 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefending against Adversarial Attacks through Resilient Feature Regeneration
Jun 08, 2019
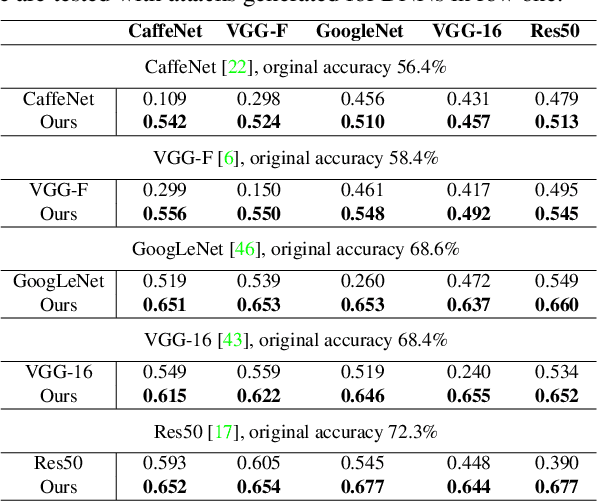
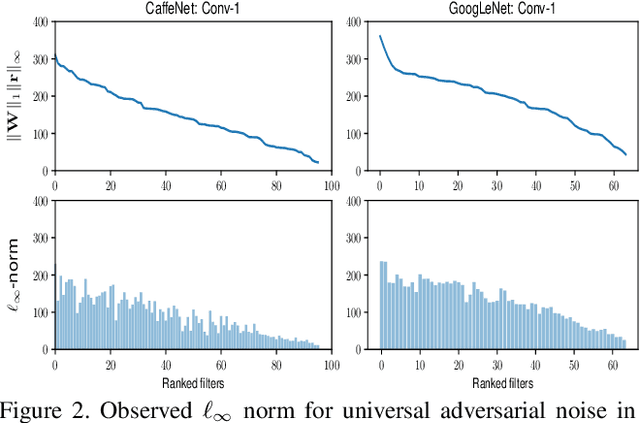
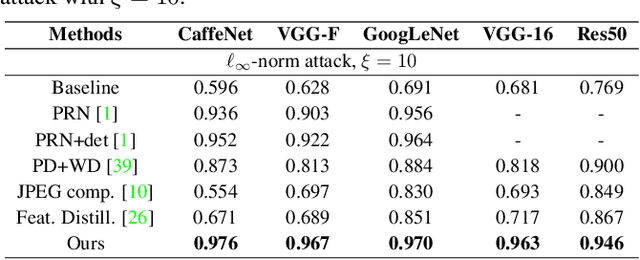
Deep neural network (DNN) predictions have been shown to be vulnerable to carefully crafted adversarial perturbations. Specifically, so-called universal adversarial perturbations are image-agnostic perturbations that can be added to any image and can fool a target network into making erroneous predictions. Departing from existing adversarial defense strategies, which work in the image domain, we present a novel defense which operates in the DNN feature domain and effectively defends against such universal adversarial attacks. Our approach identifies pre-trained convolutional features that are most vulnerable to adversarial noise and deploys defender units which transform (regenerate) these DNN filter activations into noise-resilient features, guarding against unseen adversarial perturbations. The proposed defender units are trained using a target loss on synthetic adversarial perturbations, which we generate with a novel efficient synthesis method. We validate the proposed method for different DNN architectures, and demonstrate that it outperforms existing defense strategies across network architectures by more than 10% in restored accuracy. Moreover, we demonstrate that the approach also improves resilience of DNNs to other unseen adversarial attacks.
