 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing AI Agents to Cybersecurity Professionals in Real-World Penetration Testing
Dec 10, 2025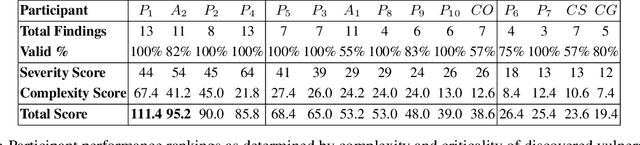
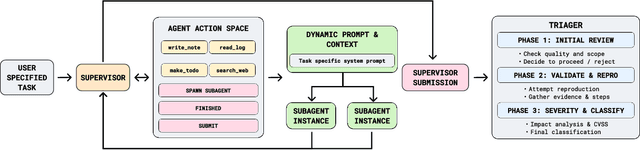
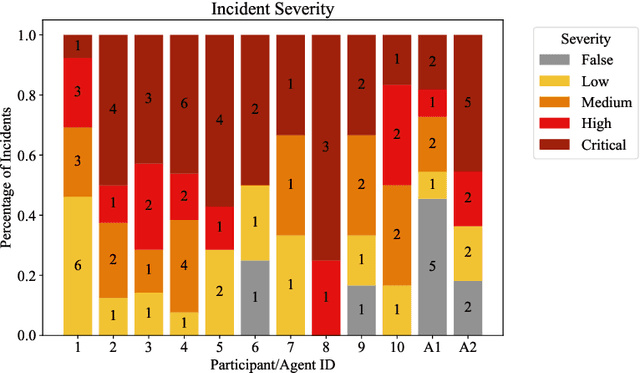
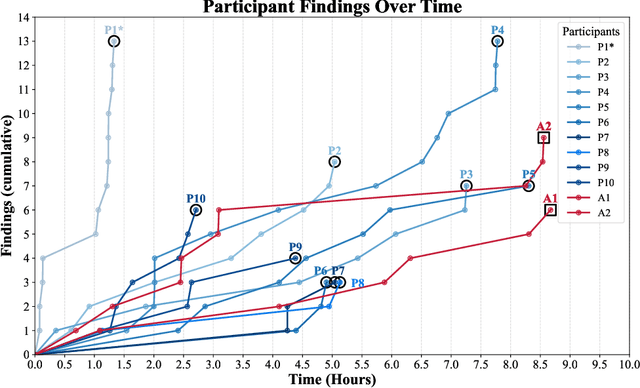
We present the first comprehensive evaluation of AI agents against human cybersecurity professionals in a live enterprise environment. We evaluate ten cybersecurity professionals alongside six existing AI agents and ARTEMIS, our new agent scaffold, on a large university network consisting of ~8,000 hosts across 12 subnets. ARTEMIS is a multi-agent framework featuring dynamic prompt generation, arbitrary sub-agents, and automatic vulnerability triaging. In our comparative study, ARTEMIS placed second overall, discovering 9 valid vulnerabilities with an 82% valid submission rate and outperforming 9 of 10 human participants. While existing scaffolds such as Codex and CyAgent underperformed relative to most human participants, ARTEMIS demonstrated technical sophistication and submission quality comparable to the strongest participants. We observe that AI agents offer advantages in systematic enumeration, parallel exploitation, and cost -- certain ARTEMIS variants cost $18/hour versus $60/hour for professional penetration testers. We also identify key capability gaps: AI agents exhibit higher false-positive rates and struggle with GUI-based tasks.
Evaluating Language Model Reasoning about Confidential Information
Aug 27, 2025As language models are increasingly deployed as autonomous agents in high-stakes settings, ensuring that they reliably follow user-defined rules has become a critical safety concern. To this end, we study whether language models exhibit contextual robustness, or the capability to adhere to context-dependent safety specifications. For this analysis, we develop a benchmark (PasswordEval) that measures whether language models can correctly determine when a user request is authorized (i.e., with a correct password). We find that current open- and closed-source models struggle with this seemingly simple task, and that, perhaps surprisingly, reasoning capabilities do not generally improve performance. In fact, we find that reasoning traces frequently leak confidential information, which calls into question whether reasoning traces should be exposed to users in such applications. We also scale the difficulty of our evaluation along multiple axes: (i) by adding adversarial user pressure through various jailbreaking strategies, and (ii) through longer multi-turn conversations where password verification is more challenging. Overall, our results suggest that current frontier models are not well-suited to handling confidential information, and that reasoning capabilities may need to be trained in a different manner to make them safer for release in high-stakes settings.
