 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Distortions on the Prediction of Visual Attention
Apr 13, 2016



Existing saliency models have been designed and evaluated for predicting the saliency in distortion-free images. However, in practice, the image quality is affected by a host of factors at several stages of the image processing pipeline such as acquisition, compression and transmission. Several studies have explored the effect of distortion on human visual attention; however, none of them have considered the performance of visual saliency models in the presence of distortion. Furthermore, given that one potential application of visual saliency prediction is to aid pooling of objective visual quality metrics, it is important to compare the performance of existing saliency models on distorted images. In this paper, we evaluate several state-of-the-art visual attention models over different databases consisting of distorted images with various types of distortions such as blur, noise and compression with varying levels of distortion severity. This paper also introduces new improved performance evaluation metrics that are shown to overcome shortcomings in existing performance metrics. We find that the performance of most models improves with moderate and high levels of distortions as compared to the near distortion-free case. In addition, model performance is also found to decrease with an increase in image complexity.
Is Bottom-Up Attention Useful for Scene Recognition?
Jul 22, 2013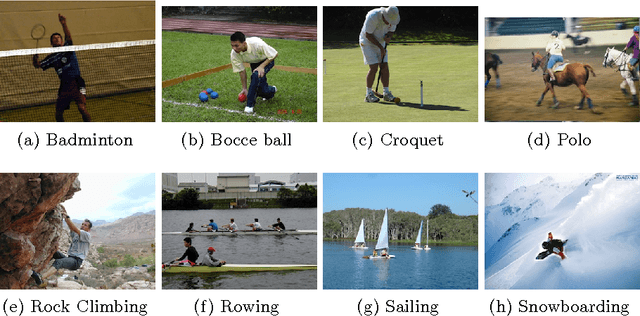

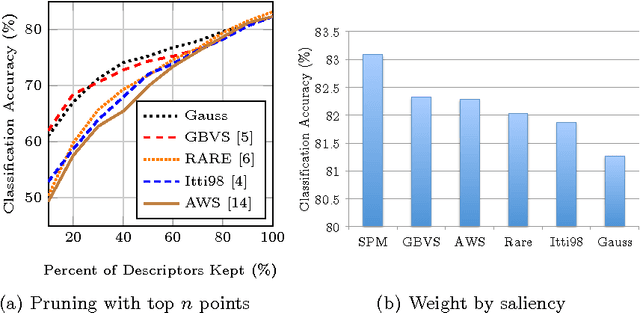
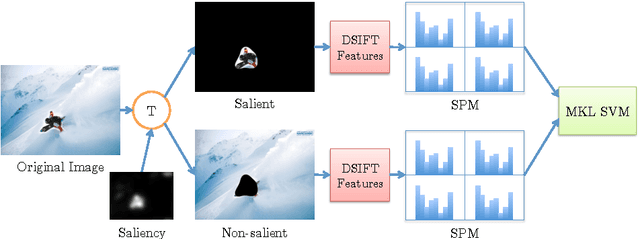
The human visual system employs a selective attention mechanism to understand the visual world in an eficient manner. In this paper, we show how computational models of this mechanism can be exploited for the computer vision application of scene recognition. First, we consider saliency weighting and saliency pruning, and provide a comparison of the performance of different attention models in these approaches in terms of classification accuracy. Pruning can achieve a high degree of computational savings without significantly sacrificing classification accuracy. In saliency weighting, however, we found that classification performance does not improve. In addition, we present a new method to incorporate salient and non-salient regions for improved classification accuracy. We treat the salient and non-salient regions separately and combine them using Multiple Kernel Learning. We evaluate our approach using the UIUC sports dataset and find that with a small training size, our method improves upon the classification accuracy of the baseline bag of features approach.