 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALF: Advertiser Large Foundation Model for Multi-Modal Advertiser Understanding
Apr 26, 2025



We present ALF (Advertiser Large Foundation model), a multi-modal transformer architecture for understanding advertiser behavior and intent across text, image, video and structured data modalities. Through contrastive learning and multi-task optimization, ALF creates unified advertiser representations that capture both content and behavioral patterns. Our model achieves state-of-the-art performance on critical tasks including fraud detection, policy violation identification, and advertiser similarity matching. In production deployment, ALF reduces false positives by 90% while maintaining 99.8% precision on abuse detection tasks. The architecture's effectiveness stems from its novel combination of multi-modal transformations, inter-sample attention mechanism, spectrally normalized projections, and calibrated probabilistic outputs.
Unified Fully and Timestamp Supervised Temporal Action Segmentation via Sequence to Sequence Translation
Sep 01, 2022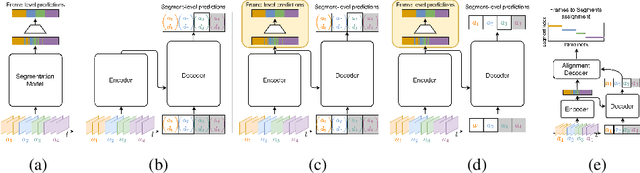
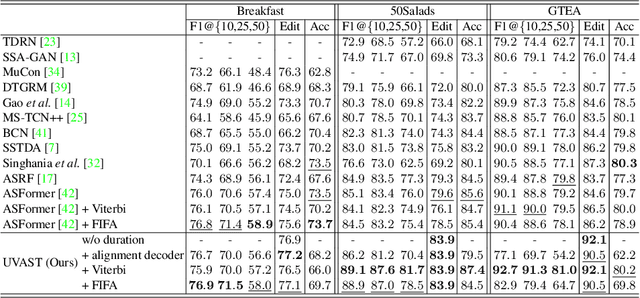
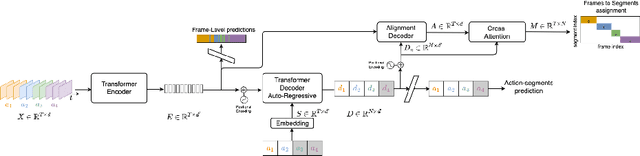
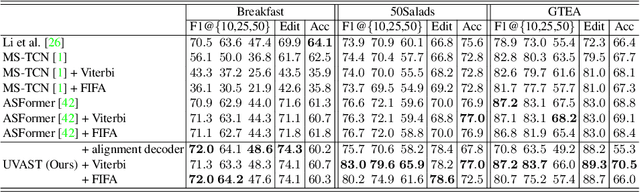
This paper introduces a unified framework for video action segmentation via sequence to sequence (seq2seq) translation in a fully and timestamp supervised setup. In contrast to current state-of-the-art frame-level prediction methods, we view action segmentation as a seq2seq translation task, i.e., mapping a sequence of video frames to a sequence of action segments. Our proposed method involves a series of modifications and auxiliary loss functions on the standard Transformer seq2seq translation model to cope with long input sequences opposed to short output sequences and relatively few videos. We incorporate an auxiliary supervision signal for the encoder via a frame-wise loss and propose a separate alignment decoder for an implicit duration prediction. Finally, we extend our framework to the timestamp supervised setting via our proposed constrained k-medoids algorithm to generate pseudo-segmentations. Our proposed framework performs consistently on both fully and timestamp supervised settings, outperforming or competing state-of-the-art on several datasets.