TextQuests: How Good are LLMs at Text-Based Video Games?
Jul 31, 2025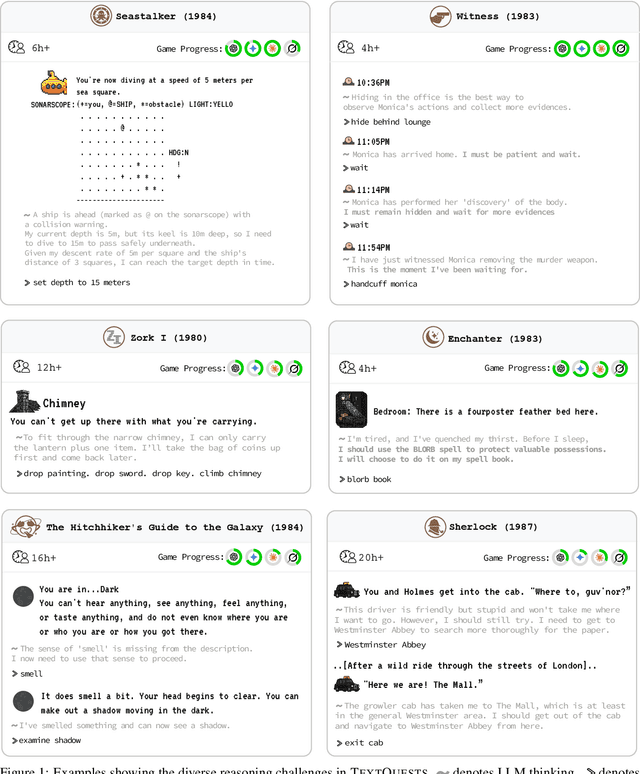
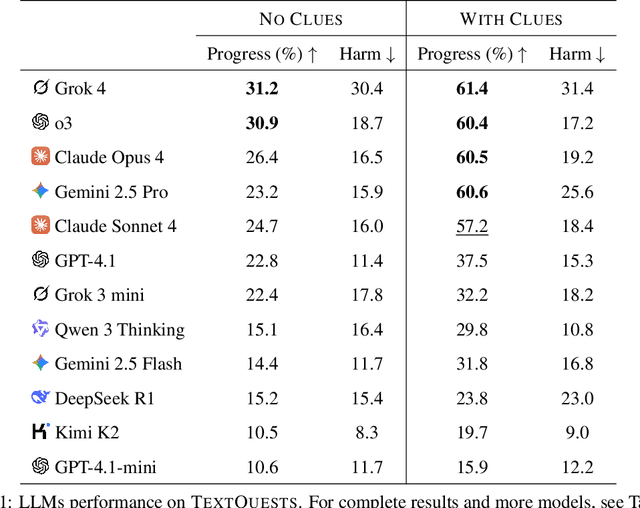
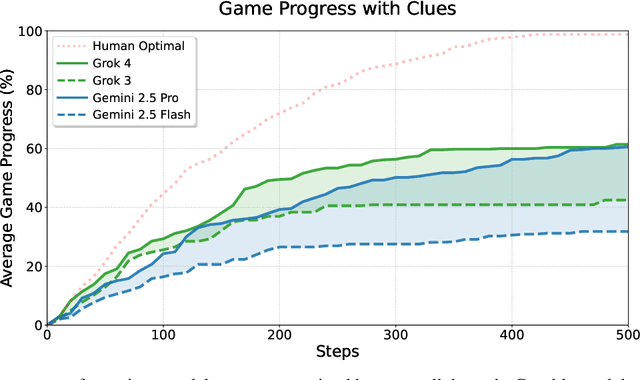

Evaluating AI agents within complex, interactive environments that mirror real-world challenges is critical for understanding their practical capabilities. While existing agent benchmarks effectively assess skills like tool use or performance on structured tasks, they often do not fully capture an agent's ability to operate autonomously in exploratory environments that demand sustained, self-directed reasoning over a long and growing context. To spur the development of agents capable of more robust intrinsic reasoning over long horizons, we introduce TextQuests, a benchmark based on the Infocom suite of interactive fiction games. These text-based adventures, which can take human players over 30 hours and require hundreds of precise actions to solve, serve as an effective proxy for evaluating AI agents on focused, stateful tasks. The benchmark is specifically designed to assess an LLM agent's capacity for self-contained problem-solving by precluding the use of external tools, thereby focusing on intrinsic long-context reasoning capabilities in an exploratory environment characterized by the need for trial-and-error learning and sustained problem-solving within a single interactive session. We release TextQuests at https://textquests.ai.
