 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT-MARS: Improving Visual Representations by Circumventing Text Feature Learning
Paper and Code
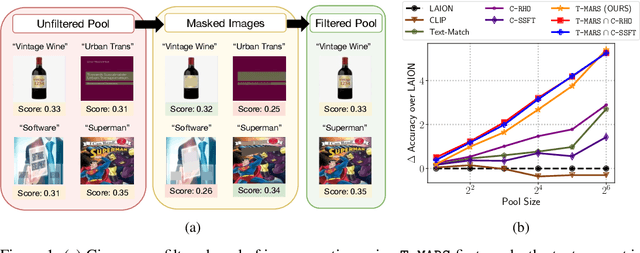
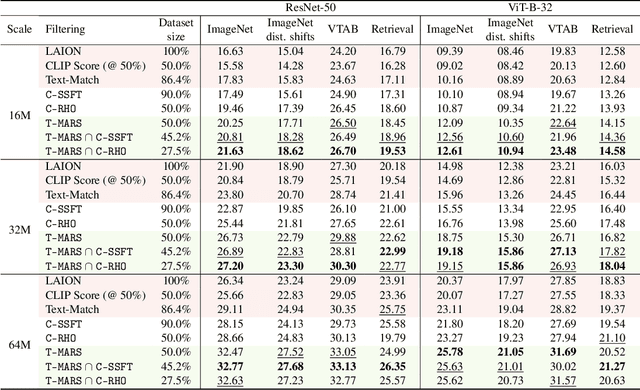

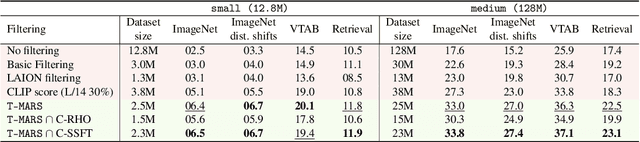
Large web-sourced multimodal datasets have powered a slew of new methods for learning general-purpose visual representations, advancing the state of the art in computer vision and revolutionizing zero- and few-shot recognition. One crucial decision facing practitioners is how, if at all, to curate these ever-larger datasets. For example, the creators of the LAION-5B dataset chose to retain only image-caption pairs whose CLIP similarity score exceeded a designated threshold. In this paper, we propose a new state-of-the-art data filtering approach motivated by our observation that nearly 40% of LAION's images contain text that overlaps significantly with the caption. Intuitively, such data could be wasteful as it incentivizes models to perform optical character recognition rather than learning visual features. However, naively removing all such data could also be wasteful, as it throws away images that contain visual features (in addition to overlapping text). Our simple and scalable approach, T-MARS (Text Masking and Re-Scoring), filters out only those pairs where the text dominates the remaining visual features -- by first masking out the text and then filtering out those with a low CLIP similarity score of the masked image. Experimentally, T-MARS outperforms the top-ranked method on the "medium scale" of DataComp (a data filtering benchmark) by a margin of 6.5% on ImageNet and 4.7% on VTAB. Additionally, our systematic evaluation on various data pool sizes from 2M to 64M shows that the accuracy gains enjoyed by T-MARS linearly increase as data and compute are scaled exponentially. Code is available at https://github.com/locuslab/T-MARS.