 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable physics for sound field reconstruction
Oct 06, 2025Sound field reconstruction involves estimating sound fields from a limited number of spatially distributed observations. This work introduces a differentiable physics approach for sound field reconstruction, where the initial conditions of the wave equation are approximated with a neural network, and the differential operator is computed with a differentiable numerical solver. The use of a numerical solver enables a stable network training while enforcing the physics as a strong constraint, in contrast to conventional physics-informed neural networks, which include the physics as a constraint in the loss function. We introduce an additional sparsity-promoting constraint to achieve meaningful solutions even under severe undersampling conditions. Experiments demonstrate that the proposed approach can reconstruct sound fields under extreme data scarcity, achieving higher accuracy and better convergence compared to physics-informed neural networks.
Morphogenesis of sound creates acoustic rainbows
Aug 27, 2024

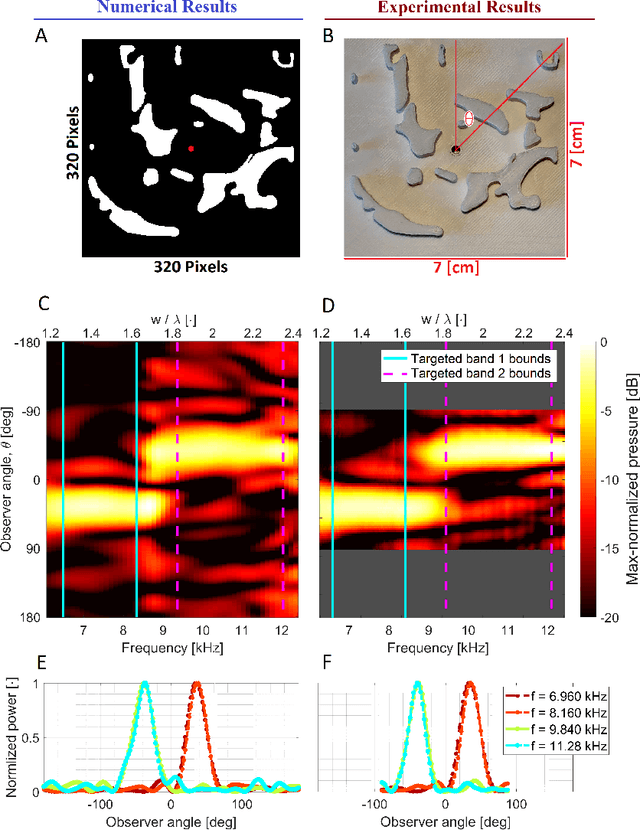

Sound is an essential sensing element for many organisms in nature, and multiple species have evolved organic structures that create complex acoustic scattering and dispersion phenomena to emit and perceive sound unambiguously. To date, it has not proven possible to design artificial scattering structures that rival the performance of those found in organic structures. Contrarily, most sound manipulation relies on active transduction in fluid media rather than relying on passive scattering principles, as are often found in nature. In this work, we utilize computational morphogenesis to synthesize complex energy-efficient wavelength-sized single-material scattering structures that passively decompose radiated sound into its spatio-spectral components. Specifically, we tailor an acoustic rainbow structure with "above unity" efficiency and an acoustic wavelength-splitter. Our work paves the way for a new frontier in sound-field engineering, with potential applications in transduction, bionics, energy harvesting, communications and sensing.
