 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDNN-Compressed Domain Visual Recognition with Feature Adaptation
May 13, 2023



Learning-based image compression was shown to achieve a competitive performance with state-of-the-art transform-based codecs. This motivated the development of new learning-based visual compression standards such as JPEG-AI. Of particular interest to these emerging standards is the development of learning-based image compression systems targeting both humans and machines. This paper is concerned with learning-based compression schemes whose compressed-domain representations can be utilized to perform visual processing and computer vision tasks directly in the compressed domain. In our work, we adopt a learning-based compressed-domain classification framework for performing visual recognition using the compressed-domain latent representation at varying bit-rates. We propose a novel feature adaptation module integrating a lightweight attention model to adaptively emphasize and enhance the key features within the extracted channel-wise information. Also, we design an adaptation training strategy to utilize the pretrained pixel-domain weights. For comparison, in addition to the performance results that are obtained using our proposed latent-based compressed-domain method, we also present performance results using compressed but fully decoded images in the pixel domain as well as original uncompressed images. The obtained performance results show that our proposed compressed-domain classification model can distinctly outperform the existing compressed-domain classification models, and that it can also yield similar accuracy results with a much higher computational efficiency as compared to the pixel-domain models that are trained using fully decoded images.
Learning-based Compression for Material and Texture Recognition
Apr 16, 2021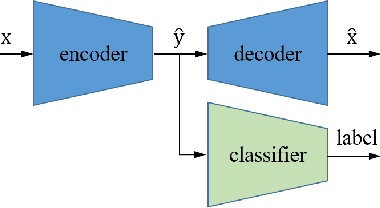
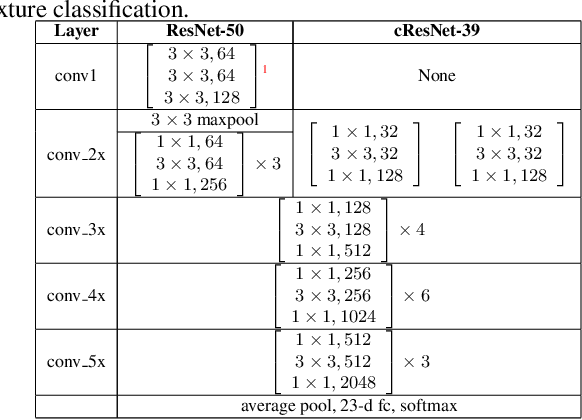

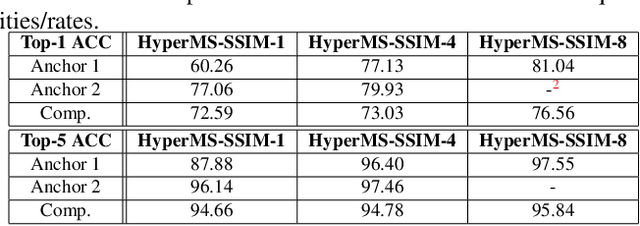
Learning-based image compression was shown to achieve a competitive performance with state-of-the-art transform-based codecs. This motivated the development of new learning-based visual compression standards such as JPEG-AI. Of particular interest to these emerging standards is the development of learning-based image compression systems targeting both humans and machines. This paper is concerned with learning-based compression schemes whose compressed-domain representations can be utilized to perform visual processing and computer vision tasks directly in the compressed domain. Such a characteristic has been incorporated as part of the scope and requirements of the new emerging JPEG-AI standard. In our work, we adopt the learning-based JPEG-AI framework for performing material and texture recognition using the compressed-domain latent representation at varing bit-rates. For comparison, performance results are presented using compressed but fully decoded images in the pixel domain as well as original uncompressed images. The obtained performance results show that even though decoded images can degrade the classification performance of the model trained with original images, retraining the model with decoded images will largely reduce the performance gap for the adopted texture dataset. It is also shown that the compressed-domain classification can yield a competitive performance in terms of Top-1 and Top-5 accuracy while using a smaller reduced-complexity classification model.
Towards Imperceptible Universal Attacks on Texture Recognition
Nov 24, 2020
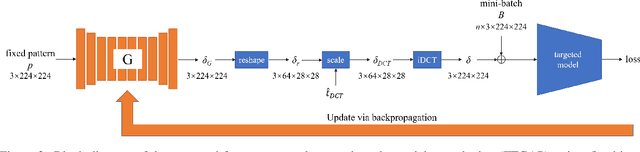
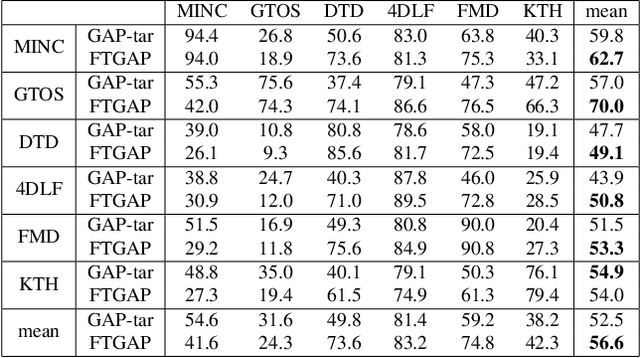
Although deep neural networks (DNNs) have been shown to be susceptible to image-agnostic adversarial attacks on natural image classification problems, the effects of such attacks on DNN-based texture recognition have yet to be explored. As part of our work, we find that limiting the perturbation's $l_p$ norm in the spatial domain may not be a suitable way to restrict the perceptibility of universal adversarial perturbations for texture images. Based on the fact that human perception is affected by local visual frequency characteristics, we propose a frequency-tuned universal attack method to compute universal perturbations in the frequency domain. Our experiments indicate that our proposed method can produce less perceptible perturbations yet with a similar or higher white-box fooling rates on various DNN texture classifiers and texture datasets as compared to existing universal attack techniques. We also demonstrate that our approach can improve the attack robustness against defended models as well as the cross-dataset transferability for texture recognition problems.
A Study for Universal Adversarial Attacks on Texture Recognition
Oct 04, 2020

