 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Soundscapes: Leveraging Text-to-Audio Models for Environmental Sound Classification
Paper and Code
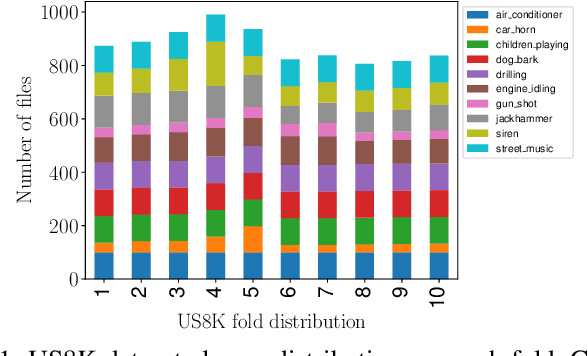
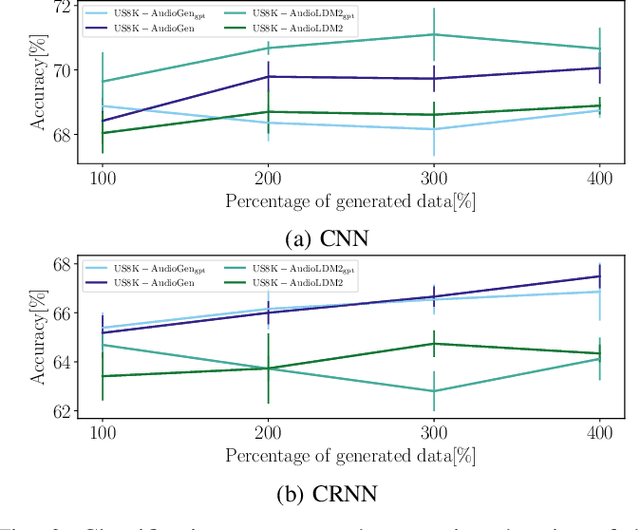
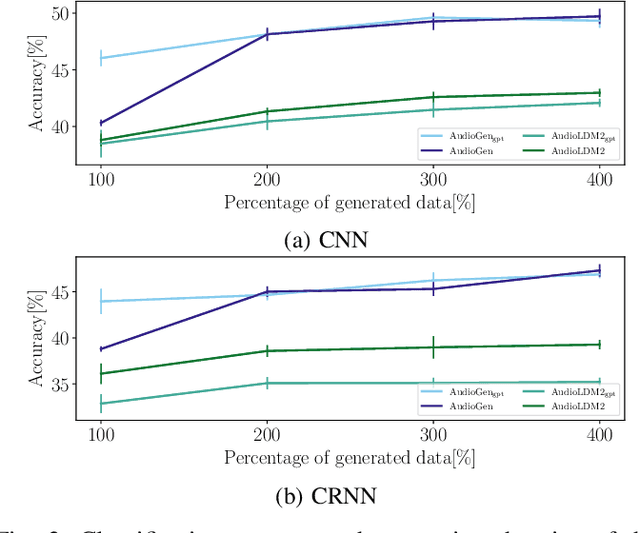
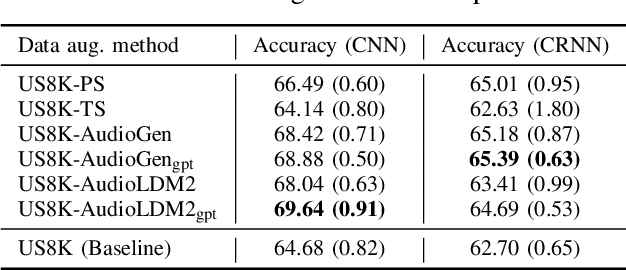
In the past few years, text-to-audio models have emerged as a significant advancement in automatic audio generation. Although they represent impressive technological progress, the effectiveness of their use in the development of audio applications remains uncertain. This paper aims to investigate these aspects, specifically focusing on the task of classification of environmental sounds. This study analyzes the performance of two different environmental classification systems when data generated from text-to-audio models is used for training. Two cases are considered: a) when the training dataset is augmented by data coming from two different text-to-audio models; and b) when the training dataset consists solely of synthetic audio generated. In both cases, the performance of the classification task is tested on real data. Results indicate that text-to-audio models are effective for dataset augmentation, whereas the performance of the models drops when relying on only generated audio.