 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Data Exposure Improves Robustness to Subsequent Fine-Tuning
May 12, 2026How can we train models whose post-trained capabilities survive subsequent fine-tuning? Rather than focusing on downstream interventions to mitigate forgetting of upstream capabilities, we study how upstream training choices - that is, the manner in which a capability is acquired - shape how robustly that capability is retained. We investigate this question in a controlled three-stage language-model pipeline: pretraining, post-training to acquire a target capability, and downstream fine-tuning on a new objective. Across 135M and 1B models, two post-training domains, and two downstream fine-tuning tasks, we find that immediate post-training performance does not reliably predict retention after subsequent fine-tuning: training recipes that look equivalent immediately after post-training can retain the target capability very differently after subsequent fine-tuning. In particular, early exposure - mixing post-training data into pretraining - consistently improves the frontier between retained upstream performance and downstream performance. In compute-matched experiments, where the target data must be allocated between pretraining and post-training, we find that the optimum lies at neither extreme. Together with our other empirical and theoretical findings, this supports the view that post-training drives immediate specialization while early exposure improves robustness to later forgetting. Replay and dropout, typically used to mitigate forgetting as it occurs during fine-tuning, provide complementary gains to early exposure when applied during post-training. Our findings suggest that robustness to subsequent fine-tuning should be treated as a first-class objective of upstream training, addressed preventatively through choices like early exposure rather than reactively during fine-tuning itself.
Annotations Mitigate Post-Training Mode Collapse
May 11, 2026Post-training (via supervised fine-tuning) improves instruction-following, but often induces semantic mode collapse by biasing models toward low-entropy fine-tuning data at the expense of the high-entropy pretraining distribution. Crucially, we find this trade-off worsens with scale. To close this semantic diversity gap, we propose annotation-anchored training, a principled method that enables models to adopt the preference-following behaviors of post-training without sacrificing the inherent diversity of pretraining. Our approach is simple: we pretrain on documents paired with semantic annotations, inducing a rich annotation distribution that reflects the full breadth of pretraining data, and we preserve this distribution during post-training. This lets us sample diverse annotations at inference time and use them as anchors to guide generation, effectively transferring pretraining's semantic richness into post-trained models. We find that models trained with annotation-anchored training can attain $6 \times$ less diversity collapse than models trained with SFT, and improve with scale.
Sharpness-Aware Pretraining Mitigates Catastrophic Forgetting
May 04, 2026Pretraining optimizers are tuned to produce the strongest possible base model, on the assumption that a stronger starting point yields a stronger model after subsequent changes like post-training and quantization. This overlooks the geometry of the base model which controls how much of the base model's capabilities survive subsequent parameter updates. We study three pretraining optimization approaches that bias optimization toward flatter minima: Sharpness-Aware Minimization (SAM), large learning rates, and shortened learning rate annealing periods. Across model sizes ranging from 20M to 150M parameters, we find that these interventions consistently improve downstream performance after post-training on five common datasets with up to 80% less forgetting. These principles hold at scale: a short SAM mid-training phase applied to an existing OLMo-2-1B checkpoint reduces forgetting by 31% after MetaMath post-training and by 40% after 4-bit quantization.
Disentangling Geometry, Performance, and Training in Language Models
Feb 24, 2026Geometric properties of Transformer weights, particularly the unembedding matrix, have been widely useful in language model interpretability research. Yet, their utility for estimating downstream performance remains unclear. In this work, we systematically investigate the relationship between model performance and the unembedding matrix geometry, particularly its effective rank. Our experiments, involving a suite of 108 OLMo-style language models trained under controlled variation, reveal several key findings. While the best-performing models often exhibit a high effective rank, this trend is not universal across tasks and training setups. Contrary to prior work, we find that low effective rank does not cause late-stage performance degradation in small models, but instead co-occurs with it; we find adversarial cases where low-rank models do not exhibit saturation. Moreover, we show that effective rank is strongly influenced by pre-training hyperparameters, such as batch size and weight decay, which in-turn affect the model's performance. Lastly, extending our analysis to other geometric metrics and final-layer representation, we find that these metrics are largely aligned, but none can reliably predict downstream performance. Overall, our findings suggest that the model's geometry, as captured by existing metrics, primarily reflects training choices rather than performance.
Overtrained Language Models Are Harder to Fine-Tune
Mar 24, 2025



