 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised source localization in reverberant environments with deep generative modeling
Paper and Code
Jan 26, 2021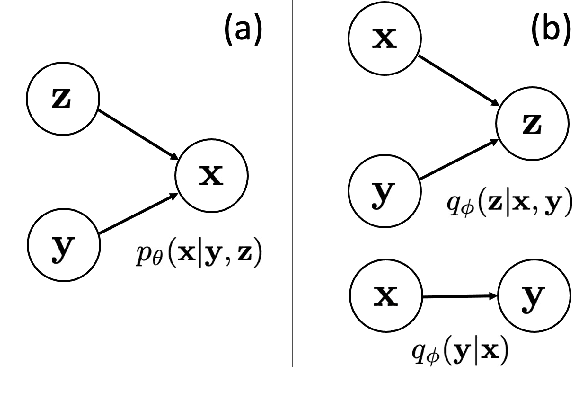
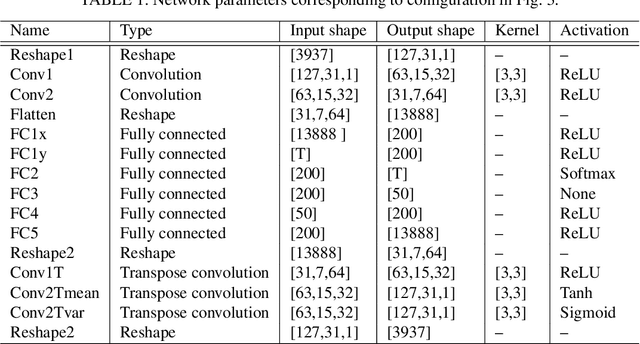

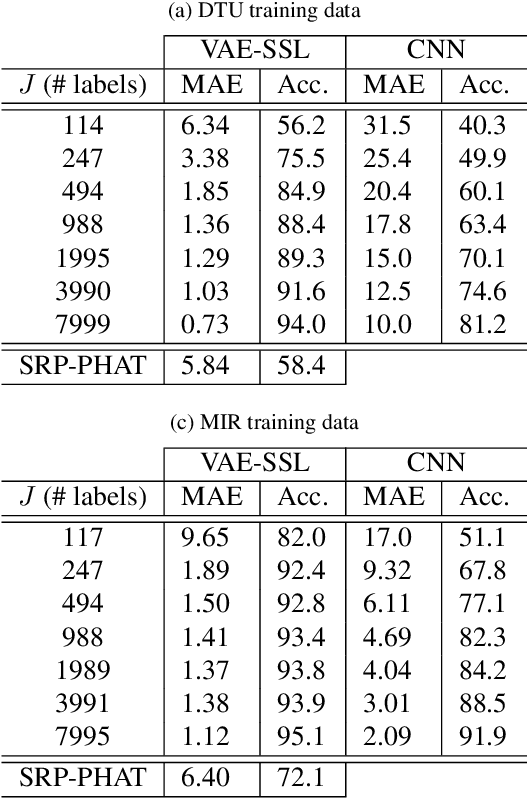
A semi-supervised approach to acoustic source localization in reverberant environments, based on deep generative modeling, is proposed. Localization in reverberant environments remains an open challenge. Even with large data volumes, the number of labels available for supervised learning in reverberant environments is usually small. We address this issue by performing semi-supervised learning (SSL) with convolutional variational autoencoders (VAEs) on speech signals in reverberant environments. The VAE is trained to generate the phase of relative transfer functions (RTFs) between microphones, in parallel with a direction of arrival (DOA) classifier based on RTF-phase, on both labeled and unlabeled RTF samples. In learning to perform these tasks, the VAE-SSL explicitly learns to separate the physical causes of the RTF-phase (i.e., source location) from distracting signal characteristics such as noise and speech activity. Relative to existing semi-supervised localization methods in acoustics, VAE-SSL is effectively an end-to-end processing approach which relies on minimal preprocessing of RTF-phase features. The VAE-SSL approach is compared with the steered response power with phase transform (SRP-PHAT) and fully supervised CNNs. We find that VAE-SSL can outperform both SRP-PHAT and CNN in label-limited scenarios. Further, the trained VAE-SSL system can generate new RTF-phase samples, which shows the VAE-SSL approach learns the physics of the acoustic environment. The generative modeling in VAE-SSL thus provides a means of interpreting the learned representations.