 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating data replication in text-to-audio generative diffusion models through anti-memorization guidance
Sep 18, 2025A persistent challenge in generative audio models is data replication, where the model unintentionally generates parts of its training data during inference. In this work, we address this issue in text-to-audio diffusion models by exploring the use of anti-memorization strategies. We adopt Anti-Memorization Guidance (AMG), a technique that modifies the sampling process of pre-trained diffusion models to discourage memorization. Our study explores three types of guidance within AMG, each designed to reduce replication while preserving generation quality. We use Stable Audio Open as our backbone, leveraging its fully open-source architecture and training dataset. Our comprehensive experimental analysis suggests that AMG significantly mitigates memorization in diffusion-based text-to-audio generation without compromising audio fidelity or semantic alignment.
Diffused Responsibility: Analyzing the Energy Consumption of Generative Text-to-Audio Diffusion Models
May 12, 2025


Text-to-audio models have recently emerged as a powerful technology for generating sound from textual descriptions. However, their high computational demands raise concerns about energy consumption and environmental impact. In this paper, we conduct an analysis of the energy usage of 7 state-of-the-art text-to-audio diffusion-based generative models, evaluating to what extent variations in generation parameters affect energy consumption at inference time. We also aim to identify an optimal balance between audio quality and energy consumption by considering Pareto-optimal solutions across all selected models. Our findings provide insights into the trade-offs between performance and environmental impact, contributing to the development of more efficient generative audio models.
Mind the Prompt: Prompting Strategies in Audio Generations for Improving Sound Classification
Apr 04, 2025



This paper investigates the design of effective prompt strategies for generating realistic datasets using Text-To-Audio (TTA) models. We also analyze different techniques for efficiently combining these datasets to enhance their utility in sound classification tasks. By evaluating two sound classification datasets with two TTA models, we apply a range of prompt strategies. Our findings reveal that task-specific prompt strategies significantly outperform basic prompt approaches in data generation. Furthermore, merging datasets generated using different TTA models proves to enhance classification performance more effectively than merely increasing the training dataset size. Overall, our results underscore the advantages of these methods as effective data augmentation techniques using synthetic data.
MambaFoley: Foley Sound Generation using Selective State-Space Models
Sep 13, 2024



Recent advancements in deep learning have led to widespread use of techniques for audio content generation, notably employing Denoising Diffusion Probabilistic Models (DDPM) across various tasks. Among these, Foley Sound Synthesis is of particular interest for its role in applications for the creation of multimedia content. Given the temporal-dependent nature of sound, it is crucial to design generative models that can effectively handle the sequential modeling of audio samples. Selective State Space Models (SSMs) have recently been proposed as a valid alternative to previously proposed techniques, demonstrating competitive performance with lower computational complexity. In this paper, we introduce MambaFoley, a diffusion-based model that, to the best of our knowledge, is the first to leverage the recently proposed SSM known as Mamba for the Foley sound generation task. To evaluate the effectiveness of the proposed method, we compare it with a state-of-the-art Foley sound generative model using both objective and subjective analyses.
PAGURI: a user experience study of creative interaction with text-to-music models
Jul 05, 2024


In recent years, text-to-music models have been the biggest breakthrough in automatic music generation. While they are unquestionably a showcase of technological progress, it is not clear yet how they can be realistically integrated into the artistic practice of musicians and music practitioners. This paper aims to address this question via Prompt Audio Generation User Research Investigation (PAGURI), a user experience study where we leverage recent text-to-music developments to study how musicians and practitioners interact with these systems, evaluating their satisfaction levels. We developed an online tool through which users can generate music samples and/or apply recently proposed personalization techniques, based on fine-tuning, to make the text-to-music model generate sounds closer to their needs and preferences. Using questionnaires, we analyzed how participants interacted with the proposed tool, to understand the effectiveness of text-to-music models in enhancing users' creativity. Results show that even if the audio samples generated and their quality may not always meet user expectations, the majority of the participants would incorporate the tool in their creative process. Furthermore, they provided insights into potential enhancements for the system and its integration into their music practice.