Synthesized Texture Quality Assessment via Multi-scale Spatial and Statistical Texture Attributes of Image and Gradient Magnitude Coefficients
Apr 26, 2018
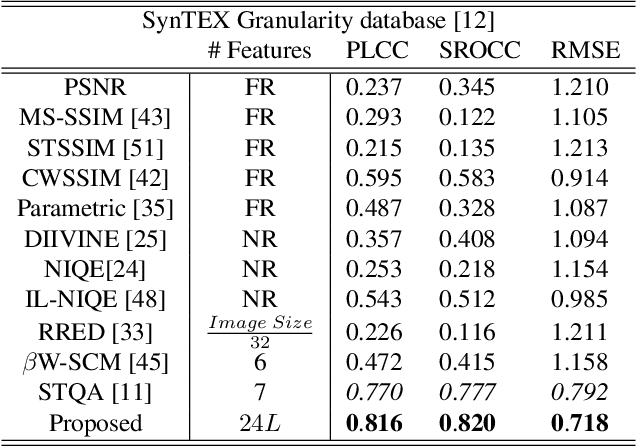

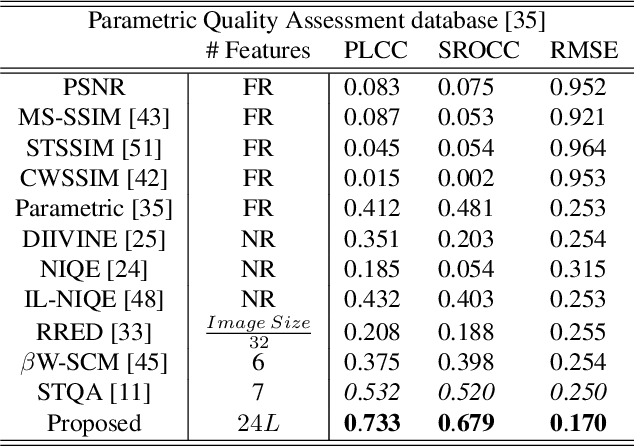
Perceptual quality assessment for synthesized textures is a challenging task. In this paper, we propose a training-free reduced-reference (RR) objective quality assessment method that quantifies the perceived quality of synthesized textures. The proposed reduced-reference synthesized texture quality assessment metric is based on measuring the spatial and statistical attributes of the texture image using both image- and gradient-based wavelet coefficients at multiple scales. Performance evaluations on two synthesized texture databases demonstrate that our proposed RR synthesized texture quality metric significantly outperforms both full-reference and RR state-of-the-art quality metrics in predicting the perceived visual quality of the synthesized textures.
Full Reference Objective Quality Assessment for Reconstructed Background Images
Apr 11, 2018

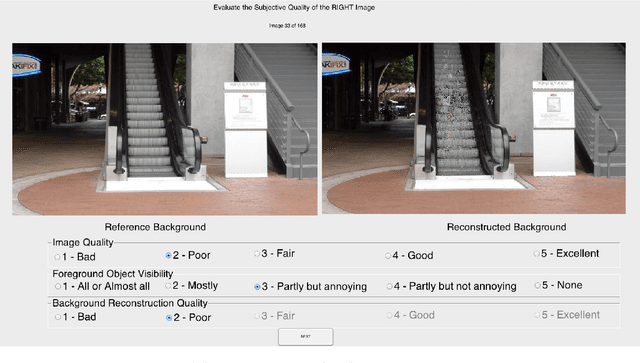

With an increased interest in applications that require a clean background image, such as video surveillance, object tracking, street view imaging and location-based services on web-based maps, multiple algorithms have been developed to reconstruct a background image from cluttered scenes. Traditionally, statistical measures and existing image quality techniques have been applied for evaluating the quality of the reconstructed background images. Though these quality assessment methods have been widely used in the past, their performance in evaluating the perceived quality of the reconstructed background image has not been verified. In this work, we discuss the shortcomings in existing metrics and propose a full reference Reconstructed Background image Quality Index (RBQI) that combines color and structural information at multiple scales using a probability summation model to predict the perceived quality in the reconstructed background image given a reference image. To compare the performance of the proposed quality index with existing image quality assessment measures, we construct two different datasets consisting of reconstructed background images and corresponding subjective scores. The quality assessment measures are evaluated by correlating their objective scores with human subjective ratings. The correlation results show that the proposed RBQI outperforms all the existing approaches. Additionally, the constructed datasets and the corresponding subjective scores provide a benchmark to evaluate the performance of future metrics that are developed to evaluate the perceived quality of reconstructed background images.