In situ sound absorption estimation with the discrete complex image source method
Apr 17, 2024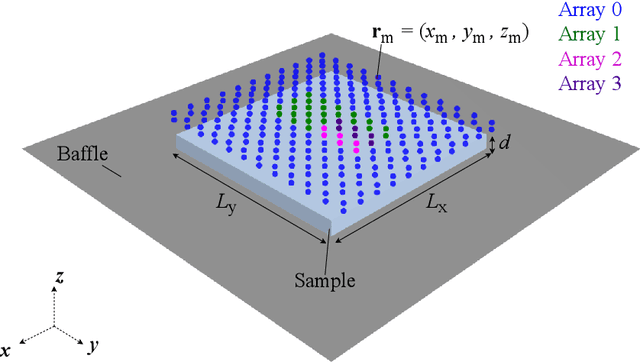
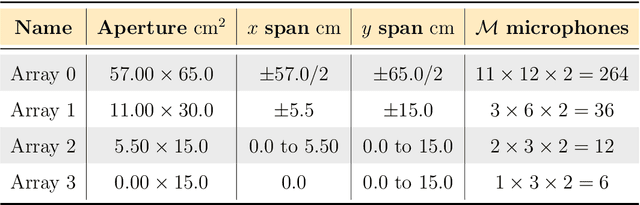
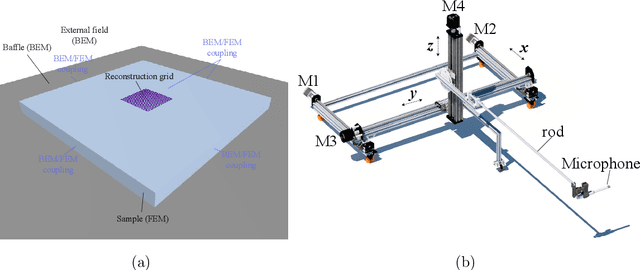

Estimating the sound absorption in situ relies on accurately describing the measured sound field. Evidence suggests that modeling the reflection of impinging spherical waves is important, especially for compact measurement systems. This article proposes a method for estimating the sound absorption coefficient of a material sample by mapping the sound pressure, measured by a microphone array, to a distribution of monopoles along a line in the complex plane. The proposed method is compared to modeling the sound field as a superposition of two sources (a monopole and an image source). The obtained inverse problems are solved with Tikhonov regularization, with automatic choice of the regularization parameter by the L-curve criterion. The sound absorption measurement is tested with simulations of the sound field above infinite and finite porous absorbers. The approaches are compared to the plane-wave absorption coefficient and the one obtained by spherical wave incidence. Experimental analysis of two porous samples and one resonant absorber is also carried out in situ. Four arrays were tested with an increasing aperture and number of sensors. It was demonstrated that measurements are feasible even with an array with only a few microphones. The discretization of the integral equation led to a more accurate reconstruction of the sound pressure and particle velocity at the sample's surface. The resulting absorption coefficient agrees with the one obtained for spherical wave incidence, indicating that including more monopoles along the complex line is an essential feature of the sound field.
Efficient Sound Field Reconstruction with Conditional Invertible Neural Networks
Apr 10, 2024In this study, we introduce a method for estimating sound fields in reverberant environments using a conditional invertible neural network (CINN). Sound field reconstruction can be hindered by experimental errors, limited spatial data, model mismatches, and long inference times, leading to potentially flawed and prolonged characterizations. Further, the complexity of managing inherent uncertainties often escalates computational demands or is neglected in models. Our approach seeks to balance accuracy and computational efficiency, while incorporating uncertainty estimates to tailor reconstructions to specific needs. By training a CINN with Monte Carlo simulations of random wave fields, our method reduces the dependency on extensive datasets and enables inference from sparse experimental data. The CINN proves versatile at reconstructing Room Impulse Responses (RIRs), by acting either as a likelihood model for maximum a posteriori estimation or as an approximate posterior distribution through amortized Bayesian inference. Compared to traditional Bayesian methods, the CINN achieves similar accuracy with greater efficiency and without requiring its adaptation to distinct sound field conditions.
