 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Tongue Delineation from MRI Images with a Convolutional Neural Network Approach
Dec 06, 2024Tongue contour extraction from real-time magnetic resonance images is a nontrivial task due to the presence of artifacts manifesting in form of blurring or ghostly contours. In this work, we present results of automatic tongue delineation achieved by means of U-Net auto-encoder convolutional neural network. We present both intra- and inter-subject validation. We used real-time magnetic resonance images and manually annotated 1-pixel wide contours as inputs. Predicted probability maps were post-processed in order to obtain 1-pixel wide tongue contours. The results are very good and slightly outperform published results on automatic tongue segmentation.
Description and analysis of novelties introduced in DCASE Task 4 2022 on the baseline system
Oct 14, 2022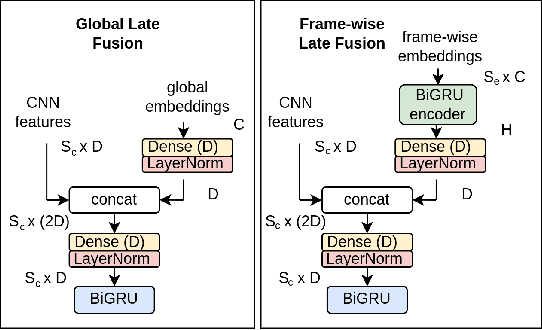
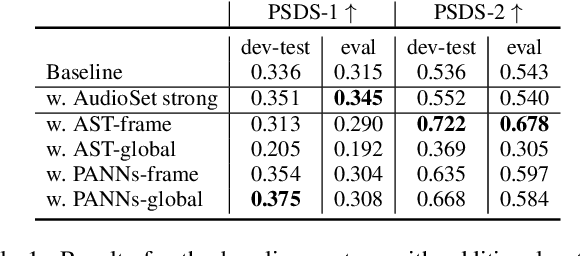
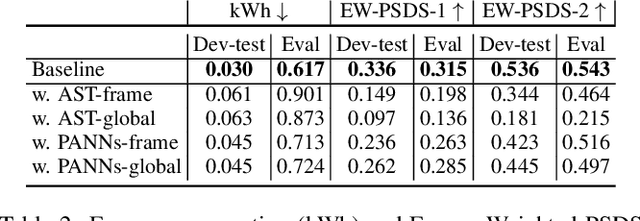
The aim of the Detection and Classification of Acoustic Scenes and Events Challenge Task 4 is to evaluate systems for the detection of sound events in domestic environments using an heterogeneous dataset. The systems need to be able to correctly detect the sound events present in a recorded audio clip, as well as localize the events in time. This year's task is a follow-up of DCASE 2021 Task 4, with some important novelties. The goal of this paper is to describe and motivate these new additions, and report an analysis of their impact on the baseline system. We introduced three main novelties: the use of external datasets, including recently released strongly annotated clips from Audioset, the possibility of leveraging pre-trained models, and a new energy consumption metric to raise awareness about the ecological impact of training sound events detectors. The results on the baseline system show that leveraging open-source pretrained on AudioSet improves the results significantly in terms of event classification but not in terms of event segmentation.
The impact of non-target events in synthetic soundscapes for sound event detection
Sep 28, 2021
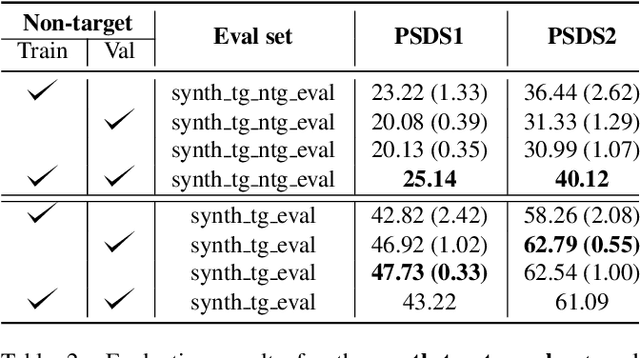


Detection and Classification Acoustic Scene and Events Challenge 2021 Task 4 uses a heterogeneous dataset that includes both recorded and synthetic soundscapes. Until recently only target sound events were considered when synthesizing the soundscapes. However, recorded soundscapes often contain a substantial amount of non-target events that may affect the performance. In this paper, we focus on the impact of these non-target events in the synthetic soundscapes. Firstly, we investigate to what extent using non-target events alternatively during the training or validation phase (or none of them) helps the system to correctly detect target events. Secondly, we analyze to what extend adjusting the signal-to-noise ratio between target and non-target events at training improves the sound event detection performance. The results show that using both target and non-target events for only one of the phases (validation or training) helps the system to properly detect sound events, outperforming the baseline (which uses non-target events in both phases). The paper also reports the results of a preliminary study on evaluating the system on clips that contain only non-target events. This opens questions for future work on non-target subset and acoustic similarity between target and non-target events which might confuse the system.