DeepCorrect: Correcting DNN models against Image Distortions
Jan 09, 2018



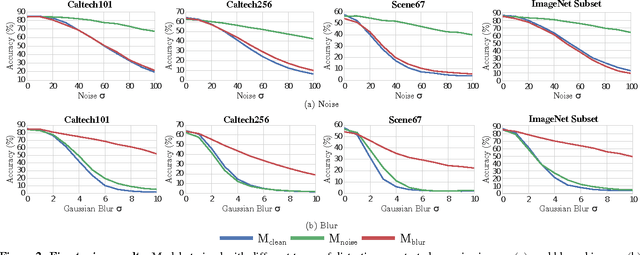
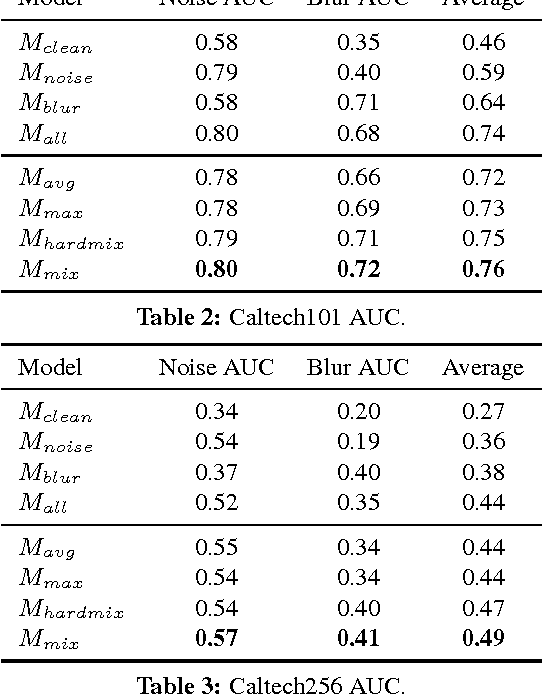
In recent years, the widespread use of deep neural networks (DNNs) has facilitated great improvements in performance for computer vision tasks like image classification and object recognition. In most realistic computer vision applications, an input image undergoes some form of image distortion such as blur and additive noise during image acquisition or transmission. Deep networks trained on pristine images perform poorly when tested on such distortions. In this paper, we evaluate the effect of image distortions like Gaussian blur and additive noise on the activations of pre-trained convolutional filters. We propose a metric to identify the most noise susceptible convolutional filters and rank them in order of the highest gain in classification accuracy upon correction. In our proposed approach called DeepCorrect, we apply small stacks of convolutional layers with residual connections, at the output of these ranked filters and train them to correct the worst distortion affected filter activations, whilst leaving the rest of the pre-trained filter outputs in the network unchanged. Performance results show that applying DeepCorrect models for common vision tasks like image classification (CIFAR-100, ImageNet), object recognition (Caltech-101, Caltech-256) and scene classification (SUN-397), significantly improves the robustness of DNNs against distorted images and outperforms the alternative approach of network fine-tuning.
Generative Sensing: Transforming Unreliable Sensor Data for Reliable Recognition
Jan 08, 2018

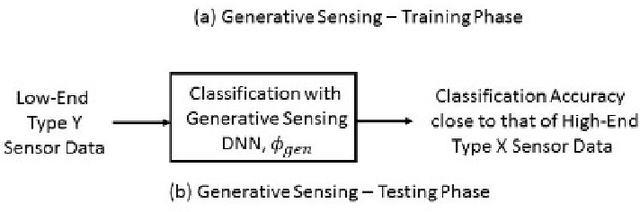

This paper introduces a deep learning enabled generative sensing framework which integrates low-end sensors with computational intelligence to attain a high recognition accuracy on par with that attained with high-end sensors. The proposed generative sensing framework aims at transforming low-end, low-quality sensor data into higher quality sensor data in terms of achieved classification accuracy. The low-end data can be transformed into higher quality data of the same modality or into data of another modality. Different from existing methods for image generation, the proposed framework is based on discriminative models and targets to maximize the recognition accuracy rather than a similarity measure. This is achieved through the introduction of selective feature regeneration in a deep neural network (DNN). The proposed generative sensing will essentially transform low-quality sensor data into high-quality information for robust perception. Results are presented to illustrate the performance of the proposed framework.
Can the early human visual system compete with Deep Neural Networks?
