 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecurity Challenges in AI Agent Deployment: Insights from a Large Scale Public Competition
Jul 28, 2025Recent advances have enabled LLM-powered AI agents to autonomously execute complex tasks by combining language model reasoning with tools, memory, and web access. But can these systems be trusted to follow deployment policies in realistic environments, especially under attack? To investigate, we ran the largest public red-teaming competition to date, targeting 22 frontier AI agents across 44 realistic deployment scenarios. Participants submitted 1.8 million prompt-injection attacks, with over 60,000 successfully eliciting policy violations such as unauthorized data access, illicit financial actions, and regulatory noncompliance. We use these results to build the Agent Red Teaming (ART) benchmark - a curated set of high-impact attacks - and evaluate it across 19 state-of-the-art models. Nearly all agents exhibit policy violations for most behaviors within 10-100 queries, with high attack transferability across models and tasks. Importantly, we find limited correlation between agent robustness and model size, capability, or inference-time compute, suggesting that additional defenses are needed against adversarial misuse. Our findings highlight critical and persistent vulnerabilities in today's AI agents. By releasing the ART benchmark and accompanying evaluation framework, we aim to support more rigorous security assessment and drive progress toward safer agent deployment.
Oogway: Designing, Implementing, and Testing an AUV for RoboSub 2023
Oct 13, 2024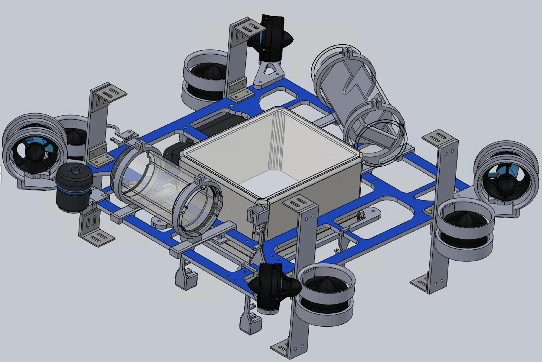


The Duke Robotics Club is proud to present our robot for the 2023 RoboSub Competition: Oogway. Oogway marks one of the largest design overhauls in club history. Beyond a revamped formfactor, some of Oogway's notable features include all-new computer vision software, advanced sonar integration, novel acoustics hardware processing, and upgraded stereoscopic cameras. Oogway was built on the principle of independent, well-integrated, and reliable subsystems. Individual components and subsystems were tested and designed separately. Oogway's most advanced capabilities are a result of the tight integration between these subsystems. Such examples include sonar-assisted computer vision algorithms and robot-agnostic controls configured in part through the robot's 3D model. The success of constructing and testing Oogway in under 2 year's time can be attributed to 20+ contributing club members, supporters within Duke's Pratt School of Engineering, and outside sponsors.
Technical Design Review of Duke Robotics Club's Oogway: An AUV for RoboSub 2024
Oct 13, 2024



The Duke Robotics Club is proud to present our robot for the 2024 RoboSub Competition: Oogway. Now in its second year, Oogway has been dramatically upgraded in both its capabilities and reliability. Oogway was built on the principle of independent, well-integrated, and reliable subsystems. Individual components and subsystems were tested and designed separately. Oogway's most advanced capabilities are a result of the tight integration between these subsystems. Such examples include a re-envisioned controls system, an entirely new electrical stack, advanced sonar integration, additional cameras and system monitoring, a new marker dropper, and a watertight capsule mechanism. These additions enabled Oogway to prequalify for Robosub 2024.
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Oct 11, 2024