Physics-Informed Neural Network for Volumetric Sound field Reconstruction of Speech Signals
Mar 14, 2024Recent developments in acoustic signal processing have seen the integration of deep learning methodologies, alongside the continued prominence of classical wave expansion-based approaches, particularly in sound field reconstruction. Physics-Informed Neural Networks (PINNs) have emerged as a novel framework, bridging the gap between data-driven and model-based techniques for addressing physical phenomena governed by partial differential equations. This paper introduces a PINN-based approach for the recovery of arbitrary volumetric acoustic fields. The network incorporates the wave equation to impose a regularization on signal reconstruction in the time domain. This methodology enables the network to learn the underlying physics of sound propagation and allows for the complete characterization of the sound field based on a limited set of observations. The proposed method's efficacy is validated through experiments involving speech signals in a real-world environment, considering varying numbers of available measurements. Moreover, a comparative analysis is undertaken against state-of-the-art frequency-domain and time-domain reconstruction methods from existing literature, highlighting the increased accuracy across the various measurement configurations.
Room impulse response reconstruction with physics-informed deep learning
Jan 02, 2024


A method is presented for estimating and reconstructing the sound field within a room using physics-informed neural networks. By incorporating a limited set of experimental room impulse responses as training data, this approach combines neural network processing capabilities with the underlying physics of sound propagation, as articulated by the wave equation. The network's ability to estimate particle velocity and intensity, in addition to sound pressure, demonstrates its capacity to represent the flow of acoustic energy and completely characterise the sound field with only a few measurements. Additionally, an investigation into the potential of this network as a tool for improving acoustic simulations is conducted. This is due to its profficiency in offering grid-free sound field mappings with minimal inference time. Furthermore, a study is carried out which encompasses comparative analyses against current approaches for sound field reconstruction. Specifically, the proposed approach is evaluated against both data-driven techniques and elementary wave-based regression methods. The results demonstrate that the physics-informed neural network stands out when reconstructing the early part of the room impulse response, while simultaneously allowing for complete sound field characterisation in the time domain.
