 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSharpness-Aware Pretraining Mitigates Catastrophic Forgetting
May 04, 2026Pretraining optimizers are tuned to produce the strongest possible base model, on the assumption that a stronger starting point yields a stronger model after subsequent changes like post-training and quantization. This overlooks the geometry of the base model which controls how much of the base model's capabilities survive subsequent parameter updates. We study three pretraining optimization approaches that bias optimization toward flatter minima: Sharpness-Aware Minimization (SAM), large learning rates, and shortened learning rate annealing periods. Across model sizes ranging from 20M to 150M parameters, we find that these interventions consistently improve downstream performance after post-training on five common datasets with up to 80% less forgetting. These principles hold at scale: a short SAM mid-training phase applied to an existing OLMo-2-1B checkpoint reduces forgetting by 31% after MetaMath post-training and by 40% after 4-bit quantization.
When Should We Introduce Safety Interventions During Pretraining?
Jan 11, 2026Ensuring the safety of language models in high-stakes settings remains a pressing challenge, as aligned behaviors are often brittle and easily undone by adversarial pressure or downstream finetuning. Prior work has shown that interventions applied during pretraining, such as rephrasing harmful content, can substantially improve the safety of the resulting models. In this paper, we study the fundamental question: "When during pretraining should safety interventions be introduced?" We keep the underlying data fixed and vary only the choice of a safety curriculum: the timing of these interventions, i.e., after 0%, 20%, or 60% of the pretraining token budget. We find that introducing interventions earlier generally yields more robust models with no increase in overrefusal rates, with the clearest benefits appearing after downstream, benign finetuning. We also see clear benefits in the steerability of models towards safer generations. Finally, we observe that earlier interventions reshape internal representations: linear probes more cleanly separate safe vs harmful examples. Overall, these results argue for incorporating safety signals early in pretraining, producing models that are more robust to downstream finetuning and jailbreaking, and more reliable under both standard and safety-aware inference procedures.
Safety Pretraining: Toward the Next Generation of Safe AI
Apr 23, 2025As large language models (LLMs) are increasingly deployed in high-stakes settings, the risk of generating harmful or toxic content remains a central challenge. Post-hoc alignment methods are brittle: once unsafe patterns are learned during pretraining, they are hard to remove. We present a data-centric pretraining framework that builds safety into the model from the start. Our contributions include: (i) a safety classifier trained on 10,000 GPT-4 labeled examples, used to filter 600B tokens; (ii) the largest synthetic safety dataset to date (100B tokens) generated via recontextualization of harmful web data; (iii) RefuseWeb and Moral Education datasets that convert harmful prompts into refusal dialogues and web-style educational material; (iv) Harmfulness-Tag annotations injected during pretraining to flag unsafe content and steer away inference from harmful generations; and (v) safety evaluations measuring base model behavior before instruction tuning. Our safety-pretrained models reduce attack success rates from 38.8% to 8.4% with no performance degradation on standard LLM safety benchmarks.
Overtrained Language Models Are Harder to Fine-Tune
Mar 24, 2025



Large language models are pre-trained on ever-growing token budgets under the assumption that better pre-training performance translates to improved downstream models. In this work, we challenge this assumption and show that extended pre-training can make models harder to fine-tune, leading to degraded final performance. We term this phenomenon catastrophic overtraining. For example, the instruction-tuned OLMo-1B model pre-trained on 3T tokens leads to over 2% worse performance on multiple standard LLM benchmarks than its 2.3T token counterpart. Through controlled experiments and theoretical analysis, we show that catastrophic overtraining arises from a systematic increase in the broad sensitivity of pre-trained parameters to modifications, including but not limited to fine-tuning. Our findings call for a critical reassessment of pre-training design that considers the downstream adaptability of the model.
Inference Optimal VLMs Need Only One Visual Token but Larger Models
Nov 05, 2024Vision Language Models (VLMs) have demonstrated strong capabilities across various visual understanding and reasoning tasks. However, their real-world deployment is often constrained by high latency during inference due to substantial compute required to process the large number of input tokens (predominantly from the image) by the LLM. To reduce inference costs, one can either downsize the LLM or reduce the number of input image-tokens, the latter of which has been the focus of many recent works around token compression. However, it is unclear what the optimal trade-off is, as both the factors directly affect the VLM performance. We first characterize this optimal trade-off between the number of visual tokens and LLM parameters by establishing scaling laws that capture variations in performance with these two factors. Our results reveal a surprising trend: for visual reasoning tasks, the inference-optimal behavior in VLMs, i.e., minimum downstream error at any given fixed inference compute, is achieved when using the largest LLM that fits within the inference budget while minimizing visual token count - often to a single token. While the token reduction literature has mainly focused on maintaining base model performance by modestly reducing the token count (e.g., $5-10\times$), our results indicate that the compute-optimal inference regime requires operating under even higher token compression ratios. Based on these insights, we take some initial steps towards building approaches tailored for high token compression settings. Code is available at https://github.com/locuslab/llava-token-compression.
Context-Parametric Inversion: Why Instruction Finetuning May Not Actually Improve Context Reliance
Oct 14, 2024