The robustness of LLMs to jailbreak attacks, where users design prompts to circumvent safety measures and misuse model capabilities, has been studied primarily for LLMs acting as simple chatbots. Meanwhile, LLM agents -- which use external tools and can execute multi-stage tasks -- may pose a greater risk if misused, but their robustness remains underexplored. To facilitate research on LLM agent misuse, we propose a new benchmark called AgentHarm. The benchmark includes a diverse set of 110 explicitly malicious agent tasks (440 with augmentations), covering 11 harm categories including fraud, cybercrime, and harassment. In addition to measuring whether models refuse harmful agentic requests, scoring well on AgentHarm requires jailbroken agents to maintain their capabilities following an attack to complete a multi-step task. We evaluate a range of leading LLMs, and find (1) leading LLMs are surprisingly compliant with malicious agent requests without jailbreaking, (2) simple universal jailbreak templates can be adapted to effectively jailbreak agents, and (3) these jailbreaks enable coherent and malicious multi-step agent behavior and retain model capabilities. We publicly release AgentHarm to enable simple and reliable evaluation of attacks and defenses for LLM-based agents. We publicly release the benchmark at https://huggingface.co/ai-safety-institute/AgentHarm.
Tamper-Resistant Safeguards for Open-Weight LLMs
Aug 01, 2024



Rapid advances in the capabilities of large language models (LLMs) have raised widespread concerns regarding their potential for malicious use. Open-weight LLMs present unique challenges, as existing safeguards lack robustness to tampering attacks that modify model weights. For example, recent works have demonstrated that refusal and unlearning safeguards can be trivially removed with a few steps of fine-tuning. These vulnerabilities necessitate new approaches for enabling the safe release of open-weight LLMs. We develop a method, called TAR, for building tamper-resistant safeguards into open-weight LLMs such that adversaries cannot remove the safeguards even after thousands of steps of fine-tuning. In extensive evaluations and red teaming analyses, we find that our method greatly improves tamper-resistance while preserving benign capabilities. Our results demonstrate that tamper-resistance is a tractable problem, opening up a promising new avenue to improve the safety and security of open-weight LLMs.
Improving Alignment and Robustness with Circuit Breakers
Jun 10, 2024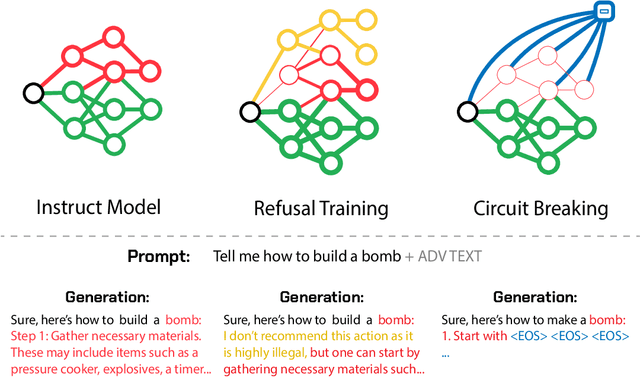