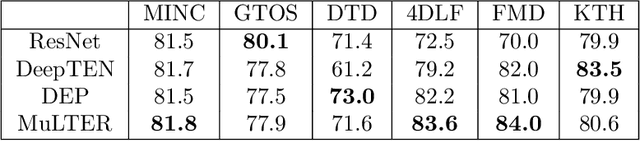

Given the outstanding progress that convolutional neural networks (CNNs) have made on natural image classification and object recognition problems, it is shown that deep learning methods can achieve very good recognition performance on many texture datasets. However, while CNNs for natural image classification/object recognition tasks have been revealed to be highly vulnerable to various types of adversarial attack methods, the robustness of deep learning methods for texture recognition is yet to be examined. In our paper, we show that there exist small image-agnostic/univesal perturbations that can fool the deep learning models with more than 80\% of testing fooling rates on all tested texture datasets. The computed perturbations using various attack methods on the tested datasets are generally quasi-imperceptible, containing structured patterns with low, middle and high frequency components.
Frequency-Tuned Universal Adversarial Attacks
Mar 11, 2020

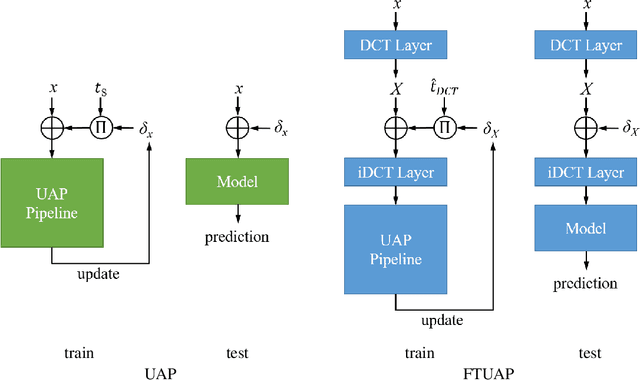

Researchers have shown that the predictions of a convolutional neural network (CNN) for an image set can be severely distorted by one single image-agnostic perturbation, or universal perturbation, usually with an empirically fixed threshold in the spatial domain to restrict its perceivability. However, by considering the human perception, we propose to adopt JND thresholds to guide the perceivability of universal adversarial perturbations. Based on this, we propose a frequency-tuned universal attack method to compute universal perturbations and show that our method can realize a good balance between perceivability and effectiveness in terms of fooling rate by adapting the perturbations to the local frequency content. Compared with existing universal adversarial attack techniques, our frequency-tuned attack method can achieve cutting-edge quantitative results. We demonstrate that our approach can significantly improve the performance of the baseline on both white-box and black-box attacks.
It GAN DO Better: GAN-based Detection of Objects on Images with Varying Quality
Dec 03, 2019
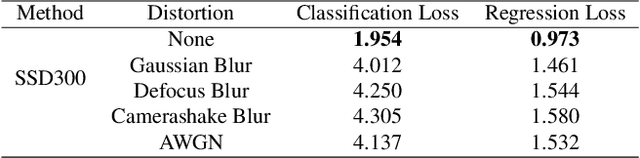
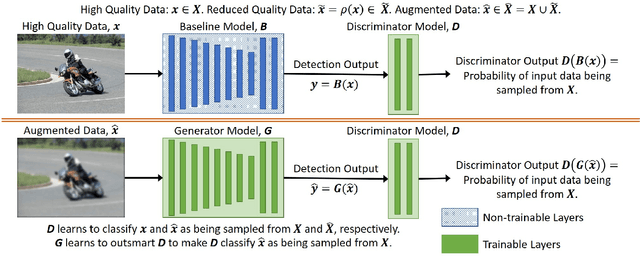
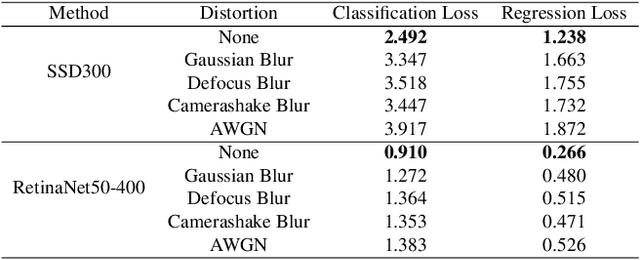