How to augment your ViTs? Consistency loss and StyleAug, a random style transfer augmentation
Dec 16, 2021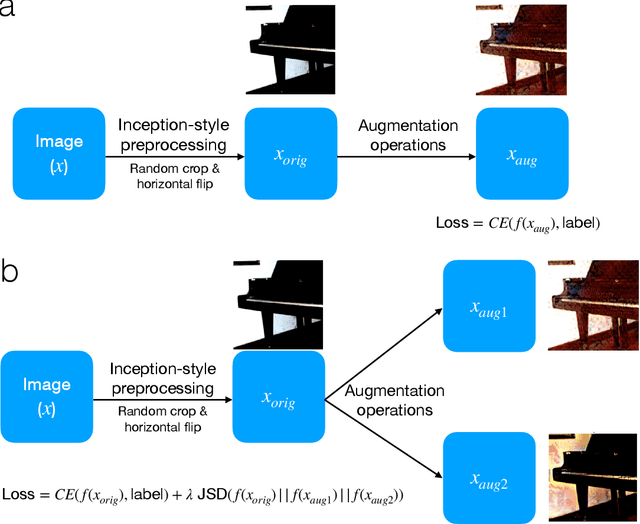



The Vision Transformer (ViT) architecture has recently achieved competitive performance across a variety of computer vision tasks. One of the motivations behind ViTs is weaker inductive biases, when compared to convolutional neural networks (CNNs). However this also makes ViTs more difficult to train. They require very large training datasets, heavy regularization, and strong data augmentations. The data augmentation strategies used to train ViTs have largely been inherited from CNN training, despite the significant differences between the two architectures. In this work, we empirical evaluated how different data augmentation strategies performed on CNN (e.g., ResNet) versus ViT architectures for image classification. We introduced a style transfer data augmentation, termed StyleAug, which worked best for training ViTs, while RandAugment and Augmix typically worked best for training CNNs. We also found that, in addition to a classification loss, using a consistency loss between multiple augmentations of the same image was especially helpful when training ViTs.
No-Reference Image Quality Assessment via Transformers, Relative Ranking, and Self-Consistency
Aug 16, 2021
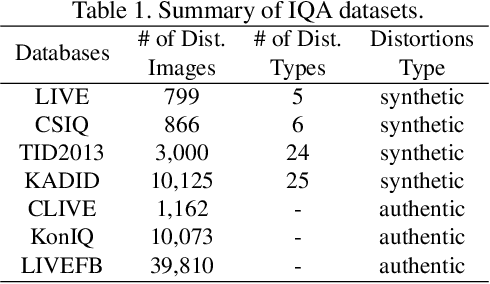
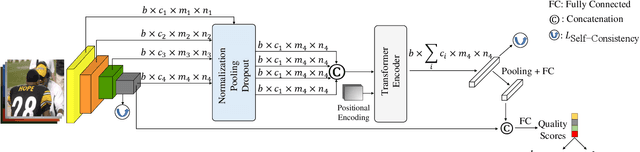
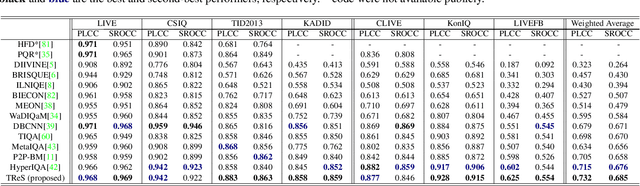
The goal of No-Reference Image Quality Assessment (NR-IQA) is to estimate the perceptual image quality in accordance with subjective evaluations, it is a complex and unsolved problem due to the absence of the pristine reference image. In this paper, we propose a novel model to address the NR-IQA task by leveraging a hybrid approach that benefits from Convolutional Neural Networks (CNNs) and self-attention mechanism in Transformers to extract both local and non-local features from the input image. We capture local structure information of the image via CNNs, then to circumvent the locality bias among the extracted CNNs features and obtain a non-local representation of the image, we utilize Transformers on the extracted features where we model them as a sequential input to the Transformer model. Furthermore, to improve the monotonicity correlation between the subjective and objective scores, we utilize the relative distance information among the images within each batch and enforce the relative ranking among them. Last but not least, we observe that the performance of NR-IQA models degrades when we apply equivariant transformations (e.g. horizontal flipping) to the inputs. Therefore, we propose a method that leverages self-consistency as a source of self-supervision to improve the robustness of NRIQA models. Specifically, we enforce self-consistency between the outputs of our quality assessment model for each image and its transformation (horizontally flipped) to utilize the rich self-supervisory information and reduce the uncertainty of the model. To demonstrate the effectiveness of our work, we evaluate it on seven standard IQA datasets (both synthetic and authentic) and show that our model achieves state-of-the-art results on various datasets.