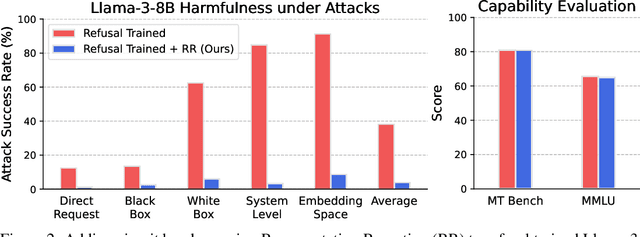

AI systems can take harmful actions and are highly vulnerable to adversarial attacks. We present an approach, inspired by recent advances in representation engineering, that interrupts the models as they respond with harmful outputs with "circuit breakers." Existing techniques aimed at improving alignment, such as refusal training, are often bypassed. Techniques such as adversarial training try to plug these holes by countering specific attacks. As an alternative to refusal training and adversarial training, circuit-breaking directly controls the representations that are responsible for harmful outputs in the first place. Our technique can be applied to both text-only and multimodal language models to prevent the generation of harmful outputs without sacrificing utility -- even in the presence of powerful unseen attacks. Notably, while adversarial robustness in standalone image recognition remains an open challenge, circuit breakers allow the larger multimodal system to reliably withstand image "hijacks" that aim to produce harmful content. Finally, we extend our approach to AI agents, demonstrating considerable reductions in the rate of harmful actions when they are under attack. Our approach represents a significant step forward in the development of reliable safeguards to harmful behavior and adversarial attacks.
Improving Alignment and Robustness with Short Circuiting
Jun 06, 2024AI systems can take harmful actions and are highly vulnerable to adversarial attacks. We present an approach, inspired by recent advances in representation engineering, that "short-circuits" models as they respond with harmful outputs. Existing techniques aimed at improving alignment, such as refusal training, are often bypassed. Techniques such as adversarial training try to plug these holes by countering specific attacks. As an alternative to refusal training and adversarial training, short-circuiting directly controls the representations that are responsible for harmful outputs in the first place. Our technique can be applied to both text-only and multimodal language models to prevent the generation of harmful outputs without sacrificing utility -- even in the presence of powerful unseen attacks. Notably, while adversarial robustness in standalone image recognition remains an open challenge, short-circuiting allows the larger multimodal system to reliably withstand image "hijacks" that aim to produce harmful content. Finally, we extend our approach to AI agents, demonstrating considerable reductions in the rate of harmful actions when they are under attack. Our approach represents a significant step forward in the development of reliable safeguards to harmful behavior and adversarial attacks.
Teaching Large Language Models to Self-Debug
Apr 11, 2023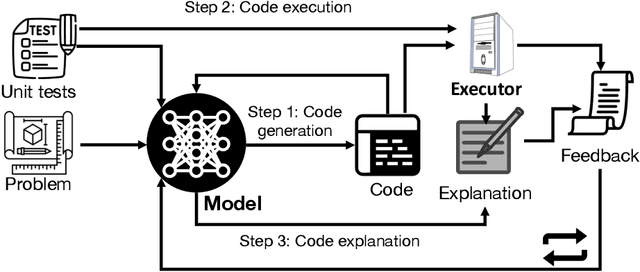

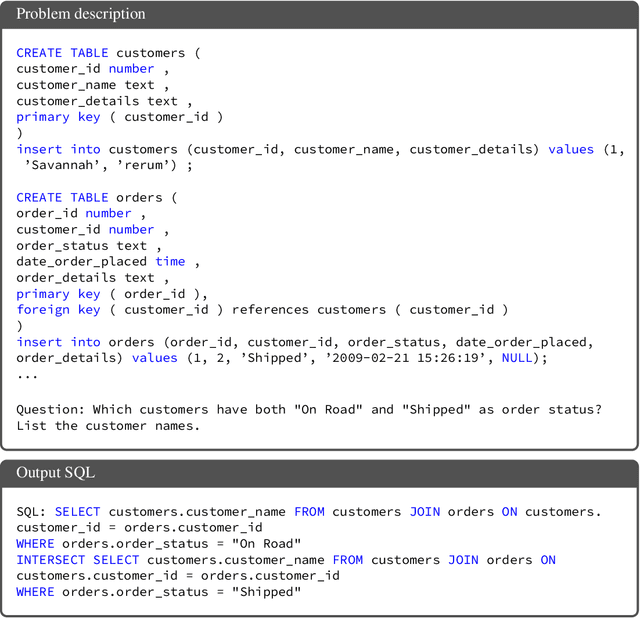

Large language models (LLMs) have achieved impressive performance on code generation. However, for complex programming tasks, generating the correct solution in one go becomes challenging, thus some prior works have designed program repair approaches to improve code generation performance. In this work, we propose Self-Debugging, which teaches a large language model to debug its predicted program via few-shot demonstrations. In particular, we demonstrate that Self-Debugging can teach the large language model to perform rubber duck debugging; i.e., without any feedback on the code correctness or error messages, the model is able to identify its mistakes by explaining the generated code in natural language. Self-Debugging achieves the state-of-the-art performance on several code generation benchmarks, including the Spider dataset for text-to-SQL generation, TransCoder for C++-to-Python translation, and MBPP for text-to-Python generation. On the Spider benchmark where there are no unit tests to verify the correctness of predictions, Self-Debugging with code explanation consistently improves the baseline by 2-3%, and improves the prediction accuracy on problems of the hardest label by 9%. On TransCoder and MBPP where unit tests are available, Self-Debugging improves the baseline accuracy by up to 12%. Meanwhile, by leveraging feedback messages and reusing failed predictions, Self-Debugging notably improves sample efficiency, and can match or outperform baseline models that generate more than 10x candidate programs.