Synthesizing Soundscapes: Leveraging Text-to-Audio Models for Environmental Sound Classification
Mar 26, 2024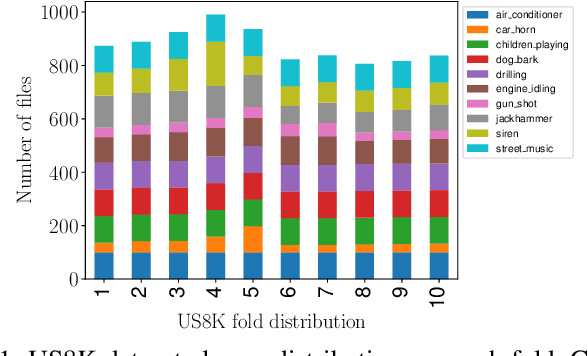
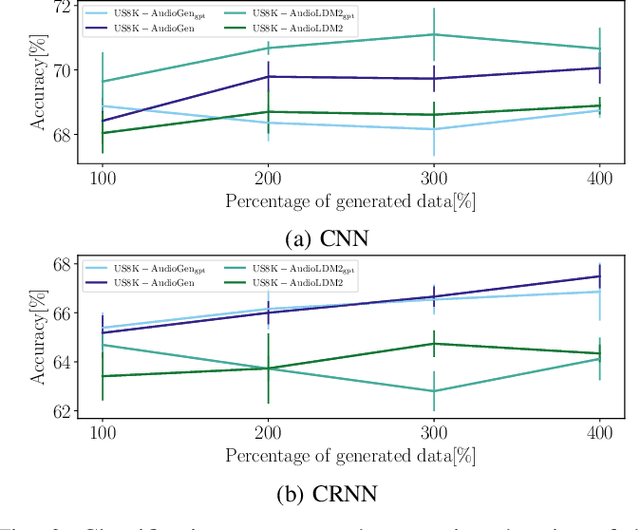
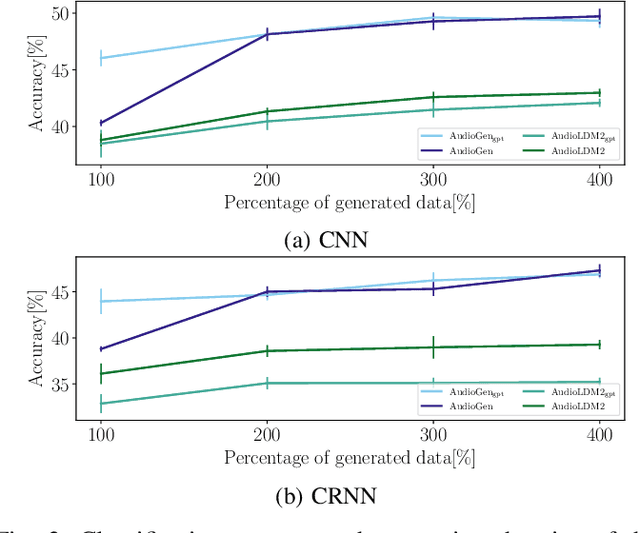
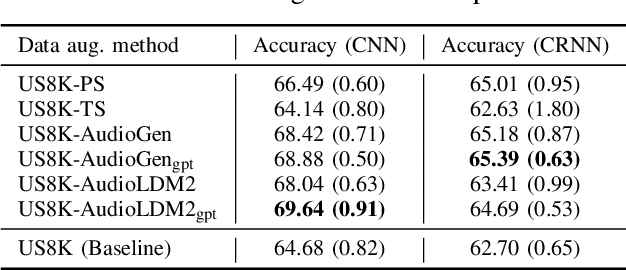
In the past few years, text-to-audio models have emerged as a significant advancement in automatic audio generation. Although they represent impressive technological progress, the effectiveness of their use in the development of audio applications remains uncertain. This paper aims to investigate these aspects, specifically focusing on the task of classification of environmental sounds. This study analyzes the performance of two different environmental classification systems when data generated from text-to-audio models is used for training. Two cases are considered: a) when the training dataset is augmented by data coming from two different text-to-audio models; and b) when the training dataset consists solely of synthetic audio generated. In both cases, the performance of the classification task is tested on real data. Results indicate that text-to-audio models are effective for dataset augmentation, whereas the performance of the models drops when relying on only generated audio.