Large language models are instruction-finetuned to enhance their ability to follow user instructions and process the input context. However, even state-of-the-art models often struggle to follow the instruction, especially when the input context is not aligned with the model's parametric knowledge. This manifests as various failures, such as hallucinations where the responses are outdated, biased or contain unverified facts. In this work, we try to understand the underlying reason for this poor context reliance, especially after instruction tuning. We observe an intriguing phenomenon: during instruction tuning, the context reliance initially increases as expected, but then gradually decreases as instruction finetuning progresses. We call this phenomenon context-parametric inversion and observe it across multiple general purpose instruction tuning datasets like TULU, Alpaca and Ultrachat, as well as model families such as Llama, Mistral and Pythia. In a simple theoretical setup, we isolate why context-parametric inversion occurs along the gradient descent trajectory of instruction finetuning. We tie this phenomena to examples in the instruction finetuning data mixture where the input context provides information that is already present in the model's parametric knowledge. Our analysis suggests natural mitigation strategies that provide some limited gains, while also validating our theoretical insights. We hope that our work serves as a starting point in addressing this failure mode in a staple part of LLM training.
Scaling Laws for Data Filtering -- Data Curation cannot be Compute Agnostic
Apr 10, 2024Vision-language models (VLMs) are trained for thousands of GPU hours on carefully curated web datasets. In recent times, data curation has gained prominence with several works developing strategies to retain 'high-quality' subsets of 'raw' scraped data. For instance, the LAION public dataset retained only 10% of the total crawled data. However, these strategies are typically developed agnostic of the available compute for training. In this paper, we first demonstrate that making filtering decisions independent of training compute is often suboptimal: the limited high-quality data rapidly loses its utility when repeated, eventually requiring the inclusion of 'unseen' but 'lower-quality' data. To address this quality-quantity tradeoff ($\texttt{QQT}$), we introduce neural scaling laws that account for the non-homogeneous nature of web data, an angle ignored in existing literature. Our scaling laws (i) characterize the $\textit{differing}$ 'utility' of various quality subsets of web data; (ii) account for how utility diminishes for a data point at its 'nth' repetition; and (iii) formulate the mutual interaction of various data pools when combined, enabling the estimation of model performance on a combination of multiple data pools without ever jointly training on them. Our key message is that data curation $\textit{cannot}$ be agnostic of the total compute that a model will be trained for. Our scaling laws allow us to curate the best possible pool for achieving top performance on Datacomp at various compute budgets, carving out a pareto-frontier for data curation. Code is available at https://github.com/locuslab/scaling_laws_data_filtering.
Think before you speak: Training Language Models With Pause Tokens
Oct 03, 2023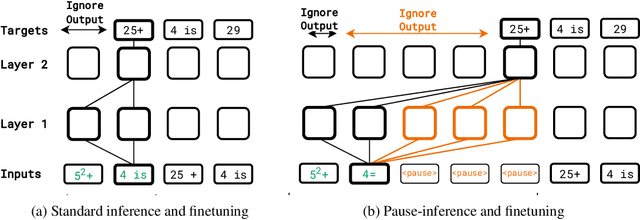

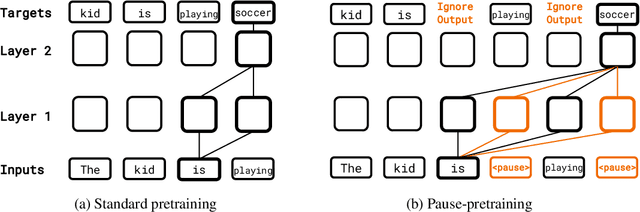

Language models generate responses by producing a series of tokens in immediate succession: the $(K+1)^{th}$ token is an outcome of manipulating $K$ hidden vectors per layer, one vector per preceding token. What if instead we were to let the model manipulate say, $K+10$ hidden vectors, before it outputs the $(K+1)^{th}$ token? We operationalize this idea by performing training and inference on language models with a (learnable) $\textit{pause}$ token, a sequence of which is appended to the input prefix. We then delay extracting the model's outputs until the last pause token is seen, thereby allowing the model to process extra computation before committing to an answer. We empirically evaluate $\textit{pause-training}$ on decoder-only models of 1B and 130M parameters with causal pretraining on C4, and on downstream tasks covering reasoning, question-answering, general understanding and fact recall. Our main finding is that inference-time delays show gains when the model is both pre-trained and finetuned with delays. For the 1B model, we witness gains on 8 of 9 tasks, most prominently, a gain of $18\%$ EM score on the QA task of SQuAD, $8\%$ on CommonSenseQA and $1\%$ accuracy on the reasoning task of GSM8k. Our work raises a range of conceptual and practical future research questions on making delayed next-token prediction a widely applicable new paradigm.
T-MARS: Improving Visual Representations by Circumventing Text Feature Learning
Jul 06, 2023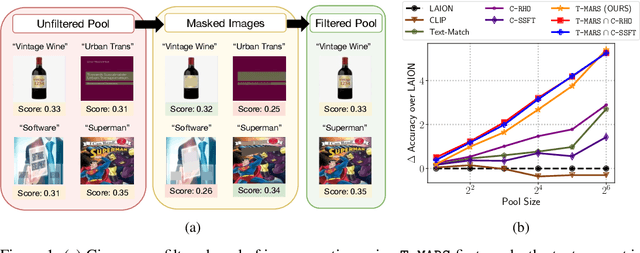
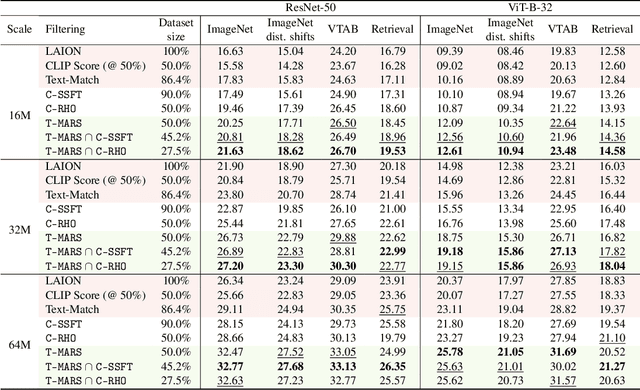