Large language models are pre-trained on ever-growing token budgets under the assumption that better pre-training performance translates to improved downstream models. In this work, we challenge this assumption and show that extended pre-training can make models harder to fine-tune, leading to degraded final performance. We term this phenomenon catastrophic overtraining. For example, the instruction-tuned OLMo-1B model pre-trained on 3T tokens leads to over 2% worse performance on multiple standard LLM benchmarks than its 2.3T token counterpart. Through controlled experiments and theoretical analysis, we show that catastrophic overtraining arises from a systematic increase in the broad sensitivity of pre-trained parameters to modifications, including but not limited to fine-tuning. Our findings call for a critical reassessment of pre-training design that considers the downstream adaptability of the model.
Sharpness-Aware Minimization Enhances Feature Quality via Balanced Learning
May 30, 2024
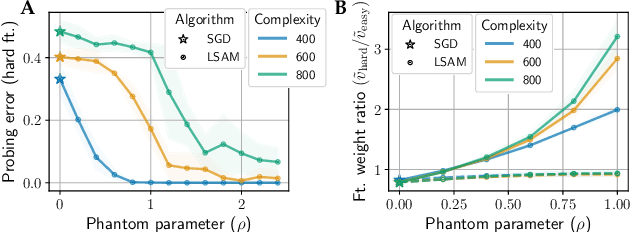
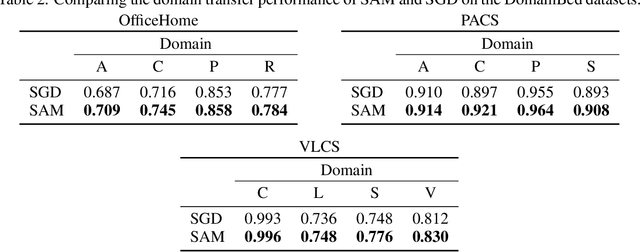
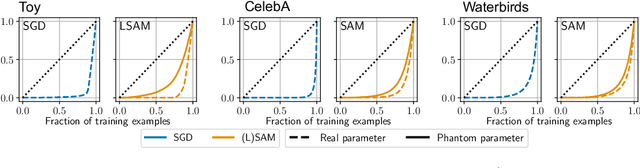
Sharpness-Aware Minimization (SAM) has emerged as a promising alternative optimizer to stochastic gradient descent (SGD). The originally-proposed motivation behind SAM was to bias neural networks towards flatter minima that are believed to generalize better. However, recent studies have shown conflicting evidence on the relationship between flatness and generalization, suggesting that flatness does fully explain SAM's success. Sidestepping this debate, we identify an orthogonal effect of SAM that is beneficial out-of-distribution: we argue that SAM implicitly balances the quality of diverse features. SAM achieves this effect by adaptively suppressing well-learned features which gives remaining features opportunity to be learned. We show that this mechanism is beneficial in datasets that contain redundant or spurious features where SGD falls for the simplicity bias and would not otherwise learn all available features. Our insights are supported by experiments on real data: we demonstrate that SAM improves the quality of features in datasets containing redundant or spurious features, including CelebA, Waterbirds, CIFAR-MNIST, and DomainBed.
Repetition Improves Language Model Embeddings
Feb 23, 2024



Recent approaches to improving the extraction of text embeddings from autoregressive large language models (LLMs) have largely focused on improvements to data, backbone pretrained language models, or improving task-differentiation via instructions. In this work, we address an architectural limitation of autoregressive models: token embeddings cannot contain information from tokens that appear later in the input. To address this limitation, we propose a simple approach, "echo embeddings," in which we repeat the input twice in context and extract embeddings from the second occurrence. We show that echo embeddings of early tokens can encode information about later tokens, allowing us to maximally leverage high-quality LLMs for embeddings. On the MTEB leaderboard, echo embeddings improve over classical embeddings by over 9% zero-shot and by around 0.7% when fine-tuned. Echo embeddings with a Mistral-7B model achieve state-of-the-art compared to prior open source models that do not leverage synthetic fine-tuning data.
Understanding Catastrophic Forgetting in Language Models via Implicit Inference
Sep 18, 2023



Fine-tuning (via methods such as instruction-tuning or reinforcement learning from human feedback) is a crucial step in training language models to robustly carry out tasks of interest. However, we lack a systematic understanding of the effects of fine-tuning, particularly on tasks outside the narrow fine-tuning distribution. In a simplified scenario, we demonstrate that improving performance on tasks within the fine-tuning data distribution comes at the expense of suppressing model capabilities on other tasks. This degradation is especially pronounced for tasks "closest" to the fine-tuning distribution. We hypothesize that language models implicitly infer the task of the prompt corresponds, and the fine-tuning process predominantly skews this task inference towards tasks in the fine-tuning distribution. To test this hypothesis, we propose Conjugate Prompting to see if we can recover pretrained capabilities. Conjugate prompting artificially makes the task look farther from the fine-tuning distribution while requiring the same capability. We find that conjugate prompting systematically recovers some of the pretraining capabilities on our synthetic setup. We then apply conjugate prompting to real-world LLMs using the observation that fine-tuning distributions are typically heavily skewed towards English. We find that simply translating the prompts to different languages can cause the fine-tuned models to respond like their pretrained counterparts instead. This allows us to recover the in-context learning abilities lost via instruction tuning, and more concerningly, to recover harmful content generation suppressed by safety fine-tuning in chatbots like ChatGPT.