 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Neural Network-Driven Sparse Field Discretization Method for Near-Field Acoustic Holography
May 01, 2025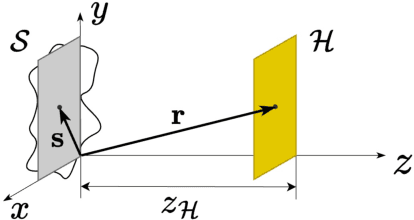
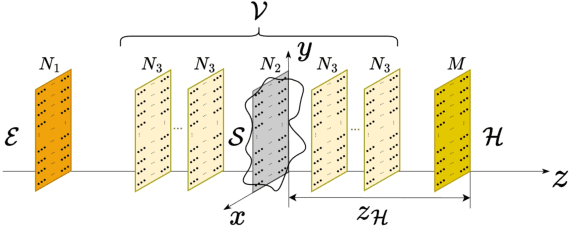
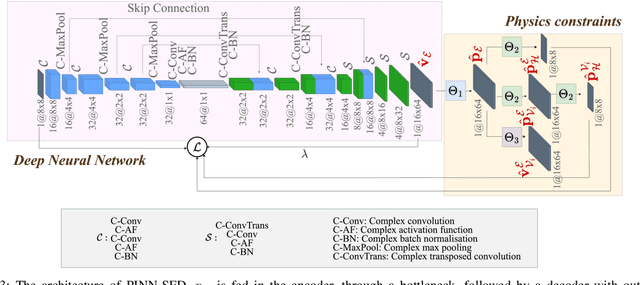
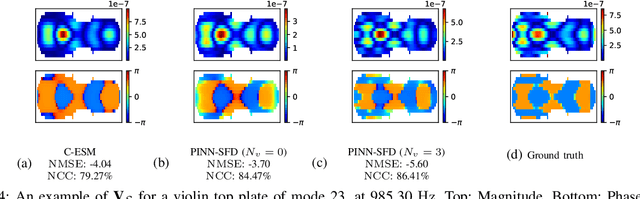
We propose the Physics-Informed Neural Network-driven Sparse Field Discretization method (PINN-SFD), a novel self-supervised, physics-informed deep learning approach for addressing the Near-Field Acoustic Holography (NAH) problem. Unlike existing deep learning methods for NAH, which are predominantly supervised by large datasets, our approach does not require a training phase and it is physics-informed. The wave propagation field is discretized into sparse regions, a process referred to as field discretization, which includes a series of set of source planes, to address the inverse problem. Our method employs the discretized Kirchhoff-Helmholtz integral as the wave propagation model. By incorporating virtual planes, additional constraints are enforced near the actual sound source, improving the reconstruction process. Optimization is carried out using Physics-Informed Neural Networks (PINNs), where physics-based constraints are integrated into the loss functions to account for both direct (from equivalent source plane to hologram plane) and additional (from virtual planes to hologram plane) wave propagation paths. Additionally, sparsity is enforced on the velocity of the equivalent sources. Our comprehensive validation across various rectangular and violin top plates, covering a wide range of vibrational modes, demonstrates that PINN-SFD consistently outperforms the conventional Compressive-Equivalent Source Method (C-ESM), particularly in terms of reconstruction accuracy for complex vibrational patterns. Significantly, this method demonstrates reduced sensitivity to regularization parameters compared to C-ESM.
A Zero-Shot Physics-Informed Dictionary Learning Approach for Sound Field Reconstruction
Dec 24, 2024


Sound field reconstruction aims to estimate pressure fields in areas lacking direct measurements. Existing techniques often rely on strong assumptions or face challenges related to data availability or the explicit modeling of physical properties. To bridge these gaps, this study introduces a zero-shot, physics-informed dictionary learning approach to perform sound field reconstruction. Our method relies only on a few sparse measurements to learn a dictionary, without the need for additional training data. Moreover, by enforcing the Helmholtz equation during the optimization process, the proposed approach ensures that the reconstructed sound field is represented as a linear combination of a few physically meaningful atoms. Evaluations on real-world data show that our approach achieves comparable performance to state-of-the-art dictionary learning techniques, with the advantage of requiring only a few observations of the sound field and no training on a dataset.