Oct 12, 2017
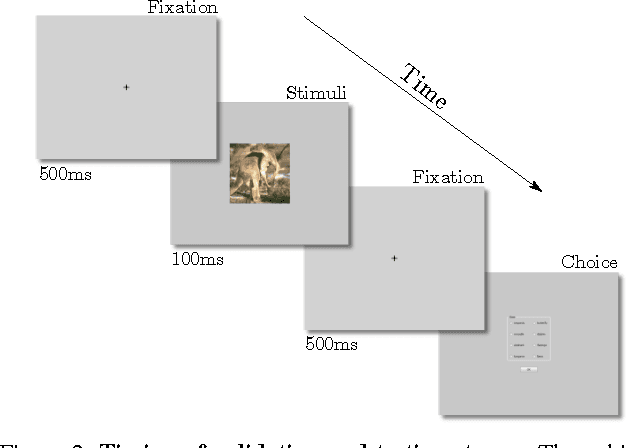

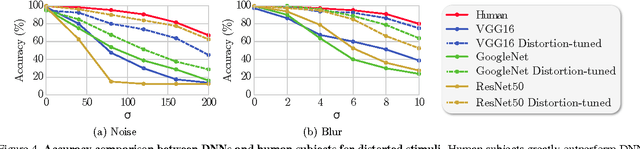
We study and compare the human visual system and state-of-the-art deep neural networks on classification of distorted images. Different from previous works, we limit the display time to 100ms to test only the early mechanisms of the human visual system, without allowing time for any eye movements or other higher level processes. Our findings show that the human visual system still outperforms modern deep neural networks under blurry and noisy images. These findings motivate future research into developing more robust deep networks.
A Study and Comparison of Human and Deep Learning Recognition Performance Under Visual Distortions
May 06, 2017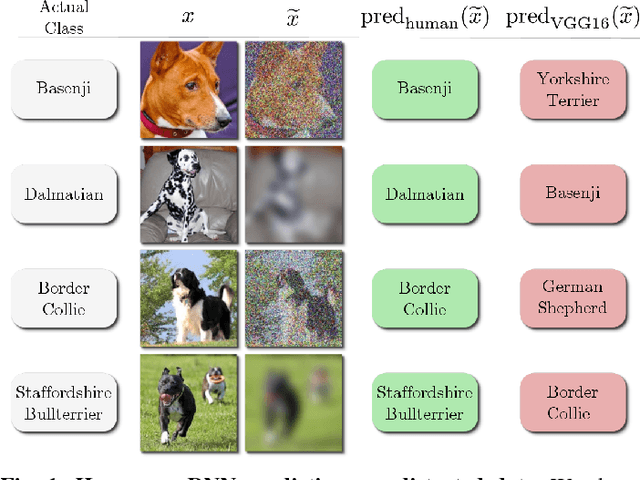


Deep neural networks (DNNs) achieve excellent performance on standard classification tasks. However, under image quality distortions such as blur and noise, classification accuracy becomes poor. In this work, we compare the performance of DNNs with human subjects on distorted images. We show that, although DNNs perform better than or on par with humans on good quality images, DNN performance is still much lower than human performance on distorted images. We additionally find that there is little correlation in errors between DNNs and human subjects. This could be an indication that the internal representation of images are different between DNNs and the human visual system. These comparisons with human performance could be used to guide future development of more robust DNNs.
Quality Resilient Deep Neural Networks
Mar 23, 2017
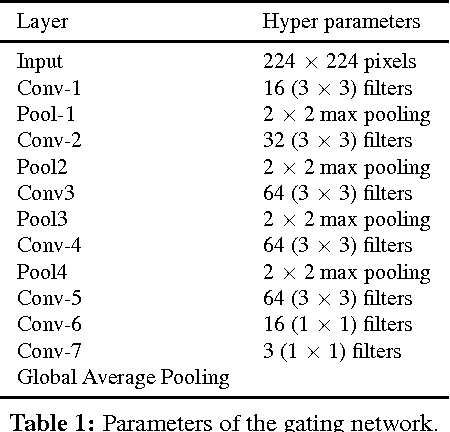
We study deep neural networks for classification of images with quality distortions. We first show that networks fine-tuned on distorted data greatly outperform the original networks when tested on distorted data. However, fine-tuned networks perform poorly on quality distortions that they have not been trained for. We propose a mixture of experts ensemble method that is robust to different types of distortions. The "experts" in our model are trained on a particular type of distortion. The output of the model is a weighted sum of the expert models, where the weights are determined by a separate gating network. The gating network is trained to predict optimal weights for a particular distortion type and level. During testing, the network is blind to the distortion level and type, yet can still assign appropriate weights to the expert models. We additionally investigate weight sharing methods for the mixture model and show that improved performance can be achieved with a large reduction in the number of unique network parameters.
