 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-Time Adaptation via Conjugate Pseudo-labels
Paper and Code



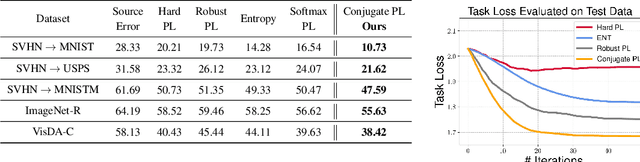
Test-time adaptation (TTA) refers to adapting neural networks to distribution shifts, with access to only the unlabeled test samples from the new domain at test-time. Prior TTA methods optimize over unsupervised objectives such as the entropy of model predictions in TENT [Wang et al., 2021], but it is unclear what exactly makes a good TTA loss. In this paper, we start by presenting a surprising phenomenon: if we attempt to meta-learn the best possible TTA loss over a wide class of functions, then we recover a function that is remarkably similar to (a temperature-scaled version of) the softmax-entropy employed by TENT. This only holds, however, if the classifier we are adapting is trained via cross-entropy; if trained via squared loss, a different best TTA loss emerges. To explain this phenomenon, we analyze TTA through the lens of the training losses's convex conjugate. We show that under natural conditions, this (unsupervised) conjugate function can be viewed as a good local approximation to the original supervised loss and indeed, it recovers the best losses found by meta-learning. This leads to a generic recipe that can be used to find a good TTA loss for any given supervised training loss function of a general class. Empirically, our approach consistently dominates other baselines over a wide range of benchmarks. Our approach is particularly of interest when applied to classifiers trained with novel loss functions, e.g., the recently-proposed PolyLoss, where it differs substantially from (and outperforms) an entropy-based loss. Further, we show that our approach can also be interpreted as a kind of self-training using a very specific soft label, which we refer to as the conjugate pseudolabel. Overall, our method provides a broad framework for better understanding and improving test-time adaptation. Code is available at https://github.com/locuslab/tta_conjugate.