 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEureka-Moments in Transformers: Multi-Step Tasks Reveal Softmax Induced Optimization Problems
Oct 19, 2023



In this work, we study rapid, step-wise improvements of the loss in transformers when being confronted with multi-step decision tasks. We found that transformers struggle to learn the intermediate tasks, whereas CNNs have no such issue on the tasks we studied. When transformers learn the intermediate task, they do this rapidly and unexpectedly after both training and validation loss saturated for hundreds of epochs. We call these rapid improvements Eureka-moments, since the transformer appears to suddenly learn a previously incomprehensible task. Similar leaps in performance have become known as Grokking. In contrast to Grokking, for Eureka-moments, both the validation and the training loss saturate before rapidly improving. We trace the problem back to the Softmax function in the self-attention block of transformers and show ways to alleviate the problem. These fixes improve training speed. The improved models reach 95% of the baseline model in just 20% of training steps while having a much higher likelihood to learn the intermediate task, lead to higher final accuracy and are more robust to hyper-parameters.
Unified Fully and Timestamp Supervised Temporal Action Segmentation via Sequence to Sequence Translation
Sep 01, 2022
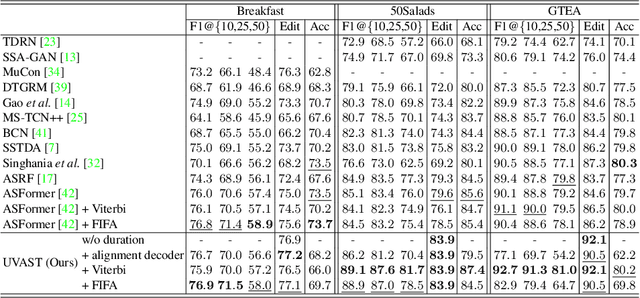
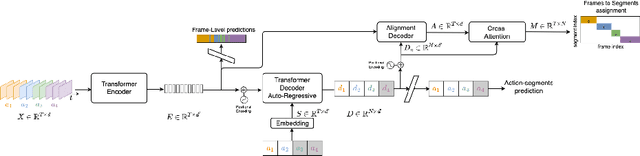
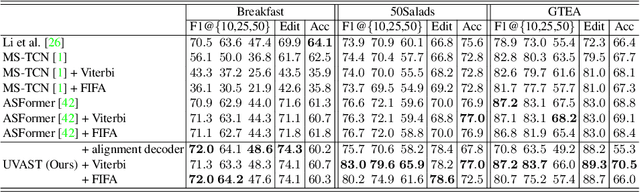
This paper introduces a unified framework for video action segmentation via sequence to sequence (seq2seq) translation in a fully and timestamp supervised setup. In contrast to current state-of-the-art frame-level prediction methods, we view action segmentation as a seq2seq translation task, i.e., mapping a sequence of video frames to a sequence of action segments. Our proposed method involves a series of modifications and auxiliary loss functions on the standard Transformer seq2seq translation model to cope with long input sequences opposed to short output sequences and relatively few videos. We incorporate an auxiliary supervision signal for the encoder via a frame-wise loss and propose a separate alignment decoder for an implicit duration prediction. Finally, we extend our framework to the timestamp supervised setting via our proposed constrained k-medoids algorithm to generate pseudo-segmentations. Our proposed framework performs consistently on both fully and timestamp supervised settings, outperforming or competing state-of-the-art on several datasets.