Visual Saliency Prediction Using a Mixture of Deep Neural Networks
Feb 01, 2017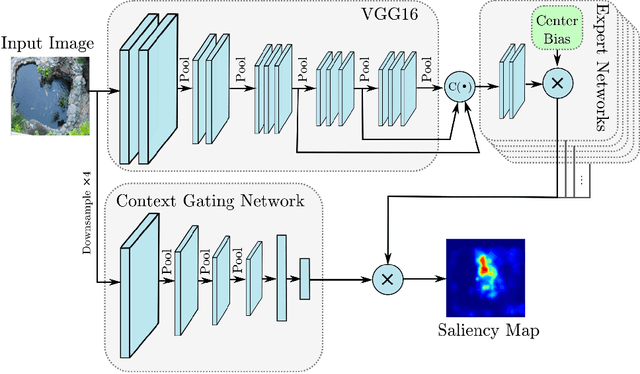
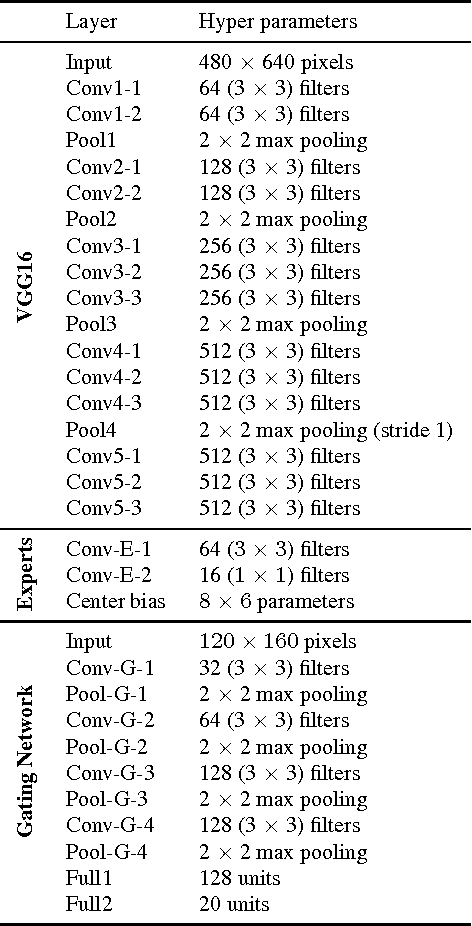

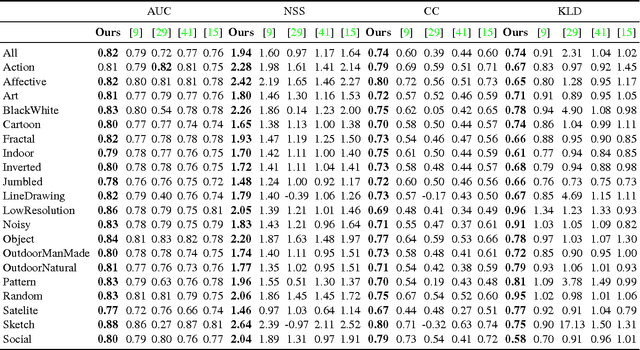
Visual saliency models have recently begun to incorporate deep learning to achieve predictive capacity much greater than previous unsupervised methods. However, most existing models predict saliency using local mechanisms limited to the receptive field of the network. We propose a model that incorporates global scene semantic information in addition to local information gathered by a convolutional neural network. Our model is formulated as a mixture of experts. Each expert network is trained to predict saliency for a set of closely related images. The final saliency map is computed as a weighted mixture of the expert networks' output, with weights determined by a separate gating network. This gating network is guided by global scene information to predict weights. The expert networks and the gating network are trained simultaneously in an end-to-end manner. We show that our mixture formulation leads to improvement in performance over an otherwise identical non-mixture model that does not incorporate global scene information.