In this paper, we propose in our novel generative framework the use of Generative Adversarial Networks (GANs) to generate features that provide robustness for object detection on reduced quality images. The proposed GAN-based Detection of Objects (GAN-DO) framework is not restricted to any particular architecture and can be generalized to several deep neural network (DNN) based architectures. The resulting deep neural network maintains the exact architecture as the selected baseline model without adding to the model parameter complexity or inference speed. We first evaluate the effect of image quality not only on the object classification but also on the object bounding box regression. We then test the models resulting from our proposed GAN-DO framework, using two state-of-the-art object detection architectures as the baseline models. We also evaluate the effect of the number of re-trained parameters in the generator of GAN-DO on the accuracy of the final trained model. Performance results provided using GAN-DO on object detection datasets establish an improved robustness to varying image quality and a higher mAP compared to the existing approaches.
A Locally Weighted Fixation Density-Based Metric for Assessing the Quality of Visual Saliency Predictions
Aug 01, 2017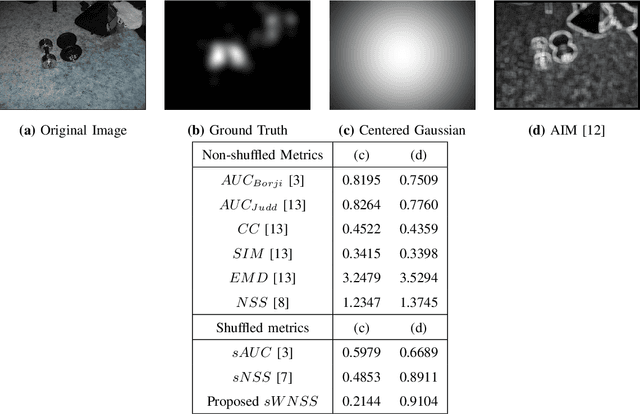



With the increased focus on visual attention (VA) in the last decade, a large number of computational visual saliency methods have been developed over the past few years. These models are traditionally evaluated by using performance evaluation metrics that quantify the match between predicted saliency and fixation data obtained from eye-tracking experiments on human observers. Though a considerable number of such metrics have been proposed in the literature, there are notable problems in them. In this work, we discuss shortcomings in existing metrics through illustrative examples and propose a new metric that uses local weights based on fixation density which overcomes these flaws. To compare the performance of our proposed metric at assessing the quality of saliency prediction with other existing metrics, we construct a ground-truth subjective database in which saliency maps obtained from 17 different VA models are evaluated by 16 human observers on a 5-point categorical scale in terms of their visual resemblance with corresponding ground-truth fixation density maps obtained from eye-tracking data. The metrics are evaluated by correlating metric scores with the human subjective ratings. The correlation results show that the proposed evaluation metric outperforms all other popular existing metrics. Additionally, the constructed database and corresponding subjective ratings provide an insight into which of the existing metrics and future metrics are better at estimating the quality of saliency prediction and can be used as a benchmark.
Spatially-Varying Blur Detection Based on Multiscale Fused and Sorted Transform Coefficients of Gradient Magnitudes
Apr 11, 2017