A Physics-Informed Neural Network-Based Approach for the Spatial Upsampling of Spherical Microphone Arrays
Jul 26, 2024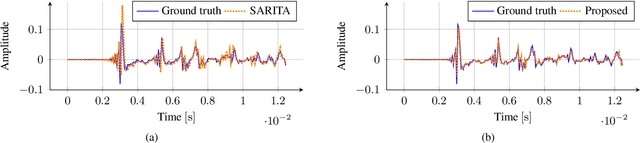
Spherical microphone arrays are convenient tools for capturing the spatial characteristics of a sound field. However, achieving superior spatial resolution requires arrays with numerous capsules, consequently leading to expensive devices. To address this issue, we present a method for spatially upsampling spherical microphone arrays with a limited number of capsules. Our approach exploits a physics-informed neural network with Rowdy activation functions, leveraging physical constraints to provide high-order microphone array signals, starting from low-order devices. Results show that, within its domain of application, our approach outperforms a state of the art method based on signal processing for spherical microphone arrays upsampling.
Interpreting End-to-End Deep Learning Models for Speech Source Localization Using Layer-wise Relevance Propagation
Apr 04, 2024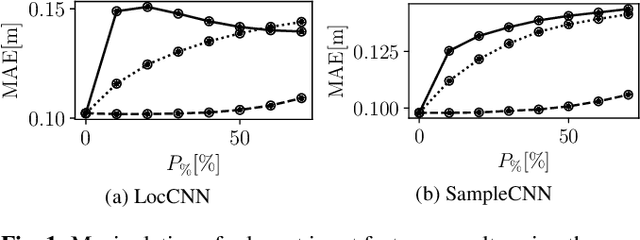



Deep learning models are widely applied in the signal processing community, yet their inner working procedure is often treated as a black box. In this paper, we investigate the use of eXplainable Artificial Intelligence (XAI) techniques to learning-based end-to-end speech source localization models. We consider the Layer-wise Relevance Propagation (LRP) technique, which aims to determine which parts of the input are more important for the output prediction. Using LRP we analyze two state-of-the-art models, of differing architectural complexity that map audio signals acquired by the microphones to the cartesian coordinates of the source. Specifically, we inspect the relevance associated with the input features of the two models and discover that both networks denoise and de-reverberate the microphone signals to compute more accurate statistical correlations between them and consequently localize the sources. To further demonstrate this fact, we estimate the Time-Difference of Arrivals (TDoAs) via the Generalized Cross Correlation with Phase Transform (GCC-PHAT) using both microphone signals and relevance signals extracted from the two networks and show that through the latter we obtain more accurate time-delay estimation results.
Physics-Informed Neural Network for Volumetric Sound field Reconstruction of Speech Signals
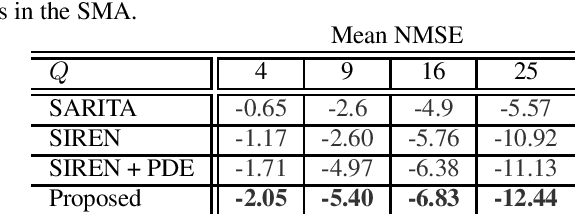
Mar 14, 2024Recent developments in acoustic signal processing have seen the integration of deep learning methodologies, alongside the continued prominence of classical wave expansion-based approaches, particularly in sound field reconstruction. Physics-Informed Neural Networks (PINNs) have emerged as a novel framework, bridging the gap between data-driven and model-based techniques for addressing physical phenomena governed by partial differential equations. This paper introduces a PINN-based approach for the recovery of arbitrary volumetric acoustic fields. The network incorporates the wave equation to impose a regularization on signal reconstruction in the time domain. This methodology enables the network to learn the underlying physics of sound propagation and allows for the complete characterization of the sound field based on a limited set of observations. The proposed method's efficacy is validated through experiments involving speech signals in a real-world environment, considering varying numbers of available measurements. Moreover, a comparative analysis is undertaken against state-of-the-art frequency-domain and time-domain reconstruction methods from existing literature, highlighting the increased accuracy across the various measurement configurations.