Ranking Info Noise Contrastive Estimation: Boosting Contrastive Learning via Ranked Positives
Jan 27, 2022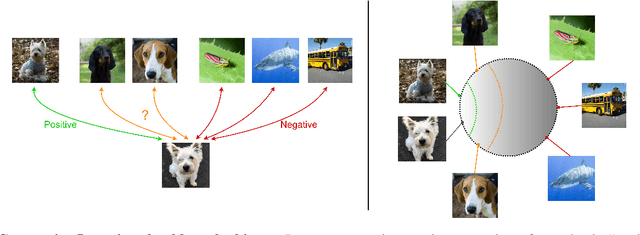

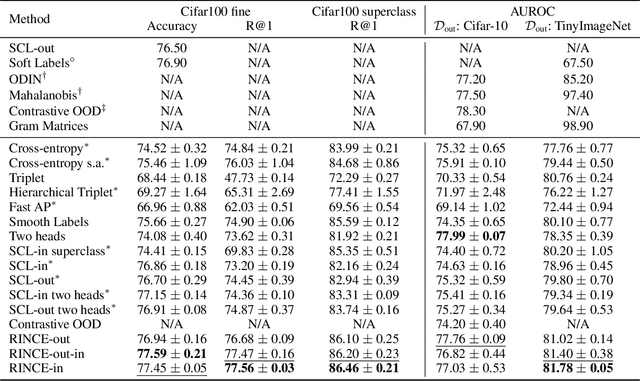
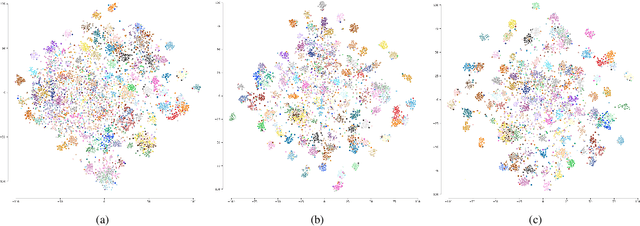
This paper introduces Ranking Info Noise Contrastive Estimation (RINCE), a new member in the family of InfoNCE losses that preserves a ranked ordering of positive samples. In contrast to the standard InfoNCE loss, which requires a strict binary separation of the training pairs into similar and dissimilar samples, RINCE can exploit information about a similarity ranking for learning a corresponding embedding space. We show that the proposed loss function learns favorable embeddings compared to the standard InfoNCE whenever at least noisy ranking information can be obtained or when the definition of positives and negatives is blurry. We demonstrate this for a supervised classification task with additional superclass labels and noisy similarity scores. Furthermore, we show that RINCE can also be applied to unsupervised training with experiments on unsupervised representation learning from videos. In particular, the embedding yields higher classification accuracy, retrieval rates and performs better in out-of-distribution detection than the standard InfoNCE loss.
Long Short View Feature Decomposition via Contrastive Video Representation Learning
Sep 23, 2021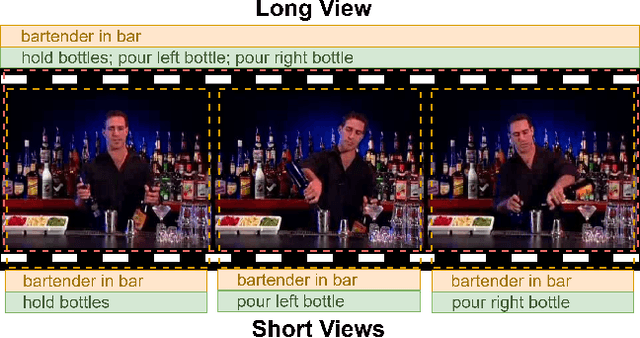
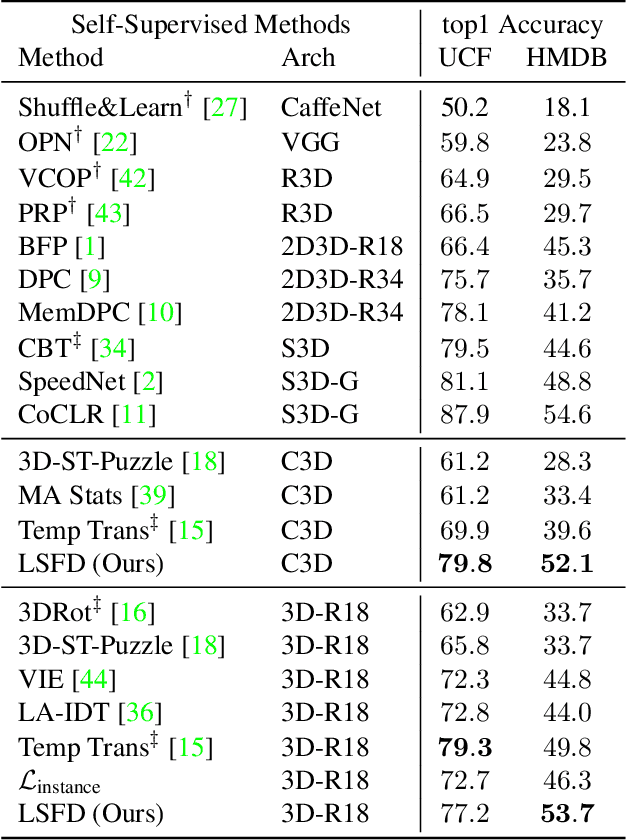
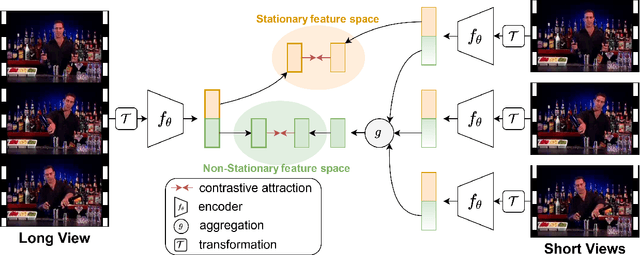
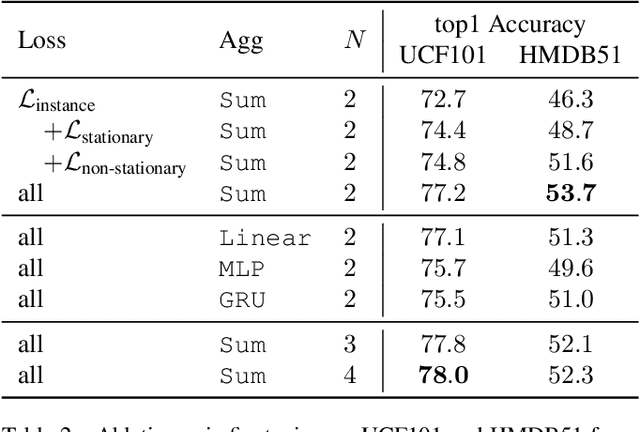
Self-supervised video representation methods typically focus on the representation of temporal attributes in videos. However, the role of stationary versus non-stationary attributes is less explored: Stationary features, which remain similar throughout the video, enable the prediction of video-level action classes. Non-stationary features, which represent temporally varying attributes, are more beneficial for downstream tasks involving more