Understanding How Image Quality Affects Deep Neural Networks
Apr 21, 2016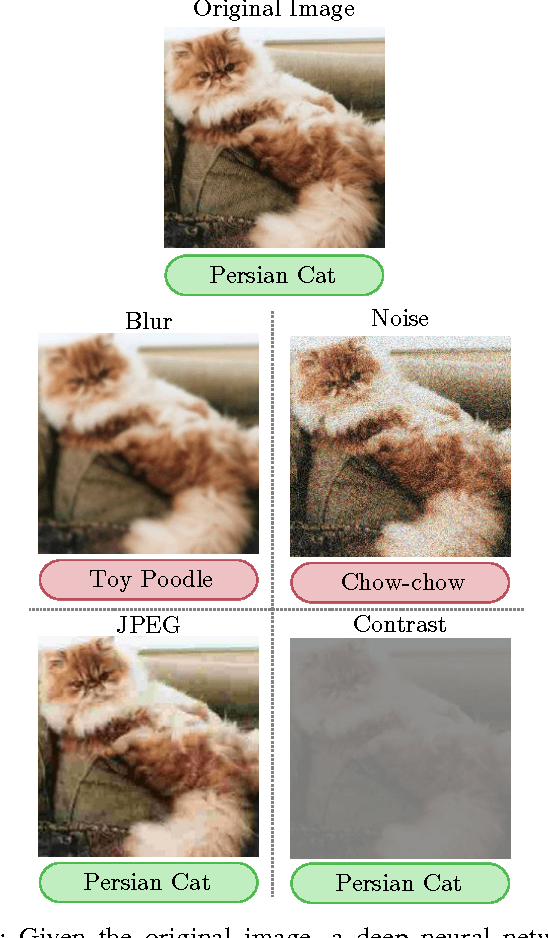
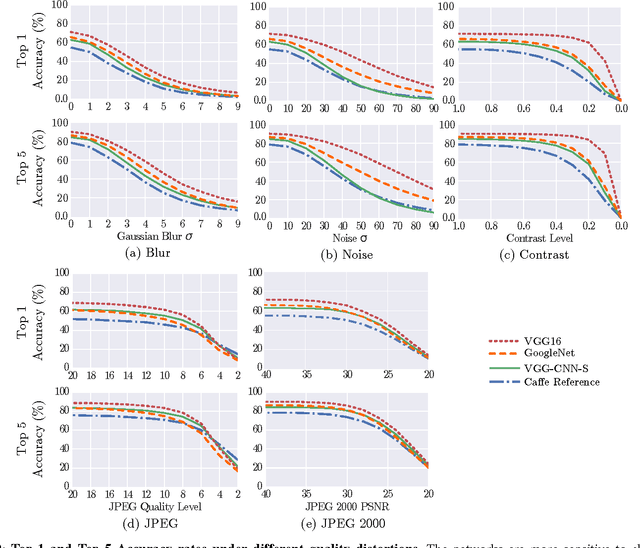

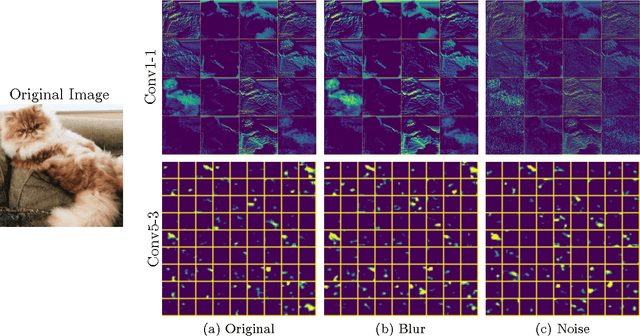
Image quality is an important practical challenge that is often overlooked in the design of machine vision systems. Commonly, machine vision systems are trained and tested on high quality image datasets, yet in practical applications the input images can not be assumed to be of high quality. Recently, deep neural networks have obtained state-of-the-art performance on many machine vision tasks. In this paper we provide an evaluation of 4 state-of-the-art deep neural network models for image classification under quality distortions. We consider five types of quality distortions: blur, noise, contrast, JPEG, and JPEG2000 compression. We show that the existing networks are susceptible to these quality distortions, particularly to blur and noise. These results enable future work in developing deep neural networks that are more invariant to quality distortions.