HOMULA-RIR: A Room Impulse Response Dataset for Teleconferencing and Spatial Audio Applications Acquired Through Higher-Order Microphones and Uniform Linear Microphone Arrays
Feb 21, 2024
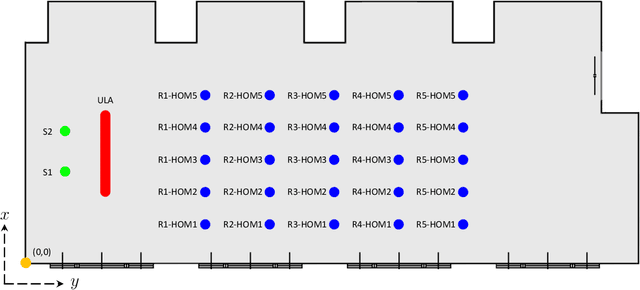
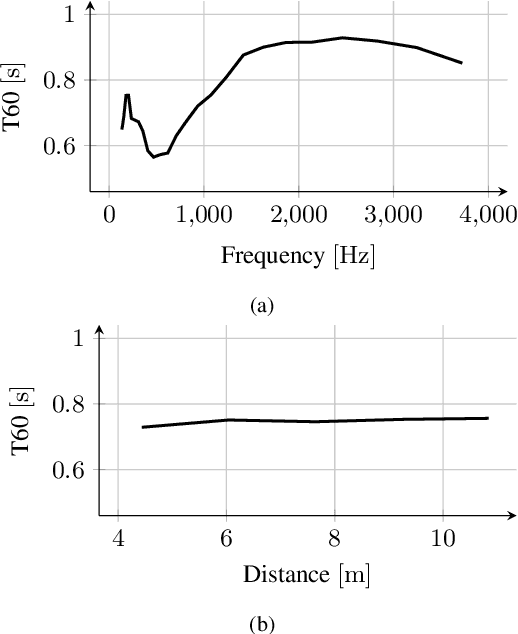
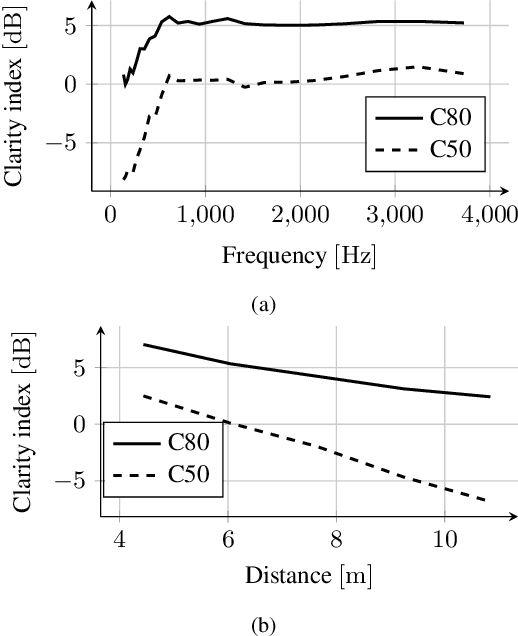
In this paper, we present HOMULA-RIR, a dataset of room impulse responses (RIRs) acquired using both higher-order microphones (HOMs) and a uniform linear array (ULA), in order to model a remote attendance teleconferencing scenario. Specifically, measurements were performed in a seminar room, where a 64-microphone ULA was used as a multichannel audio acquisition system in the proximity of the speakers, while HOMs were used to model 25 attendees actually present in the seminar room. The HOMs cover a wide area of the room, making the dataset suitable also for applications of virtual acoustics. Through the measurement of the reverberation time and clarity index, and sample applications such as source localization and separation, we demonstrate the effectiveness of the HOMULA-RIR dataset.