Generative adversarial networks with physical sound field priors
Aug 01, 2023This paper presents a deep learning-based approach for the spatio-temporal reconstruction of sound fields using Generative Adversarial Networks (GANs). The method utilises a plane wave basis and learns the underlying statistical distributions of pressure in rooms to accurately reconstruct sound fields from a limited number of measurements. The performance of the method is evaluated using two established datasets and compared to state-of-the-art methods. The results show that the model is able to achieve an improved reconstruction performance in terms of accuracy and energy retention, particularly in the high-frequency range and when extrapolating beyond the measurement region. Furthermore, the proposed method can handle a varying number of measurement positions and configurations without sacrificing performance. The results suggest that this approach provides a promising approach to sound field reconstruction using generative models that allow for a physically informed prior to acoustics problems.
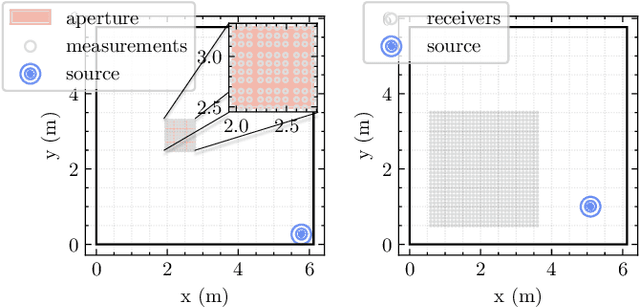
A convolutional plane wave model for sound field reconstruction
Aug 24, 2022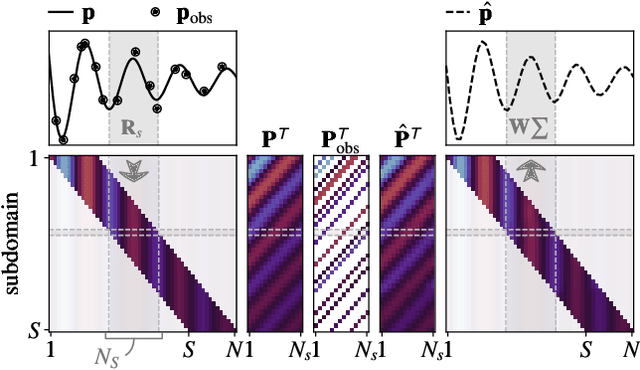
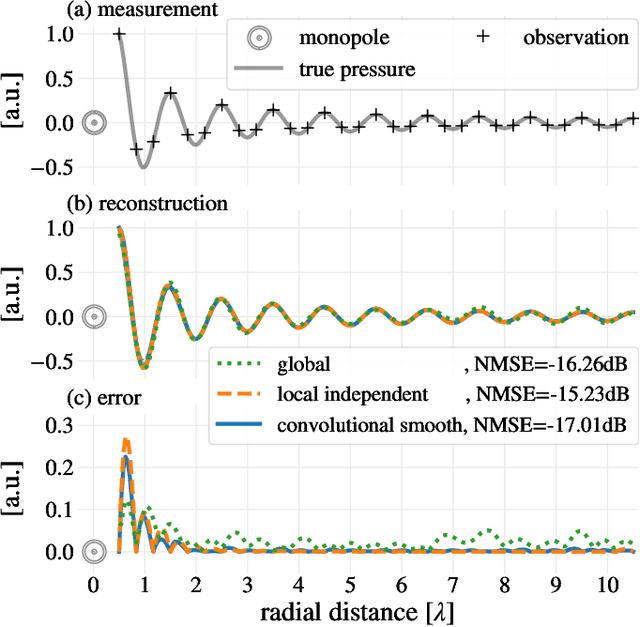
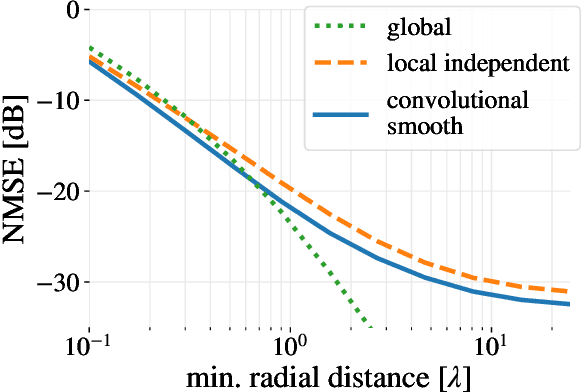
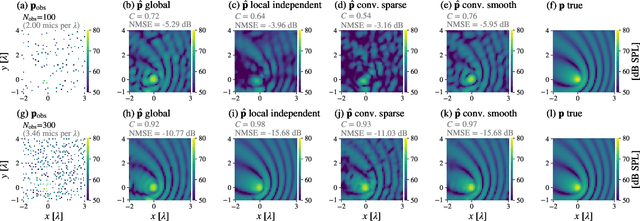
Spatial sound field interpolation relies on suitable models to both conform to available measurements and predict the sound field in the domain of interest. A suitable model can be difficult to determine when the spatial domain of interest is large compared to the wavelength or when spherical and planar wavefronts are present or the sound field is complex, as in the near-field. To span such complex sound fields, the global reconstruction task can be partitioned into local subdomain problems. Previous studies have shown that partitioning approaches rely on sufficient measurements within each domain, due to the higher number of model coefficients. This study proposes a joint analysis of all local subdomains, while enforcing self-similarity between neighbouring partitions. More specifically, the coefficients of local plane wave representations are sought to have spatially smooth magnitudes. A convolutional model of the sound field in terms of plane wave filters is formulated and the inverse reconstruction problem is solved via the alternating direction method of multipliers. The experiments on simulated and measured sound fields suggest, that the proposed method both retains the flexibility of local models to conform to complex sound fields and also preserves the global structure to reconstruct from fewer measurements.
