 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference Optimal VLMs Need Only One Visual Token but Larger Models
Nov 05, 2024Vision Language Models (VLMs) have demonstrated strong capabilities across various visual understanding and reasoning tasks. However, their real-world deployment is often constrained by high latency during inference due to substantial compute required to process the large number of input tokens (predominantly from the image) by the LLM. To reduce inference costs, one can either downsize the LLM or reduce the number of input image-tokens, the latter of which has been the focus of many recent works around token compression. However, it is unclear what the optimal trade-off is, as both the factors directly affect the VLM performance. We first characterize this optimal trade-off between the number of visual tokens and LLM parameters by establishing scaling laws that capture variations in performance with these two factors. Our results reveal a surprising trend: for visual reasoning tasks, the inference-optimal behavior in VLMs, i.e., minimum downstream error at any given fixed inference compute, is achieved when using the largest LLM that fits within the inference budget while minimizing visual token count - often to a single token. While the token reduction literature has mainly focused on maintaining base model performance by modestly reducing the token count (e.g., $5-10\times$), our results indicate that the compute-optimal inference regime requires operating under even higher token compression ratios. Based on these insights, we take some initial steps towards building approaches tailored for high token compression settings. Code is available at https://github.com/locuslab/llava-token-compression.
Finetuning CLIP to Reason about Pairwise Differences
Sep 15, 2024

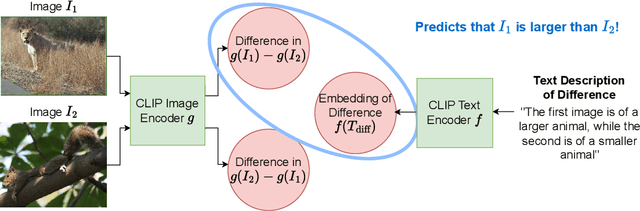

Vision-language models (VLMs) such as CLIP are trained via contrastive learning between text and image pairs, resulting in aligned image and text embeddings that are useful for many downstream tasks. A notable drawback of CLIP, however, is that the resulting embedding space seems to lack some of the structure of their purely text-based alternatives. For instance, while text embeddings have been long noted to satisfy \emph{analogies} in embedding space using vector arithmetic, CLIP has no such property. In this paper, we propose an approach to natively train CLIP in a contrastive manner to reason about differences in embedding space. We finetune CLIP so that the differences in image embedding space correspond to \emph{text descriptions of the image differences}, which we synthetically generate with large language models on image-caption paired datasets. We first demonstrate that our approach yields significantly improved capabilities in ranking images by a certain attribute (e.g., elephants are larger than cats), which is useful in retrieval or constructing attribute-based classifiers, and improved zeroshot classification performance on many downstream image classification tasks. In addition, our approach enables a new mechanism for inference that we refer to as comparative prompting, where we leverage prior knowledge of text descriptions of differences between classes of interest, achieving even larger performance gains in classification. Finally, we illustrate that the resulting embeddings obey a larger degree of geometric properties in embedding space, such as in text-to-image generation.
How to augment your ViTs? Consistency loss and StyleAug, a random style transfer augmentation
Dec 16, 2021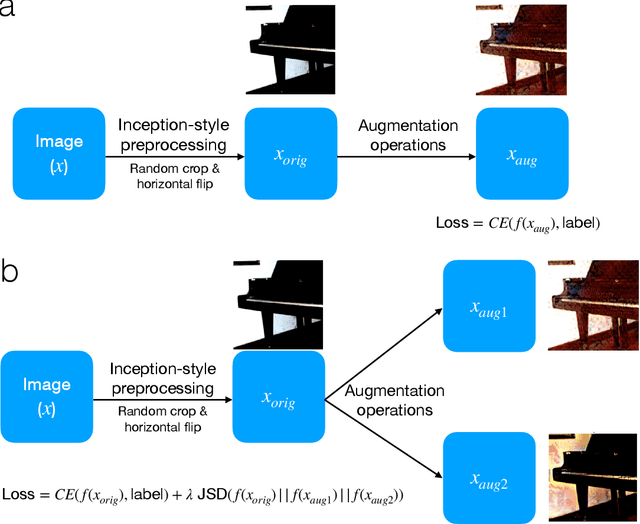



The Vision Transformer (ViT) architecture has recently achieved competitive performance across a variety of computer vision tasks. One of the motivations behind ViTs is weaker inductive biases, when compared to convolutional neural networks (CNNs). However this also makes ViTs more difficult to train. They require very large training datasets, heavy regularization, and strong data augmentations. The data augmentation strategies used to train ViTs have largely been inherited from CNN training, despite the significant differences between the two architectures. In this work, we empirical evaluated how different data augmentation strategies performed on CNN (e.g., ResNet) versus ViT architectures for image classification. We introduced a style transfer data augmentation, termed StyleAug, which worked best for training ViTs, while RandAugment and Augmix typically worked best for training CNNs. We also found that, in addition to a classification loss, using a consistency loss between multiple augmentations of the same image was especially helpful when training ViTs.