Room transfer function reconstruction using complex-valued neural networks and irregularly distributed microphones
Feb 01, 2024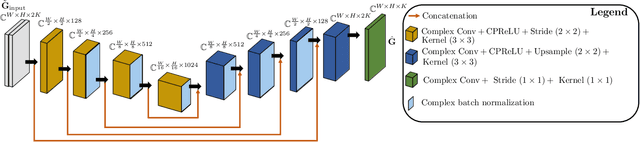
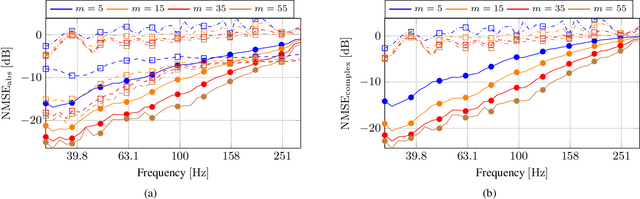
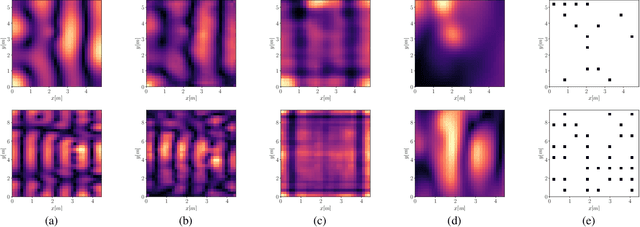
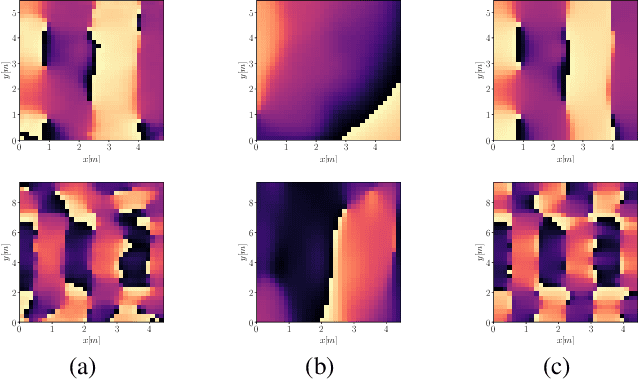
Reconstructing the room transfer functions needed to calculate the complex sound field in a room has several important real-world applications. However, an unpractical number of microphones is often required. Recently, in addition to classical signal processing methods, deep learning techniques have been applied to reconstruct the room transfer function starting from a very limited set of room transfer functions measured at scattered points in the room. In this study, we employ complex-valued neural networks to estimate room transfer functions in the frequency range of the first room resonances, using a few irregularly distributed microphones. To the best of our knowledge, this is the first time complex-valued neural networks are used to estimate room transfer functions. To analyze the benefits of applying complex-valued optimization to the considered task, we compare the proposed technique with a state-of-the-art real-valued neural network method and a state-of-the-art kernel-based signal processing approach for sound field reconstruction, showing that the proposed technique exhibits relevant advantages in terms of phase accuracy and overall quality of the reconstructed sound field.
Toward Deep Drum Source Separation
Dec 15, 2023
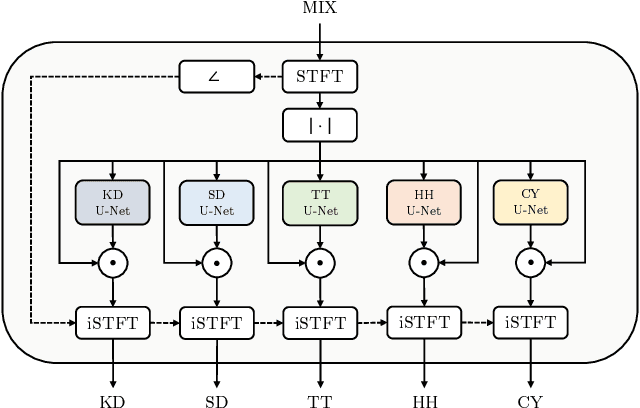
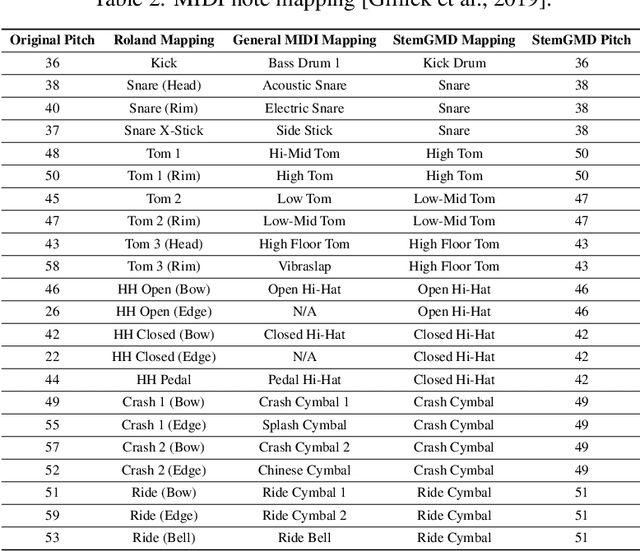
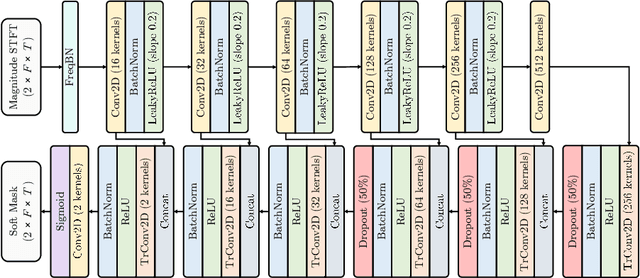
In the past, the field of drum source separation faced significant challenges due to limited data availability, hindering the adoption of cutting-edge deep learning methods that have found success in other related audio applications. In this manuscript, we introduce StemGMD, a large-scale audio dataset of isolated single-instrument drum stems. Each audio clip is synthesized from MIDI recordings of expressive drums performances using ten real-sounding acoustic drum kits. Totaling 1224 hours, StemGMD is the largest audio dataset of drums to date and the first to comprise isolated audio clips for every instrument in a canonical nine-piece drum kit. We leverage StemGMD to develop LarsNet, a novel deep drum source separation model. Through a bank of dedicated U-Nets, LarsNet can separate five stems from a stereo drum mixture faster than real-time and is shown to significantly outperform state-of-the-art nonnegative spectro-temporal factorization methods.