Limitations of weak labels for embedding and tagging
Feb 13, 2020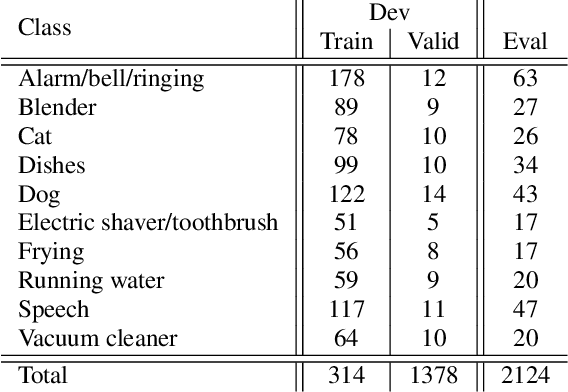
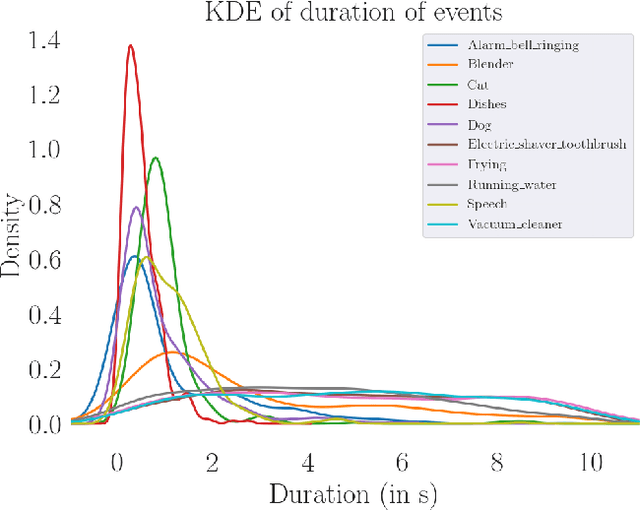
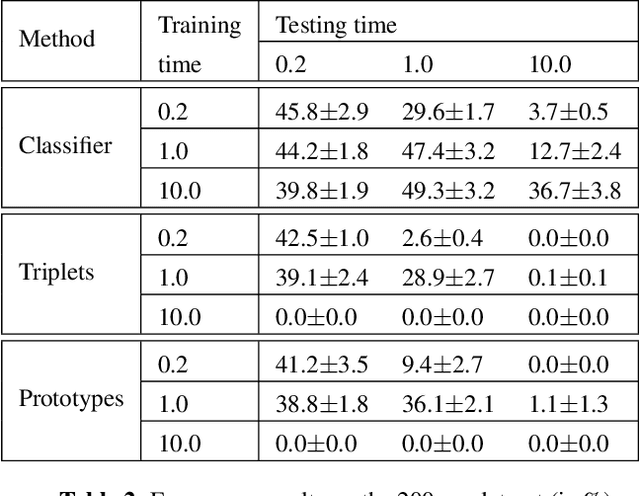
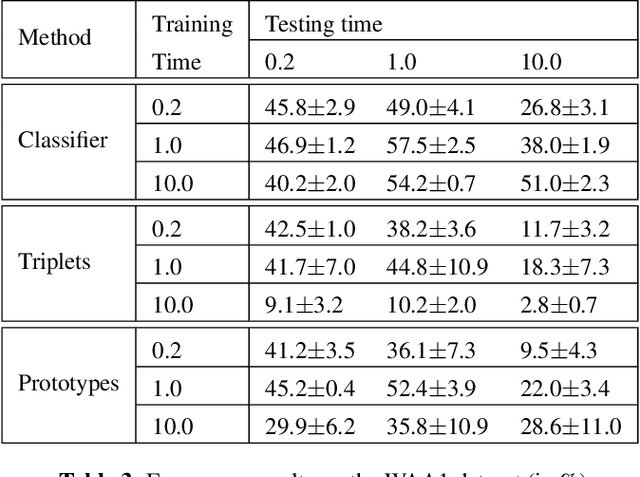
While many datasets and approaches in ambient sound analysis use weakly labeled data, the impact of weak labels on the performance in comparison to strong labels remains unclear. Indeed, weakly labeled data is usually used because it is too expensive to annotate every data with a strong label and for some use cases strong labels are not sure to give better results. Moreover, weak labels are usually mixed with various other challenges like multilabels, unbalanced classes, overlapping events. In this paper, we formulate a supervised problem which involves weak labels. We create a dataset that focuses on difference between strong and weak labels. We investigate the impact of weak labels when training an embedding or an end-to-end classi-fier. Different experimental scenarios are discussed to give insights into which type of applications are most sensitive to weakly labeled data.