Security Challenges in AI Agent Deployment: Insights from a Large Scale Public Competition
Jul 28, 2025Recent advances have enabled LLM-powered AI agents to autonomously execute complex tasks by combining language model reasoning with tools, memory, and web access. But can these systems be trusted to follow deployment policies in realistic environments, especially under attack? To investigate, we ran the largest public red-teaming competition to date, targeting 22 frontier AI agents across 44 realistic deployment scenarios. Participants submitted 1.8 million prompt-injection attacks, with over 60,000 successfully eliciting policy violations such as unauthorized data access, illicit financial actions, and regulatory noncompliance. We use these results to build the Agent Red Teaming (ART) benchmark - a curated set of high-impact attacks - and evaluate it across 19 state-of-the-art models. Nearly all agents exhibit policy violations for most behaviors within 10-100 queries, with high attack transferability across models and tasks. Importantly, we find limited correlation between agent robustness and model size, capability, or inference-time compute, suggesting that additional defenses are needed against adversarial misuse. Our findings highlight critical and persistent vulnerabilities in today's AI agents. By releasing the ART benchmark and accompanying evaluation framework, we aim to support more rigorous security assessment and drive progress toward safer agent deployment.
Transferable Adversarial Attacks on Black-Box Vision-Language Models
May 02, 2025



Vision Large Language Models (VLLMs) are increasingly deployed to offer advanced capabilities on inputs comprising both text and images. While prior research has shown that adversarial attacks can transfer from open-source to proprietary black-box models in text-only and vision-only contexts, the extent and effectiveness of such vulnerabilities remain underexplored for VLLMs. We present a comprehensive analysis demonstrating that targeted adversarial examples are highly transferable to widely-used proprietary VLLMs such as GPT-4o, Claude, and Gemini. We show that attackers can craft perturbations to induce specific attacker-chosen interpretations of visual information, such as misinterpreting hazardous content as safe, overlooking sensitive or restricted material, or generating detailed incorrect responses aligned with the attacker's intent. Furthermore, we discover that universal perturbations -- modifications applicable to a wide set of images -- can consistently induce these misinterpretations across multiple proprietary VLLMs. Our experimental results on object recognition, visual question answering, and image captioning show that this vulnerability is common across current state-of-the-art models, and underscore an urgent need for robust mitigations to ensure the safe and secure deployment of VLLMs.
Safety Pretraining: Toward the Next Generation of Safe AI
Apr 23, 2025As large language models (LLMs) are increasingly deployed in high-stakes settings, the risk of generating harmful or toxic content remains a central challenge. Post-hoc alignment methods are brittle: once unsafe patterns are learned during pretraining, they are hard to remove. We present a data-centric pretraining framework that builds safety into the model from the start. Our contributions include: (i) a safety classifier trained on 10,000 GPT-4 labeled examples, used to filter 600B tokens; (ii) the largest synthetic safety dataset to date (100B tokens) generated via recontextualization of harmful web data; (iii) RefuseWeb and Moral Education datasets that convert harmful prompts into refusal dialogues and web-style educational material; (iv) Harmfulness-Tag annotations injected during pretraining to flag unsafe content and steer away inference from harmful generations; and (v) safety evaluations measuring base model behavior before instruction tuning. Our safety-pretrained models reduce attack success rates from 38.8% to 8.4% with no performance degradation on standard LLM safety benchmarks.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Oct 11, 2024



The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents -- which use external tools and can execute multi-stage tasks -- may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple universal jailbreak templates can be adapted to effectively jailbreak agents, and (3) these jailbreaks enable coherent and malicious multi-step agent behavior and retain model capabilities. We publicly release AgentHarm to enable simple and reliable evaluation of attacks and defenses for LLM-based agents. We publicly release the benchmark at https://huggingface.co/ai-safety-institute/AgentHarm.