Semi-supervised source localization in reverberant environments with deep generative modeling
Jan 26, 2021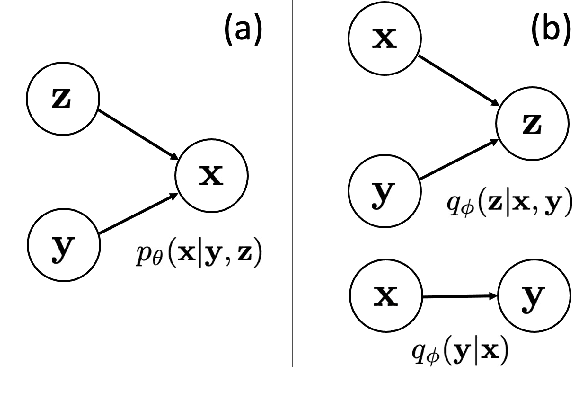
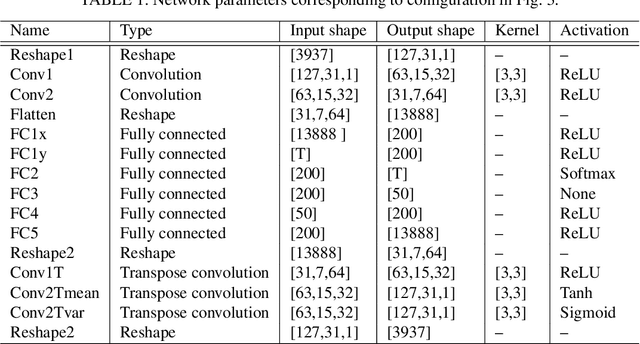

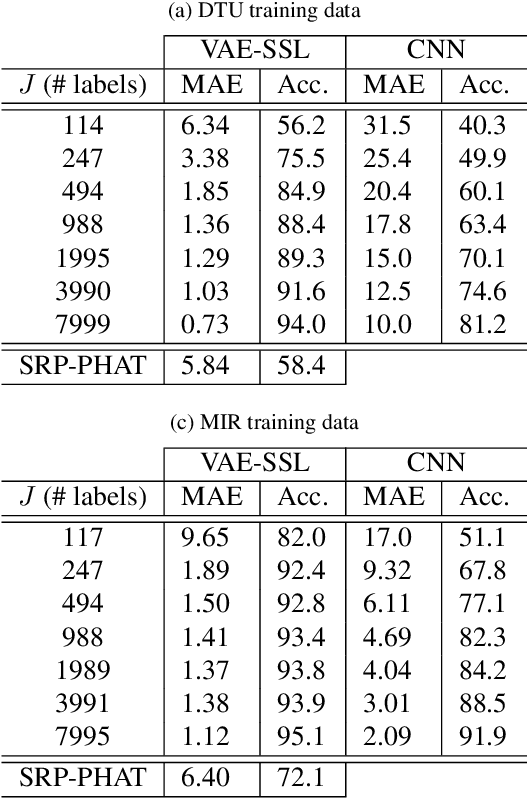
A semi-supervised approach to acoustic source localization in reverberant environments, based on deep generative modeling, is proposed. Localization in reverberant environments remains an open challenge. Even with large data volumes, the number of labels available for supervised learning in reverberant environments is usually small. We address this issue by performing semi-supervised learning (SSL) with convolutional variational autoencoders (VAEs) on speech signals in reverberant environments. The VAE is trained to generate the phase of relative transfer functions (RTFs) between microphones, in parallel with a direction of arrival (DOA) classifier based on RTF-phase, on both labeled and unlabeled RTF samples. In learning to perform these tasks, the VAE-SSL explicitly learns to separate the physical causes of the RTF-phase (i.e., source location) from distracting signal characteristics such as noise and speech activity. Relative to existing semi-supervised localization methods in acoustics, VAE-SSL is effectively an end-to-end processing approach which relies on minimal preprocessing of RTF-phase features. The VAE-SSL approach is compared with the steered response power with phase transform (SRP-PHAT) and fully supervised CNNs. We find that VAE-SSL can outperform both SRP-PHAT and CNN in label-limited scenarios. Further, the trained VAE-SSL system can generate new RTF-phase samples, which shows the VAE-SSL approach learns the physics of the acoustic environment. The generative modeling in VAE-SSL thus provides a means of interpreting the learned representations.