Reconstruction of Sound Field through Diffusion Models
Dec 14, 2023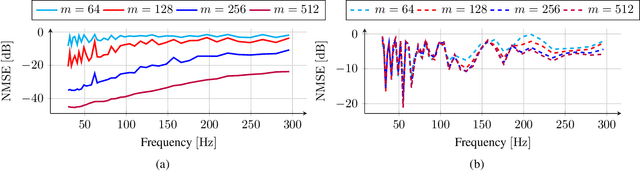

Reconstructing the sound field in a room is an important task for several applications, such as sound control and augmented (AR) or virtual reality (VR). In this paper, we propose a data-driven generative model for reconstructing the magnitude of acoustic fields in rooms with a focus on the modal frequency range. We introduce, for the first time, the use of a conditional Denoising Diffusion Probabilistic Model (DDPM) trained in order to reconstruct the sound field (SF-Diff) over an extended domain. The architecture is devised in order to be conditioned on a set of limited available measurements at different frequencies and generate the sound field in target, unknown, locations. The results show that SF-Diff is able to provide accurate reconstructions, outperforming a state-of-the-art baseline based on kernel interpolation.
Timbre transfer using image-to-image denoising diffusion implicit models
Jul 28, 2023
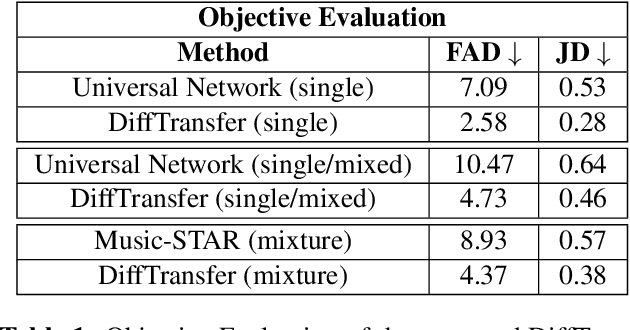
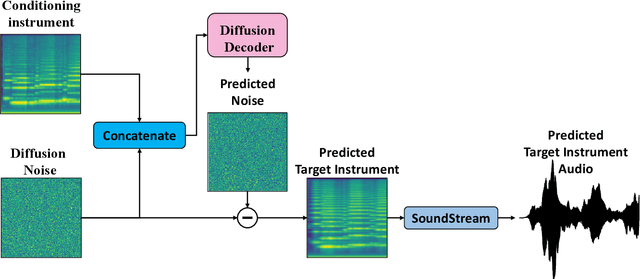

Timbre transfer techniques aim at converting the sound of a musical piece generated by one instrument into the same one as if it was played by another instrument, while maintaining as much as possible the content in terms of musical characteristics such as melody and dynamics. Following their recent breakthroughs in deep learning-based generation, we apply Denoising Diffusion Models (DDMs) to perform timbre transfer. Specifically, we apply the recently proposed Denoising Diffusion Implicit Models (DDIMs) that enable to accelerate the sampling procedure. Inspired by the recent application of DDMs to image translation problems we formulate the timbre transfer task similarly, by first converting the audio tracks into log mel spectrograms and by conditioning the generation of the desired timbre spectrogram through the input timbre spectrogram. We perform both one-to-one and many-to-many timbre transfer, by converting audio waveforms containing only single instruments and multiple instruments, respectively. We compare the proposed technique with existing state-of-the-art methods both through listening tests and objective measures in order to demonstrate the effectiveness of the proposed model.