 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to augment your ViTs? Consistency loss and StyleAug, a random style transfer augmentation
Dec 16, 2021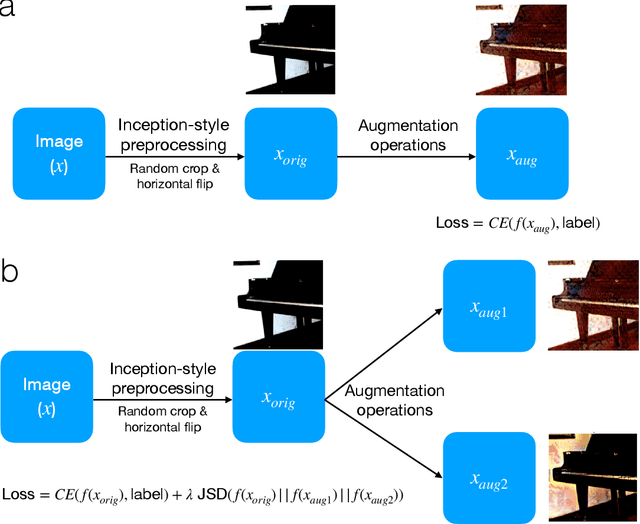



The Vision Transformer (ViT) architecture has recently achieved competitive performance across a variety of computer vision tasks. One of the motivations behind ViTs is weaker inductive biases, when compared to convolutional neural networks (CNNs). However this also makes ViTs more difficult to train. They require very large training datasets, heavy regularization, and strong data augmentations. The data augmentation strategies used to train ViTs have largely been inherited from CNN training, despite the significant differences between the two architectures. In this work, we empirical evaluated how different data augmentation strategies performed on CNN (e.g., ResNet) versus ViT architectures for image classification. We introduced a style transfer data augmentation, termed StyleAug, which worked best for training ViTs, while RandAugment and Augmix typically worked best for training CNNs. We also found that, in addition to a classification loss, using a consistency loss between multiple augmentations of the same image was especially helpful when training ViTs.
A Classifying Variational Autoencoder with Application to Polyphonic Music Generation
Nov 19, 2017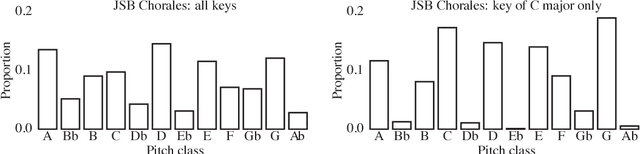
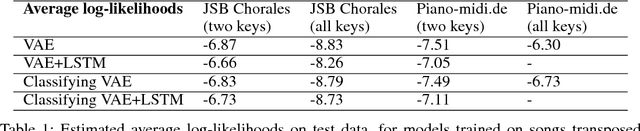
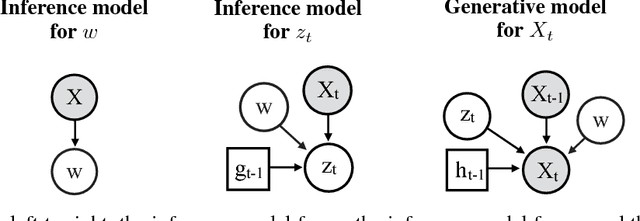
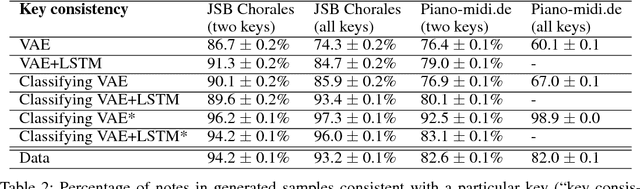
The variational autoencoder (VAE) is a popular probabilistic generative model. However, one shortcoming of VAEs is that the latent variables cannot be discrete, which makes it difficult to generate data from different modes of a distribution. Here, we propose an extension of the VAE framework that incorporates a classifier to infer the discrete class of the modeled data. To model sequential data, we can combine our Classifying VAE with a recurrent neural network such as an LSTM. We apply this model to algorithmic music generation, where our model learns to generate musical sequences in different keys. Most previous work in this area avoids modeling key by transposing data into only one or two keys, as opposed to the 10+ different keys in the original music. We show that our Classifying VAE and Classifying VAE+LSTM models outperform the corresponding non-classifying models in generating musical samples that stay in key. This benefit is especially apparent when trained on untransposed music data in the original keys.