3D Human Motion Estimation via Motion Compression and Refinement
Aug 09, 2020
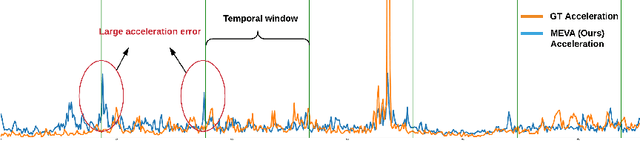
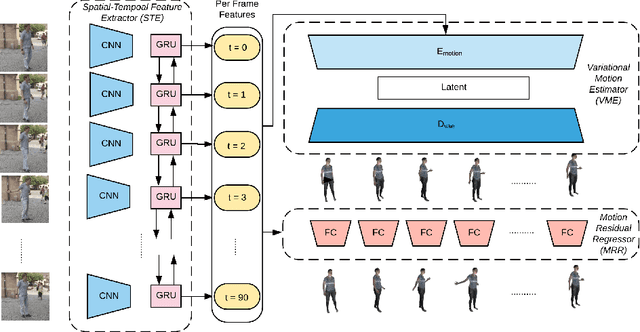
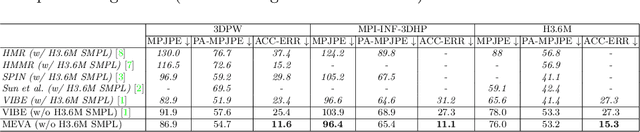
We develop a technique for generating smooth and accurate 3D human pose and motion estimates from RGB video sequences. Our technique, which we call Motion Estimation via Variational Autoencoder (MEVA), decomposes a temporal sequence of human motion into a smooth motion representation using auto-encoder-based motion compression and a residual representation learned through motion refinement. This two-step encoding of human motion captures human motion in two stages: a general human motions estimation step that captures the coarse overall motion, and a residual estimation that adds back person-specific motion details. Experiments show that our method produces both smooth and accurate 3D human pose and motion estimates.
Importance of Self-Consistency in Active Learning for Semantic Segmentation
Aug 04, 2020We address the task of active learning in the context of semantic segmentation and show that self-consistency can be a powerful source of self-supervision to greatly improve the performance of a data-driven model with access to only a small amount of labeled data. Self-consistency uses the simple observation that the results of semantic segmentation for a specific image should not change under transformations like horizontal flipping (i.e., the results should only be flipped). In other words, the output of a model should be consistent under equivariant transformations. The self-supervisory signal of self-consistency is particularly helpful during active learning since the model is prone to overfitting when there is only a small amount of labeled training data. In our proposed active learning framework, we iteratively extract small image patches that need to be labeled, by selecting image patches that have high uncertainty (high entropy) under equivariant transformations. We enforce pixel-wise self-consistency between the outputs of segmentation network for each image and its transformation (horizontally flipped) to utilize the rich self-supervisory information and reduce the uncertainty of the network. In this way, we are able to find the image patches over which the current model struggles the most to classify. By iteratively training over these difficult image patches, our experiments show that our active learning approach reaches $\sim96\%$ of the top performance of a model trained on all data, by using only $12\%$ of the total data on benchmark semantic segmentation datasets (e.g., CamVid and Cityscapes).
No-Reference Image Quality Assessment via Feature Fusion and Multi-Task Learning
Jun 06, 2020
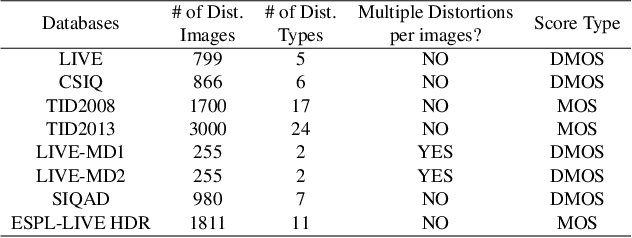
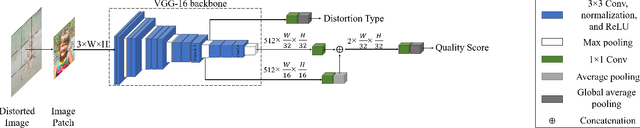
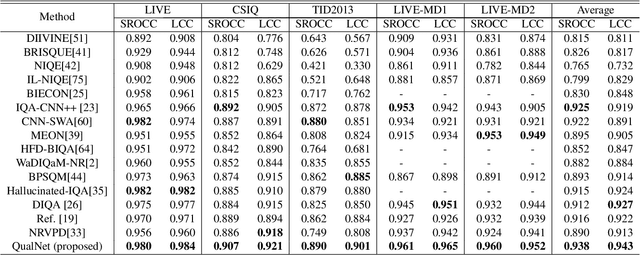
Blind or no-reference image quality assessment (NR-IQA) is a fundamental, unsolved, and yet challenging problem due to the unavailability of a reference image. It is vital to the streaming and social media industries that impact billions of viewers daily. Although previous NR-IQA methods leveraged different feature extraction approaches, the performance bottleneck still exists. In this paper, we propose a simple and yet effective general-purpose no-reference (NR) image quality assessment (IQA) framework based on multi-task learning. Our model employs distortion types as well as subjective human scores to predict image quality. We propose a feature fusion method to utilize distortion information to improve the quality score estimation task. In our experiments, we demonstrate that by utilizing multi-task learning and our proposed feature fusion method, our model yields better performance for the NR-IQA task. To demonstrate the effectiveness of our approach, we test our approach on seven standard datasets and show that we achieve state-of-the-art results on various datasets.
