 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Saliency Prediction Using a Mixture of Deep Neural Networks
Paper and Code
Feb 01, 2017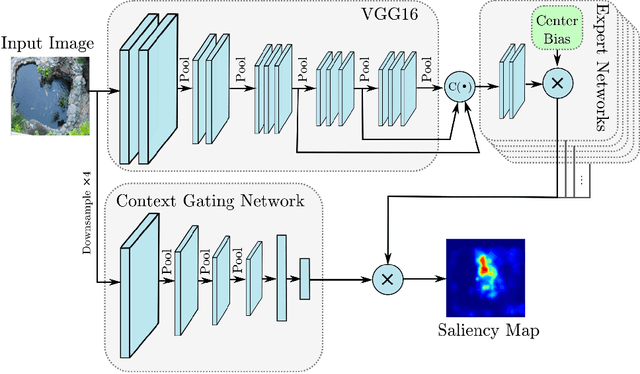
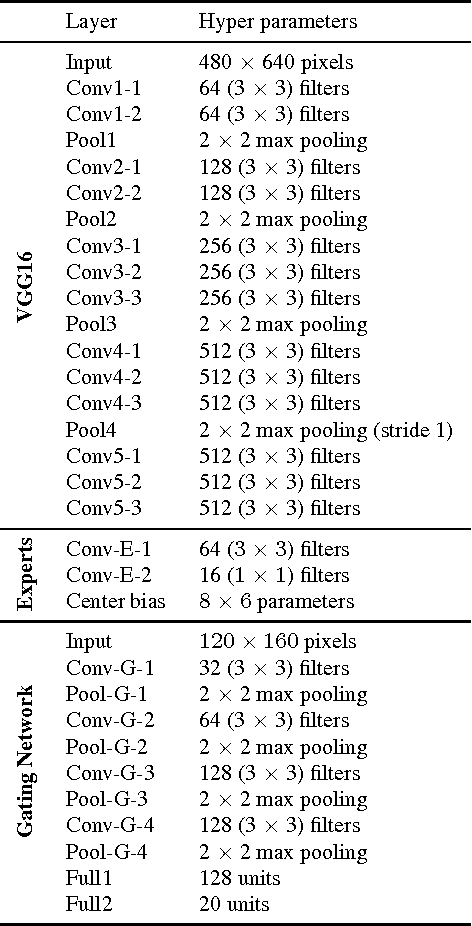

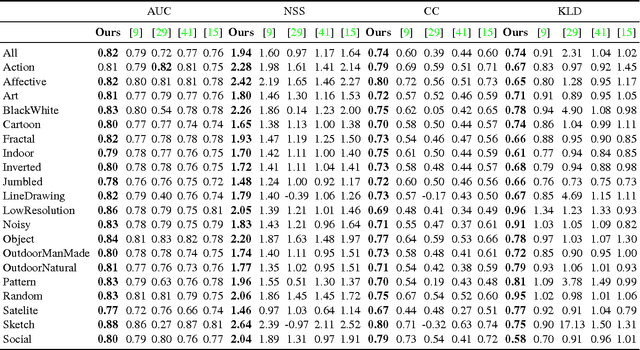
Visual saliency models have recently begun to incorporate deep learning to achieve predictive capacity much greater than previous unsupervised methods. However, most existing models predict saliency using local mechanisms limited to the receptive field of the network. We propose a model that incorporates global scene semantic information in addition to local information gathered by a convolutional neural network. Our model is formulated as a mixture of experts. Each expert network is trained to predict saliency for a set of closely related images. The final saliency map is computed as a weighted mixture of the expert networks' output, with weights determined by a separate gating network. This gating network is guided by global scene information to predict weights. The expert networks and the gating network are trained simultaneously in an end-to-end manner. We show that our mixture formulation leads to improvement in performance over an otherwise identical non-mixture model that does not incorporate global scene information.