fine-grained temporal understanding, such as action segmentation. We argue that a single representation to capture both types of features is sub-optimal, and propose to decompose the representation space into stationary and non-stationary features via contrastive learning from long and short views, i.e. long video sequences and their shorter sub-sequences. Stationary features are shared between the short and long views, while non-stationary features aggregate the short views to match the corresponding long view. To empirically verify our approach, we demonstrate that our stationary features work particularly well on an action recognition downstream task, while our non-stationary features perform better on action segmentation. Furthermore, we analyse the learned representations and find that stationary features capture more temporally stable, static attributes, while non-stationary features encompass more temporally varying ones.
Unsupervised Video Representation Learning by Bidirectional Feature Prediction
Nov 11, 2020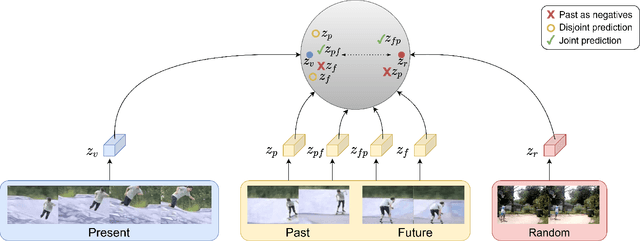
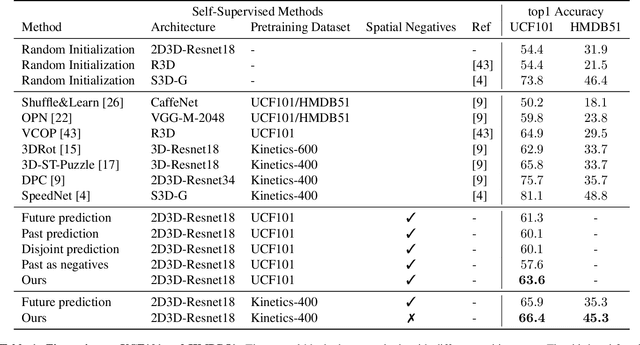

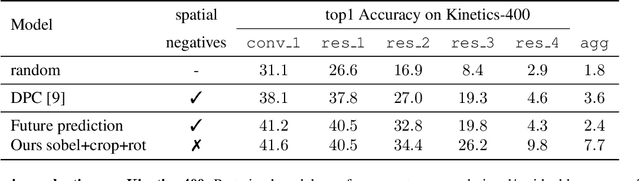
This paper introduces a novel method for self-supervised video representation learning via feature prediction. In contrast to the previous methods that focus on future feature prediction, we argue that a supervisory signal arising from unobserved past frames is complementary to one that originates from the future frames. The rationale behind our method is to encourage the network to explore the temporal structure of videos by distinguishing between future and past given present observations. We train our model in a contrastive learning framework, where joint encoding of future and past provides us with a comprehensive set of temporal hard negatives via swapping. We empirically show that utilizing both signals enriches the learned representations for the downstream task of action recognition. It outperforms independent prediction of future and past.