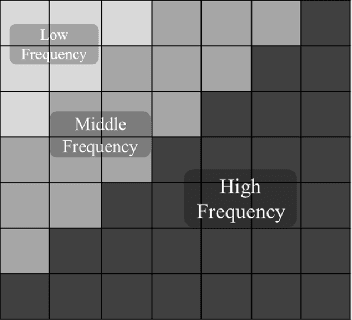

The detection of spatially-varying blur without having any information about the blur type is a challenging task. In this paper, we propose a novel effective approach to address the blur detection problem from a single image without requiring any knowledge about the blur type, level, or camera settings. Our approach computes blur detection maps based on a novel High-frequency multiscale Fusion and Sort Transform (HiFST) of gradient magnitudes. The evaluations of the proposed approach on a diverse set of blurry images with different blur types, levels, and contents demonstrate that the proposed algorithm performs favorably against the state-of-the-art methods qualitatively and quantitatively.
The Effect of Distortions on the Prediction of Visual Attention
Apr 13, 2016



Existing saliency models have been designed and evaluated for predicting the saliency in distortion-free images. However, in practice, the image quality is affected by a host of factors at several stages of the image processing pipeline such as acquisition, compression and transmission. Several studies have explored the effect of distortion on human visual attention; however, none of them have considered the performance of visual saliency models in the presence of distortion. Furthermore, given that one potential application of visual saliency prediction is to aid pooling of objective visual quality metrics, it is important to compare the performance of existing saliency models on distorted images. In this paper, we evaluate several state-of-the-art visual attention models over different databases consisting of distorted images with various types of distortions such as blur, noise and compression with varying levels of distortion severity. This paper also introduces new improved performance evaluation metrics that are shown to overcome shortcomings in existing performance metrics. We find that the performance of most models improves with moderate and high levels of distortions as compared to the near distortion-free case. In addition, model performance is also found to decrease with an increase in image complexity.
Is Bottom-Up Attention Useful for Scene Recognition?
Jul 22, 2013

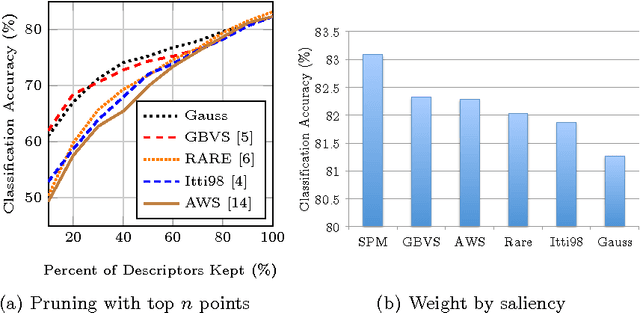
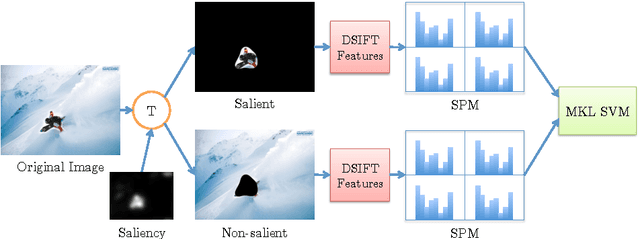
The human visual system employs a selective attention mechanism to understand the visual world in an eficient manner. In this paper, we show how computational models of this mechanism can be exploited for the computer vision application of scene recognition. First, we consider saliency weighting and saliency pruning, and provide a comparison of the performance of different attention models in these approaches in terms of classification accuracy. Pruning can achieve a high degree of computational savings without significantly sacrificing classification accuracy. In saliency weighting, however, we found that classification performance does not improve. In addition, we present a new method to incorporate salient and non-salient regions for improved classification accuracy. We treat the salient and non-salient regions separately and combine them using Multiple Kernel Learning. We evaluate our approach using the UIUC sports dataset and find that with a small training size, our method improves upon the classification accuracy of the baseline bag of features approach.