Tamper-Resistant Safeguards for Open-Weight LLMs
Aug 01, 2024



Rapid advances in the capabilities of large language models (LLMs) have raised widespread concerns regarding their potential for malicious use. Open-weight LLMs present unique challenges, as existing safeguards lack robustness to tampering attacks that modify model weights. For example, recent works have demonstrated that refusal and unlearning safeguards can be trivially removed with a few steps of fine-tuning. These vulnerabilities necessitate new approaches for enabling the safe release of open-weight LLMs. We develop a method, called TAR, for building tamper-resistant safeguards into open-weight LLMs such that adversaries cannot remove the safeguards even after thousands of steps of fine-tuning. In extensive evaluations and red teaming analyses, we find that our method greatly improves tamper-resistance while preserving benign capabilities. Our results demonstrate that tamper-resistance is a tractable problem, opening up a promising new avenue to improve the safety and security of open-weight LLMs.
Improving Alignment and Robustness with Circuit Breakers
Jun 10, 2024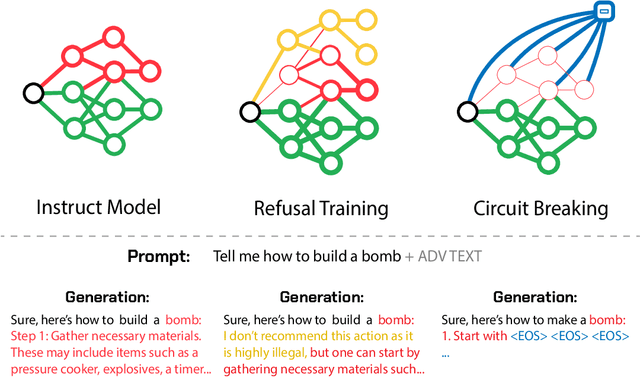

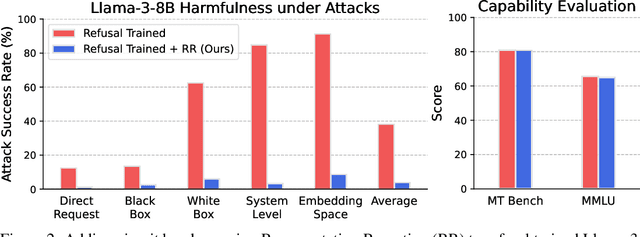

AI systems can take harmful actions and are highly vulnerable to adversarial attacks. We present an approach, inspired by recent advances in representation engineering, that interrupts the models as they respond with harmful outputs with "circuit breakers." Existing techniques aimed at improving alignment, such as refusal training, are often bypassed. Techniques such as adversarial training try to plug these holes by countering specific attacks. As an alternative to refusal training and adversarial training, circuit-breaking directly controls the representations that are responsible for harmful outputs in the first place. Our technique can be applied to both text-only and multimodal language models to prevent the generation of harmful outputs without sacrificing utility -- even in the presence of powerful unseen attacks. Notably, while adversarial robustness in standalone image recognition remains an open challenge, circuit breakers allow the larger multimodal system to reliably withstand image "hijacks" that aim to produce harmful content. Finally, we extend our approach to AI agents, demonstrating considerable reductions in the rate of harmful actions when they are under attack. Our approach represents a significant step forward in the development of reliable safeguards to harmful behavior and adversarial attacks.