Room transfer function reconstruction using complex-valued neural networks and irregularly distributed microphones
Feb 01, 2024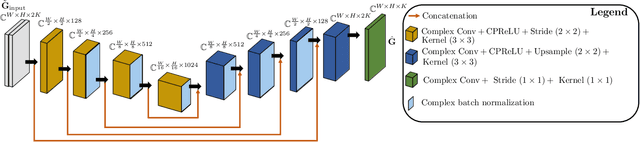
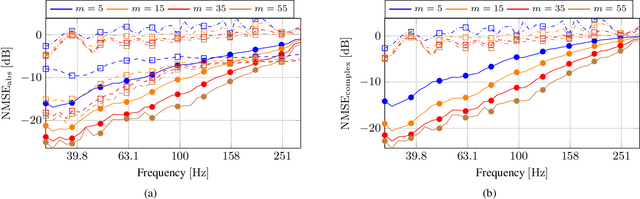
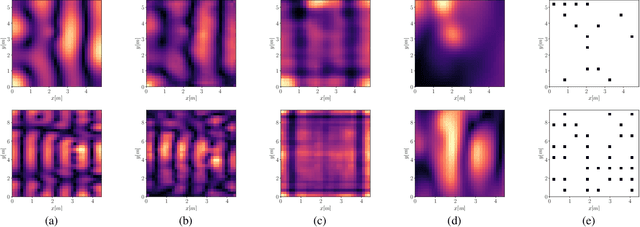
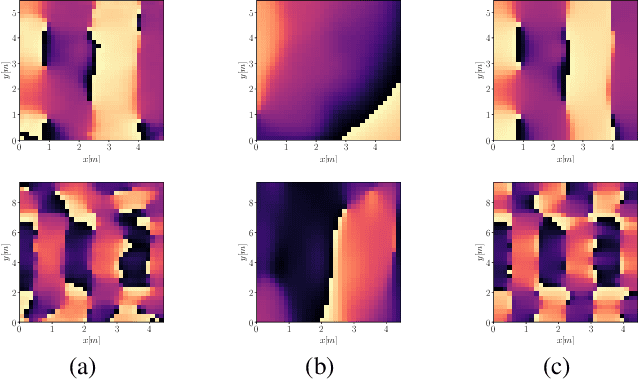
Reconstructing the room transfer functions needed to calculate the complex sound field in a room has several important real-world applications. However, an unpractical number of microphones is often required. Recently, in addition to classical signal processing methods, deep learning techniques have been applied to reconstruct the room transfer function starting from a very limited set of room transfer functions measured at scattered points in the room. In this study, we employ complex-valued neural networks to estimate room transfer functions in the frequency range of the first room resonances, using a few irregularly distributed microphones. To the best of our knowledge, this is the first time complex-valued neural networks are used to estimate room transfer functions. To analyze the benefits of applying complex-valued optimization to the considered task, we compare the proposed technique with a state-of-the-art real-valued neural network method and a state-of-the-art kernel-based signal processing approach for sound field reconstruction, showing that the proposed technique exhibits relevant advantages in terms of phase accuracy and overall quality of the reconstructed sound field.
Performance and energy balance: a comprehensive study of state-of-the-art sound event detection systems
Oct 05, 2023



In recent years, deep learning systems have shown a concerning trend toward increased complexity and higher energy consumption. As researchers in this domain and organizers of one of the Detection and Classification of Acoustic Scenes and Events challenges tasks, we recognize the importance of addressing the environmental impact of data-driven SED systems. In this paper, we propose an analysis focused on SED systems based on the challenge submissions. This includes a comparison across the past two years and a detailed analysis of this year's SED systems. Through this research, we aim to explore how the SED systems are evolving every year in relation to their energy efficiency implications.