Synthesized Texture Quality Assessment via Multi-scale Spatial and Statistical Texture Attributes of Image and Gradient Magnitude Coefficients
Apr 26, 2018
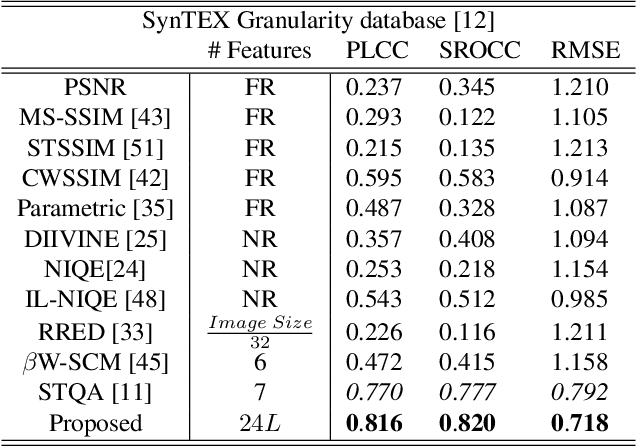

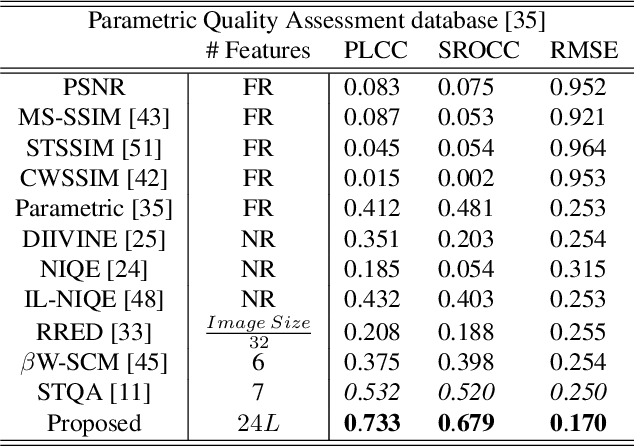
Perceptual quality assessment for synthesized textures is a challenging task. In this paper, we propose a training-free reduced-reference (RR) objective quality assessment method that quantifies the perceived quality of synthesized textures. The proposed reduced-reference synthesized texture quality assessment metric is based on measuring the spatial and statistical attributes of the texture image using both image- and gradient-based wavelet coefficients at multiple scales. Performance evaluations on two synthesized texture databases demonstrate that our proposed RR synthesized texture quality metric significantly outperforms both full-reference and RR state-of-the-art quality metrics in predicting the perceived visual quality of the synthesized textures.
Spatially-Varying Blur Detection Based on Multiscale Fused and Sorted Transform Coefficients of Gradient Magnitudes
Apr 11, 2017


The detection of spatially-varying blur without having any information about the blur type is a challenging task. In this paper, we propose a novel effective approach to address the blur detection problem from a single image without requiring any knowledge about the blur type, level, or camera settings. Our approach computes blur detection maps based on a novel High-frequency multiscale Fusion and Sort Transform (HiFST) of gradient magnitudes. The evaluations of the proposed approach on a diverse set of blurry images with different blur types, levels, and contents demonstrate that the proposed algorithm performs favorably against the state-of-the-art methods qualitatively and quantitatively.