 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Locally Weighted Fixation Density-Based Metric for Assessing the Quality of Visual Saliency Predictions
Aug 01, 2017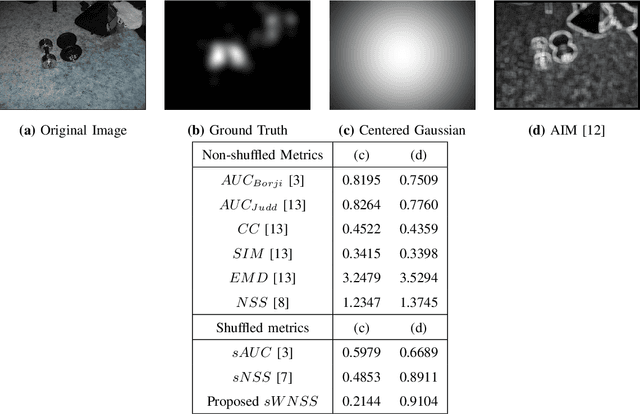



With the increased focus on visual attention (VA) in the last decade, a large number of computational visual saliency methods have been developed over the past few years. These models are traditionally evaluated by using performance evaluation metrics that quantify the match between predicted saliency and fixation data obtained from eye-tracking experiments on human observers. Though a considerable number of such metrics have been proposed in the literature, there are notable problems in them. In this work, we discuss shortcomings in existing metrics through illustrative examples and propose a new metric that uses local weights based on fixation density which overcomes these flaws. To compare the performance of our proposed metric at assessing the quality of saliency prediction with other existing metrics, we construct a ground-truth subjective database in which saliency maps obtained from 17 different VA models are evaluated by 16 human observers on a 5-point categorical scale in terms of their visual resemblance with corresponding ground-truth fixation density maps obtained from eye-tracking data. The metrics are evaluated by correlating metric scores with the human subjective ratings. The correlation results show that the proposed evaluation metric outperforms all other popular existing metrics. Additionally, the constructed database and corresponding subjective ratings provide an insight into which of the existing metrics and future metrics are better at estimating the quality of saliency prediction and can be used as a benchmark.
The Effect of Distortions on the Prediction of Visual Attention
Apr 13, 2016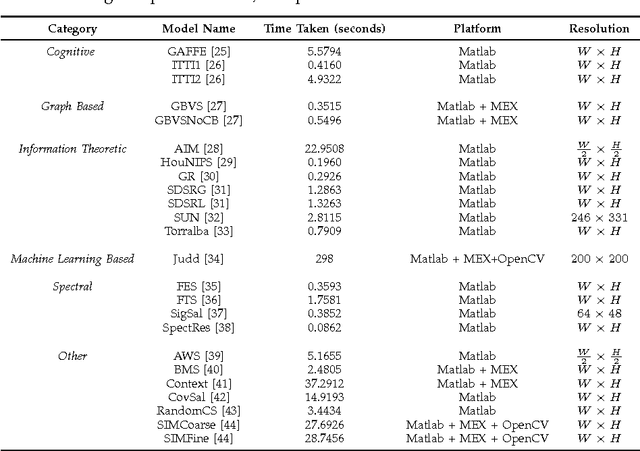



Existing saliency models have been designed and evaluated for predicting the saliency in distortion-free images. However, in practice, the image quality is affected by a host of factors at several stages of the image processing pipeline such as acquisition, compression and transmission. Several studies have explored the effect of distortion on human visual attention; however, none of them have considered the performance of visual saliency models in the presence of distortion. Furthermore, given that one potential application of visual saliency prediction is to aid pooling of objective visual quality metrics, it is important to compare the performance of existing saliency models on distorted images. In this paper, we evaluate several state-of-the-art visual attention models over different databases consisting of distorted images with various types of distortions such as blur, noise and compression with varying levels of distortion severity. This paper also introduces new improved performance evaluation metrics that are shown to overcome shortcomings in existing performance metrics. We find that the performance of most models improves with moderate and high levels of distortions as compared to the near distortion-free case. In addition, model performance is also found to decrease with an increase in image complexity.