 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Bottom-Up Attention Useful for Scene Recognition?
Paper and Code
Jul 22, 2013

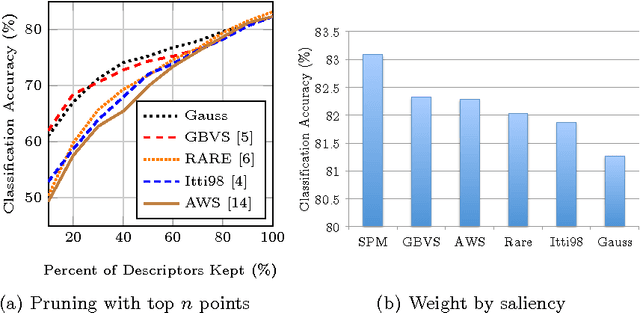
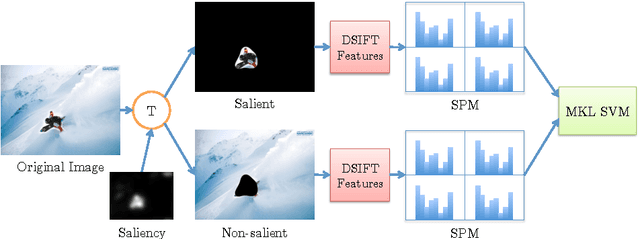
The human visual system employs a selective attention mechanism to understand the visual world in an eficient manner. In this paper, we show how computational models of this mechanism can be exploited for the computer vision application of scene recognition. First, we consider saliency weighting and saliency pruning, and provide a comparison of the performance of different attention models in these approaches in terms of classification accuracy. Pruning can achieve a high degree of computational savings without significantly sacrificing classification accuracy. In saliency weighting, however, we found that classification performance does not improve. In addition, we present a new method to incorporate salient and non-salient regions for improved classification accuracy. We treat the salient and non-salient regions separately and combine them using Multiple Kernel Learning. We evaluate our approach using the UIUC sports dataset and find that with a small training size, our method improves upon the classification accuracy of the baseline bag of features approach.