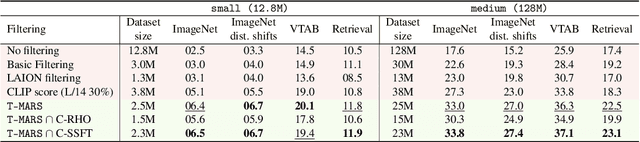
Large web-sourced multimodal datasets have powered a slew of new methods for learning general-purpose visual representations, advancing the state of the art in computer vision and revolutionizing zero- and few-shot recognition. One crucial decision facing practitioners is how, if at all, to curate these ever-larger datasets. For example, the creators of the LAION-5B dataset chose to retain only image-caption pairs whose CLIP similarity score exceeded a designated threshold. In this paper, we propose a new state-of-the-art data filtering approach motivated by our observation that nearly 40% of LAION's images contain text that overlaps significantly with the caption. Intuitively, such data could be wasteful as it incentivizes models to perform optical character recognition rather than learning visual features. However, naively removing all such data could also be wasteful, as it throws away images that contain visual features (in addition to overlapping text). Our simple and scalable approach, T-MARS (Text Masking and Re-Scoring), filters out only those pairs where the text dominates the remaining visual features -- by first masking out the text and then filtering out those with a low CLIP similarity score of the masked image. Experimentally, T-MARS outperforms the top-ranked method on the "medium scale" of DataComp (a data filtering benchmark) by a margin of 6.5% on ImageNet and 4.7% on VTAB. Additionally, our systematic evaluation on various data pool sizes from 2M to 64M shows that the accuracy gains enjoyed by T-MARS linearly increase as data and compute are scaled exponentially. Code is available at https://github.com/locuslab/T-MARS.
Finetune like you pretrain: Improved finetuning of zero-shot vision models
Dec 01, 2022


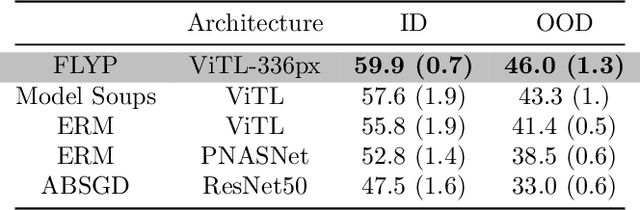
Finetuning image-text models such as CLIP achieves state-of-the-art accuracies on a variety of benchmarks. However, recent works like WiseFT (Wortsman et al., 2021) and LP-FT (Kumar et al., 2022) have shown that even subtle differences in the finetuning process can lead to surprisingly large differences in the final performance, both for in-distribution (ID) and out-of-distribution (OOD) data. In this work, we show that a natural and simple approach of mimicking contrastive pretraining consistently outperforms alternative finetuning approaches. Specifically, we cast downstream class labels as text prompts and continue optimizing the contrastive loss between image embeddings and class-descriptive prompt embeddings (contrastive finetuning). Our method consistently outperforms baselines across 7 distribution shifts, 6 transfer learning, and 3 few-shot learning benchmarks. On WILDS-iWILDCam, our proposed approach FLYP outperforms the top of the leaderboard by $2.3\%$ ID and $2.7\%$ OOD, giving the highest reported accuracy. Averaged across 7 OOD datasets (2 WILDS and 5 ImageNet associated shifts), FLYP gives gains of $4.2\%$ OOD over standard finetuning and outperforms the current state of the art (LP-FT) by more than $1\%$ both ID and OOD. Similarly, on 3 few-shot learning benchmarks, our approach gives gains up to $4.6\%$ over standard finetuning and $4.4\%$ over the state of the art. In total, these benchmarks establish contrastive finetuning as a simple, intuitive, and state-of-the-art approach for supervised finetuning of image-text models like CLIP. Code is available at https://github.com/locuslab/FLYP.