper we provide an evaluation of 4 state-of-the-art deep neural network models for image classification under quality distortions. We consider five types of quality distortions: blur, noise, contrast, JPEG, and JPEG2000 compression. We show that the existing networks are susceptible to these quality distortions, particularly to blur and noise. These results enable future work in developing deep neural networks that are more invariant to quality distortions.