Description and analysis of novelties introduced in DCASE Task 4 2022 on the baseline system
Oct 14, 2022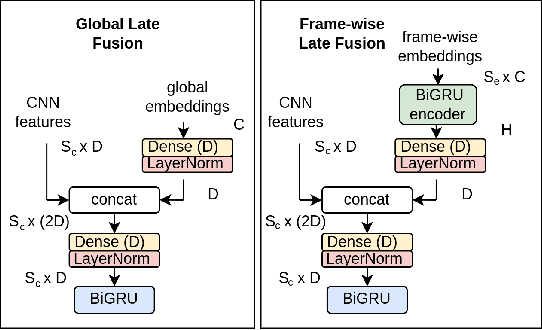
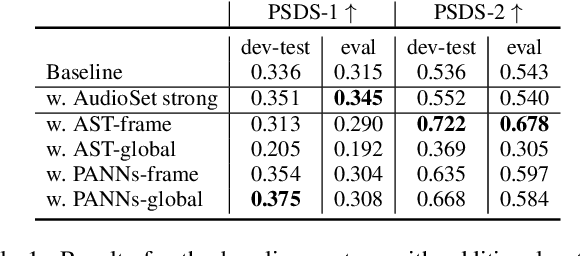
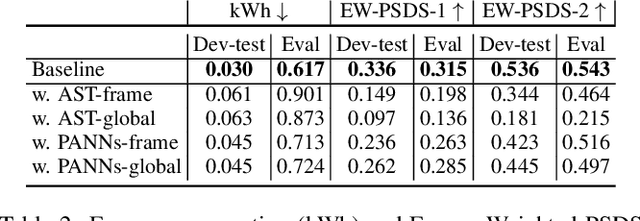
The aim of the Detection and Classification of Acoustic Scenes and Events Challenge Task 4 is to evaluate systems for the detection of sound events in domestic environments using an heterogeneous dataset. The systems need to be able to correctly detect the sound events present in a recorded audio clip, as well as localize the events in time. This year's task is a follow-up of DCASE 2021 Task 4, with some important novelties. The goal of this paper is to describe and motivate these new additions, and report an analysis of their impact on the baseline system. We introduced three main novelties: the use of external datasets, including recently released strongly annotated clips from Audioset, the possibility of leveraging pre-trained models, and a new energy consumption metric to raise awareness about the ecological impact of training sound events detectors. The results on the baseline system show that leveraging open-source pretrained on AudioSet improves the results significantly in terms of event classification but not in terms of event segmentation.
A benchmark of state-of-the-art sound event detection systems evaluated on synthetic soundscapes
Feb 08, 2022
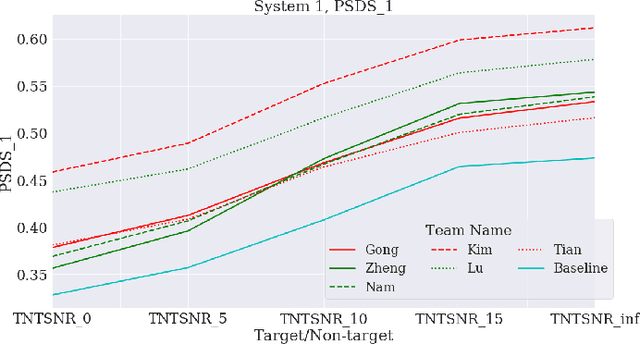

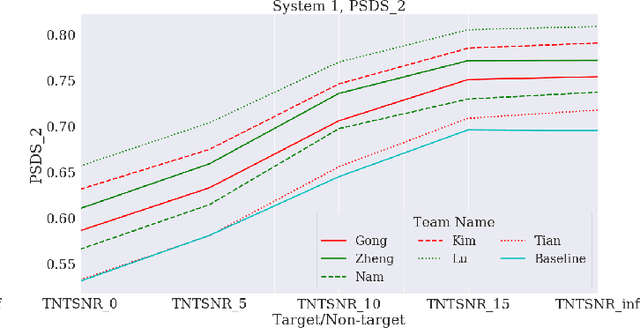
This paper proposes a benchmark of submissions to Detection and Classification Acoustic Scene and Events 2021 Challenge (DCASE) Task 4 representing a sampling of the state-of-the-art in Sound Event Detection task. The submissions are evaluated according to the two polyphonic sound detection score scenarios proposed for the DCASE 2021 Challenge Task 4, which allow to make an analysis on whether submissions are designed to perform fine-grained temporal segmentation, coarse-grained temporal segmentation, or have been designed to be polyvalent on the scenarios proposed. We study the solutions proposed by participants to analyze their robustness to varying level target to non-target signal-to-noise ratio and to temporal localization of target sound events. A last experiment is proposed in order to study the impact of non-target events on systems outputs. Results show that systems adapted to provide coarse segmentation outputs are more robust to different target to non-target signal-to-noise ratio and, with the help of specific data augmentation methods, they are more robust to time localization of the original event. Results of the last experiment display that systems tend to spuriously predict short events when non-target events are present. This is particularly true for systems that are tailored to have a fine segmentation.